
Java学习笔记【持续更新】
一个简单的java程序如下:
class Sakura
{
public static void main(String[] arges)
{
system.out.println("Hello World");
system.out.print("hahaha");
}
}
1.主函数的出现可以保证一个类的独立运行的能力
2.在java程序中,pirnt与println的区别在于println输出一行之后是否再打印一个回车换行,而print则没有!
我们以后缀名为123.java为例,进行java源文件的解析:
我们存放123.java的地址在D:/day1>
此时我们只要输入javac 123.java,在指定文件夹处立刻会生成一个class文件,如下:

发现了没有,class文件的前缀名是Sakura,说明class的名称是自定义的,在这里,我解释一下
javac->原名为java compilation(java语言编辑器),通过javac对源文件进行编译的话,会生成指定的class源文件,java只能去运行class的源文件
我们该如何去运行这个文件呢?
在D:\day1>输入java Sakura.class/java Salura,运行结果如下:
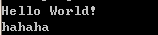
java命令相当于去执行该class文件,而这里我们可以省略.class后缀,是因为java只能去执行class的源文件,所以不需要去特意注明这一点!
java也相当于启动虚拟机文件,去执行该class文件,就到指定的文件夹去执行.class,使它进内存
初学者常犯的错误:
1.


发现问题了嘛,123.java是文本文件
你也可以通过cmd->dir去查询,发现该文件是txt文件

所以要对文件进行设置:

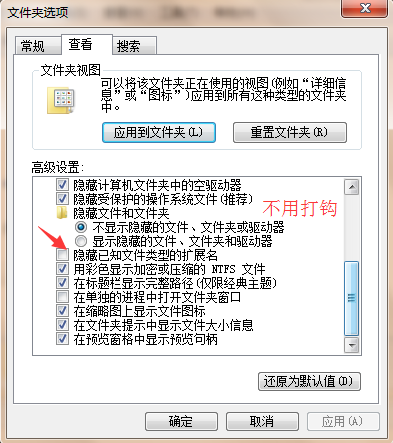
再点击确定即可!
2。运行文件在哪,我就去哪里运行,其实简单解释就是class文件在哪,我们在哪里运行!
3.我们想在任何路径下执行该文件时,我们应该将该文件执行目录告诉给Path路径,由Windows帮我们去找可执行的文件

负数的二进制等于这个数的正数的二进制取反+1,凡是负数,它的二进制的最高位是1
十进制转化为二进制的方法:
将十进制的整数部分不断地除以2,并且记下余数,直到商为0为止。
如N=117D(D代表十进制数)
117/2=58(1)
58/2=29(0)
29/2=14(1)
14/2=7(0)
7/2=3(1)
3/2=1(1)
1/2=0(1)
N=1110101B(B代表2进制数)
BF3CH(H代表十六进制)
2324O(O代表八进制)
左移几位就等于乘上2的多少次方,右移几位等于除以2的多少次方
ctrl+c结束控制台打印
2017.8.11
1.特殊情况:
功能没有具体的返回值,这时return的后面直接用分号结束
返回值类型怎么体现呢,因为没有具体值,所以不可以写具体的数据类型
在java中只能用一个关键字来表示这种情况,关键字就是void
总结:在没有具体返回值的情况下,返回值类型用void来表示!
2.注意:如果返回值类型为void,那么函数中的return语句可以省略不写。
2017.8.15
类与对象的关系:
类是事物的描述,对象是该事物的实例
面向对象:用java语言对现实中的生活事物进行描述,通过类的形式来体现的
怎么描述呢?对于事物描述通常只关注两方面:一个是属性,一个是行为,只要明确该事物的属性和行为并定义在类中即可!
类与对象的关系:
类:事物的描述
对象:该类事物的实例,在java语言中通过new来创建的!
2017.8.16
构造函数:构造创建对象时调用的函数,可以给对象进行初始化操作
一个类中如果没有定义过构造函数,那么该类中会有一个默认的空参数构造函数
如果在类中定义了指定的构造函数,那么类中的默认构造函数就没有了
构造函数:对象创建时,就会调用与之对应的构造函数,对对象进行初始化操作
一般函数:对象创建后,需要函数功能时才调用
构造函数:对象创建时,会调用只调用一次
一般函数:对象创建后,可以被调用多次
什么时候定义构造函数呢?
在描述事物时,该事物已存在就具备的一些内容,这些内容都定义在构造函数中
构造函数可以有多个,用于对不同的对象进行针对性的初始化
多个构造函数在类中是以重载的形式来体现的
当成员变量和局部变量重名,可以用关键字this来区分
this:代表对象,代表哪个对象呢?当前对象
this就是所在函数所属对象的引用
简单说:哪个对象调用了this所在的函数,this就代表哪个对象
static的特点:
1.static是一种修饰符,用于修饰成员
2.static修饰的成员被所有的对象所共有
3.static优先于对象存在,因为static的成员随着类的加载就已经存在了
4.static修饰的成员多了一种调用方式,就可以直接被类名所调用,类名.静态变量
5.static修饰的数据是共享数据,对象中的存储是特有数据
成员变量与静态变量的区别:
1.两个变量的生命周期不同
成员变量随着对象的创建而存在,随着对象的回收而释放
静态变量随着类的加载而存在,随着类的消失而消失
2.调用方式不同:
成员变量只能被对象调用;
静态变量可以被对象调用,还可以被类名调用
3.别名不同:
成员变量也称为实例变量
静态变量称为类变量
4.数据存储位置不同
成员变量数据存储在堆内存的对象中,所以也叫对象的特有数据
静态变量数据存储在方法区(共享数据区)的静态区,所以也叫对象的共享数据
静态使用的注意事项:
1.静态方法只能访问静态成员,(非静态既能访问静态,又可以访问非静态)
2.静态方法中不可以使用this或者super关键字
3.主函数是静态的
public:因为权限必须是最大的
static:不需要对象的,直接用主函数所属类名调用即可
void:主函数没有具体的返回值
main:函数名,不是关键字,只是一个jvm识别的固定的名字
String[] args:这个是主函数的参数列表,是一个数组类型的参数,而且元素都是字符串类型
静态什么时候用:
1.静态变量;
当分析对象中所具备的成员变量的值都是相同的,这时这个成员就可以被静态修饰
只要数据在对象中都是不同的,就是对象的持有数据,必须存储在对象中,是非静态的
如果是相同的数据,对象不需要做修改,只需要使用即可,不需要存储在对象中,定义成静态的
2.静态函数:
函数是否用静态修饰,就参考一点,就是该函数功能是否有访问到对象中的特有数据
简单点说,从源代码看该功能是否需要访问非静态的成员变量,如果需要,该功能就是非静态的
如果不需要,就可以将该功能定义成静态的,当然也可以定义成非静态的
但是非静态需要被对象调用,而仅创建对象调用非静态的
没有访问特有数据的方法,该对象的创建是没有意义的
静态代码块:
随着类的加载而执行,而且只执行一次
作用:
用于给类进行初始化
构造代码块:、
可以给所有对象进行初始化,而构造函数是给对应的对象进行针对性的初始化
8.18
该类的方法都是静态的,所以该类是不需要的创建对象的,为了保证不让其它成创建该类对象,可以将构造函数私有化
必须对于多个程序使用同一个配置信息对象时,就需要保证该对象的唯一性。
如何保证对象的唯一性呢?
1.不允许其它程序用new创建该类对象
2.在该类创建一个本类实例
3.对外提供一个方法让其它程序可以获取该对象
步骤:
1.私有化该类构造函数
2.通过new在本类中创建一个本类对象
3.定义一个公有的方法,将创建的对象返回
8.20
继承的好处:
1.提高了代码的复用性
2.让类与类之间产生了关系,给第三个特征多态提供了前提
java中支持单继承,不直接支持多继承,但对C++中的多继承机制进行了改良,在java中变成了多实现,一个类可以实现多个接口
单继承:一个子类只能有一个直接父类
多继承:一个子类可以有多个直接父类(java中不允许,进行改良)
不直接支持,因为多个父类中有相同成员,会产生调用不确定性
java支持多层(多重)继承
C继承B,B继承A,就会出现继承体系
当要使用一个继承体系时,
1.查看该体系中的顶层类,了解该体系的基本功能
2.创建体系中的最子类对象,完成功能的使用
什么时候定义继承?
当类与类之间存在所属关系的时候,就定义继承,xxx是yyy中的一种,xxx extends yyy
所属关系是:is a关系
当本类的成员和局部变量同名用this区分
当子父类中的成员变量同名用super区分父类
this和super的用法很相似
this:代表一个本类对象的引用
super:代表一个父类空间
成员函数:
当子父类中出现成员函数一模一样的情况,会运行子类的函数,这种现象称为覆盖操作,这是函数在子父类中的特性
函数的两个特性:
1.重载:同一个类中
2.覆盖:子类中,覆盖也称为重写,覆写。override
覆盖注意事项:
1.子类方法覆盖父类方法时,子类权限必须大于等于父类的权限
2.静态只能覆盖静态,或者被静态覆盖
什么时候使用覆盖操作
但对一个类进行子类的扩展时,子类需要保留父类的功能声明
但是要定义子类中该功能的特有内容,就使用覆盖操作完成
2017.8.21
子父类中的构造函数的特点:
在子类构造对象时,发现,访问子类构造函数时,父类也运行了。
为什么呢?
原因是,在子类的构造函数中第一行有一个默认的隐式语句:super()
子类的实例化过程:子类中所有的构造函数默认都会访问父类中的空参数的构造函数
为什么子类实例化的时候要访问父类中的构造函数呢?
那是因为子类继承了父类,获取到了父类中的内容(属性),所以在使用父类内容之前,要先看父类是如何对自己的内容进行初始化的。
所以子类在构造对象时,必须访问父类中的构造函数
为什么完成这个必须的动作?就在子类的构造函数中加入了super()语句
如果父类中没有定义空参数构造函数,那么子类的构造函数必须用super来明确要调用父类中哪个构造函数,同时子类构造函数中如果使用this调用了本类构造函数时,
那么super就没有了,因为super和this都只能定义第一行,所以只能有一个,但是可以保证的是,子类中肯定会有其它的构造函数访问父类的构造函数
注意:super语句必须要定义在子类构造函数的第一行,因为父类的初始化动作要先完成
通过super初始化父类内容时,子类的成员变量并未显示初始化,等父类super()初始化完毕后,才进行子类的成员变量显示初始化
一个对象实例化过程:
Person p=new Person();
1.JVM会读取指定的路径下的Person.class文件,并加载进内存
并会先加载Person的父类(如果有直接的父类的情况下)
2.在堆内存中开辟空间,分配地址
3.并在对象空间中,对对象的属性进行默认初始化操作,
4.调用对应的构造函数进行初始化
5.在构造函数中,第一行会先到调用父类中构造函数进行初始化
6.父类初始化完毕后,再对子类的属性进行显示初始化
7.再进行子类构造函数的特定初始化
8.初始化完毕后,将地址值赋值给引用变量
继承弊端:打破了封装性
final关键字:
1.final是一个修饰符,可以修饰类,方法,变量
2.final修饰的类不可以被继承
3.final修饰的方法不可以被覆盖
4.final修饰的变量是一个常量,只能赋值一次
为什么要用final修饰变量,其实在程序如果只有一个数据是固定的,那么直接使用这个数据就可以了,但是这样阅读性差,所以它给数据起个名称
而且这个变量名称的值不能变化,所以加上了final固定
写法规范:常量所有字母都大写,多个单词,中间用_连接
抽象类的特点:
1.方法只有声明没有实现时,该方法就是抽象方法,需要被abstract修饰,抽象方法必须定义在抽象类中,这类必须也被abstract修饰
2.抽象类不可以被实例化,为什么呢?因为调用抽象方法没意义
3.抽象类必须有其子类覆盖了所有的抽象方法后,该子类才可以实例化,否则,这个子类还是抽象类
1.抽象类有构造函数嘛?
有,用于给子类对象进行初始化。
2.抽象类可以不定义抽象方法嘛?
可以的,但是很少见,目的就是不让该类创建对象,AWT的适配器对象就是这种类,通常这个类中的方法有方法体,但是却没有内容
3.抽象关键字不可以与哪些关键字共存?
private不行
static不行
final不行
4.抽象类和一般类的异同点
相同点:抽象类和一般类都是用来描述事物的,都在内部定了成员
不同点:
- 一般类有足够的信息描述事物,抽象类描述的信息有可能不足
- 一般类不能定义抽象方法,只能定义非抽象方法,抽象类可以定义抽象方法,同时也可以定义非抽象方法
- 一般类可以被实例化,抽象类不可以被实例化
5.抽象类一定是个父类嘛?
是的,因为需要子类覆盖其方法后才可以对子类实例化
当抽象类中的方法都是抽象的时候,这时可以将该抽象类用另一种形式定义和表示,就是接口interface
定义接口使用的关键字不是class,而是interface
对于接口中常用的成员,而且这些成员都有固定的修饰符
1.全局常量:public static final
2.抽象方法:public abstract
由此得出结论:接口中的成员都是公共的权限
类与类之间是继承关系,类与接口之间是实现关系
接口不可以实例化,只能由实现了接口的子类并覆盖了接口中所有的抽象方法后,该子类才可以实例化,否则这个子类就是抽象类
一个类在继承另一个类的同时,还可以实现多个接口
接口的出现避免了单继承的局限性
接口与接口之间是继承关系,而且接口可以多继承
抽象类和接口的异同点:
相同点:
都是不断向上抽取而来的
不同点:
1.抽象类需要被继承,而且只能单继承,接口需要被实现,而且可以多实现
2.抽象类中可以定义抽象方法和非抽象方法,子类继承后,可以直接使用非抽象方法,接口只能定义抽象方法,必须由子类去实现
3.抽象类的继承:是is a关系,在定义该体系的基本共性内容
接口的实现是like a关系,在定义体系的额外功能
2017.8.24
对象的多态性简单来讲就是一个对象对应着不同类型
多态在代码中的体现:
父类或接口的引用指向其子类的对象
多态的好处:
提高了代码的扩展性,前期定义的代码可以使用后期的内容
多态的弊端:
前期定义的内容不能使用(调用)后期子类的特有内容
多态的前提:
1.必须有关系,继承,实现
2.要有覆盖
举个例子:猫属于动物,此时我们定义Animal a=new cat();,自动类型提升,猫对象提升了动物类型,但是特有功能无法访问,作用就是限制对特有功能的访问
专业讲是向上转型,对子类型隐藏,就不用使用子类的特有方法
如果如果你还想用具体动物猫的特有功能,你可以将该对象进行向下转型,Cat c=(Cat)a;
向下转型是为了使用子类中的特有方法
注意:对于转型,自始自终都是子类对象在做着转型的变化
instanceof,用于判断对象的具体类型,只能用于引用数据类型判断,通常在向下转型前用于健壮性的判断
多态时成员的特点:
1.成员变量:
编译时,参考引用型变量所属的类中是否有调用的成员变量,有,编译通过,没有,编译失败
运行时,参考引用型变量所属的类中是否有调用的成员变量,并运行该所属类中的成员变量
简单说,编译和运行都参考等号的左边,哦了!作为了解
2.成员函数:
编译时,参考引用型变量所属的类中是否有调用的函数,有,编译通过,没有,编译失败
运行时,参考的是对象所属的类中是否有调用的函数
简单说,编译看左边,运行看右边
3.静态函数:
编译时,参考引用型变量所属的类中是否有调用的静态方法
运行时,参考引用型变量所属的类中是否有调用的静态方法
简单说,,编译和运行都看左边
其实对于静态方法,是不需要对象的,直接用类名调用即可
内部类访问特点:
1.内部类可以直接访问外部类中的成员
2.外部类要访问内部类,必须建立内部类的对象
一把用于类的设计
分析事物时,发现该事物描述中还有事物,而且这个事物还在访问被描述事物的内容,这时就是还有的事物定义成内部类来描述
直接访问外部类中的内部类中的成员
如果内部是静态的,相当于一个外部类
如果内部类是静态的,成员是静态的
如果内部类中定义了静态成员,该内部类也必须是静态的
为什么内部类能直接访问外部类中的成员呢?
那是因为内部类持有了外部类的引用, 外部类名.this
举例:
1 class Outer 2 { 3 int num=3; 4 class Inter 5 { 6 int num=4; 7 void show() 8 { 9 int num=5; 10 System.out.println(num);//5 11 System.out.println(this.num);//4 12 System.out.println(Outer.this.num);//3 13 } 14 } 15 void method() 16 { 17 new Inter().show(); 18 } 19 } 20 21 class Interclass 22 { 23 public static void main(String[] args) 24 { 25 new Outer().method(); 26 } 27 }
内部类可以存放在局部位置上
内部类在局部位置上只能访问局部中被final修饰的局部变量
2017/8/25
匿名内部类:就是内部类的简写格式
必须有前提,内部类必须继承或实现一个外部类或者接口
匿名内部类,其实就是匿名一个子类对象
格式:new 父类或者接口(){子类内容}
通常的使用场景之一:
当函数参数是接口类型时,而且接口中的方法不超过3个,可以用匿名内部类作为实际参数进行传递
举个例子:
1 class Fu 2 { 3 int num=9; 4 { 5 System.out.println("Fu");//1 6 } 7 Fu() 8 { 9 super(); 10 //显示初始化 11 //构造代码块初始化 12 System.out.println("Fu constructor run");//2 13 show(); 14 } 15 void show() 16 { 17 System.out.println("Fu show..."+num); 18 } 19 } 20 21 class Zi extends Fu 22 { 23 int num=8; 24 { 25 System.out.println("constructor code..."+num);//4 26 num=10; 27 } 28 Zi() 29 { 30 super(); 31 //显示初始化 32 //构造代码块初始化 33 System.out.println("Zi constructor..."+num);//5 34 } 35 void show() 36 { 37 System.out.println("Zi show..."+num);//3 38 } 39 } 40 41 class Test 42 { 43 public static void main(String[] args) 44 { 45 new Zi(); 46 } 47 }
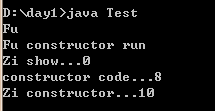
2017.8.28
异常:是在运行时期发生的不正常情况。。。。
在java中用类的形式对不正常情况进行了描述和封装对象
描述不正常的情况的类,就称为异常类
以前正常流程代码和问题处理代码相结合,现在将正常流程代码和问题处理代码分离,提高阅读性
其实异常就是java通过面向对象的思想将问题封装成了对象
2017.9.3
问题很多,意味着描述的类也很多
将其共性进行向上抽取,形成了异常体系
最终问题(不正常情况)就分成了两大类
Throwable:无论是error,还是异常,问题,问题发生就应该可以抛出,让调用者知道并处理
//该体系的特点就是在于Throwable及其所有的子类都具有可抛性。
可抛性到底指的是什么呢?怎么体现可抛性呢?
其实是通过两个关键字来体现的。
throws,throw,凡是可以被这两个关键字所操作的类和对象都具备可抛性
|--1,一般不可处理:Error
特点:是由jvm抛出的严重性的问题
这种问题发生一般不针对性处理,直接修改程序
|--2,可以处理的,Exception
该体系的特点:
子类的后缀名都是用其父类名作为后缀,阅读性很强
2017/9/15
对于角标是整数不存在,可以用角标越界表示,对于负数为角标的情况,准备用负数角标异常来表示
负数角标这种异常在java中并没有定义过,那就按照java异常的创建思想,面向对象,将负数角标进行自定义描述,并封装成对象,
这种自定义的问题描述成为自定义异常
注意:如果让一个类称为异常类,必须要继承异常体系,因为只有称为异常体系的子类才有资格具备可抛型,才可以被两个关键字所操作,throw,throws
异常的分类:
1.编译时被检测异常:只要是Expecetion和其子类都是除了特殊子类RuntimeExpection体系
这样的问题一旦出现,希望在编译时就进行检测,让这种问题有对应的处理方式,这样的问题都可以针对性的处理
2.编译时不监测异常(运行时异常):就是Expection中的RuntimeExpection和其子类这种问题的发生,无法让功能继续,运算无法进行,
更多的是因为调用者的原因导致的而或者引发了内部状态的改变而导致的,那么这种问题一般不处理,直接编译通过,在运行时,让调用者调用时的程序强制停止,
让调用者对代码进行修正
所以自定义异常时,要么继承Expection,要么继承RuntimeExpection。
throws和throw的区别:
1.throws是使用在函数上,throw使用在函数内
2.throws抛出的是异常类,可以抛出多个,用逗号隔开,throw抛出的是异常对象
异常处理的捕捉形式:
这是可以对异常进行针对性处理的形式,具体格式为:
try
{
//需要被检测的异常代码
}
catch()
{
//处理异常的代码
}
finally
{
//一定会被执行的代码
}
异常处理的原则:
1.函数内容如果抛出需要检测的异常,那么函数上必须要申明,否则必须在函数内用try,catch捕捉,否则编译失败
2.如果调用到了申明异常的函数,要么try,catch,要么throws,否则编译失败
3.什么时候用catch,什么时候用throws呢?
功能内容可以解决,用catch
解决不了,用throws告诉调用者,由调用者解决
4.一个功能如果抛出了多个异常,那么调用时,必须有对应多个catch进行针对性的处理
内部有几个需要检测的异常,就抛出几个异常,抛出几个,就catch几个
1 class Demo 2 { 3 public int show(int index)throws ArrayIndexOutOfBoundsException 4 { 5 if(index<0) 6 throw new ArrayIndexOutOfBoundsException("run bat"); 7 int[] arr=new int[3]; 8 return arr[index]; 9 } 10 } 11 class Angel_Kitty 12 { 13 public static void main(String[] args) 14 { 15 Demo d=new Demo(); 16 try//需要被检测的异常代码 17 { 18 int num=d.show(-1); 19 System.out.println("num="+num); 20 } 21 catch(ArrayIndexOutOfBoundsException e)//处理异常代码 22 { 23 System.out.println(e.toString()); 24 // return;//不会执行打印输出"over"这一行 25 // System.exit(0);//退出JVM,在这里就已经结束了,finally和打印输出"over"这一行均不执行 26 } 27 finally//一定会被执行的代码 28 { 29 System.out.println("finally"); 30 } 31 System.out.println("over"); 32 } 33 } 34 /** 35 连接数据库 36 查询 Expection 37 关闭连接 38 */ 39 40 /** 41 try catch finally组合特点 42 */ 43 44 /** 45 1.try catch finally 46 */ 47 48 /** 49 2.try catch(多个)当没有必要资源需要释放时,可以不用定义finally 50 */ 51 52 /** 53 3.try finally 异常无法直接catch处理,但是资源需要关闭 54 */ 55 56 /** 57 有catch就不需要去throws声明,没有必须要去声明throws 58 */
2017/9/25
异常的注意事项:
1.子类在覆盖父类方法时,父类的方法如果抛出了异常,那么子类的方法只能抛出父类得异常或者该异常的子类。
2.如果父类抛出多个异常,那么子类只能抛出父类异常的子集。
简单说:子类覆盖父类只能抛出父类的异常或者子类或者子集。
注意:如果父类的方法没有抛出异常,那么子类覆盖时绝对不能抛。
2017/10/25
面向对象:包与包之间访问
总结:包与包之间的类进行访问,被访问的包中的类必须是public的,被访问的包中的类的方法也必须是public的
权限:
public protected default private
同一类中 ok ok ok ok
同一包中 ok ok ok
子类中 ok ok
不同包中 ok
导包的原则:用到哪个类就导入哪个类
import packa.DemoA;//导入了packa包中的DemoA类
import packa.*;//导入了packa包中所有的类
packa\DemoA.class
packa\abc\DemoAbc.class
import packa.abc.*;//导入了packa包中子包abc下的所有的类
import是为了简化类的书写
Jar:java的压缩包
2017/10/26
进程:正在进行中的程序(直译)
线程:就是进程中一个负责程序执行的控制单元(执行路径)
一个进程中可以多执行路径,称为多线程
一个进程当中至少要有一个线程
开启多个线程是为了同时运行多部分代码
每一个线程都有自己运行的内容,这个内容可以称为线程要执行的任务
多线程好处:解决了多部分同时运行的问题
多线程的弊端:线程太多回到效率的降低
其实应用程序的执行都是cpu在做着快速的切换完成的,这个切换是随机的
JVM启动时就已经启动了多个线程,至少两个线程可以分析的出来
1.执行main函数的线程
该线程的任务代码都定义在main函数中
2.负责垃圾回收的线程
如何创建一个线程呢?
创建线程方式一:继承Thread()
1.定义一个类继承Thread类
2.覆盖Thread类中的run方法
3.直接创建Thread的子类对象创建线程
4.调用start方法开启线程并调用线程的任务run方法执行
可以通过Thread的getName获取线程的名称,Thread-编号(从0开始)
主线程的名称就是main
创建线程的目的是为了开启一条执行路径,去运行指定的代码和其它代码实现同时运行
而运行指定代码就是这个执行路径的任务
jvm创建的主线程的任务都定义在了主函数中,而自定义的线程它的任务又在哪儿呢?
Thread类用于描述线程,线程是需要任务的,所以Thread类也是对任务的描述,这个任务就通过Thread类中的run方法来体现,也就是说,run方法就是封装自定义线程运行任务的函数
run方法中定义就是线程要运行的任务代码
开启线程是为了运行指定代码,所以只有继承Thread类,并复写run方法,将运行的代码定义在run方法中即可
作 者:Angel_Kitty
出 处:https://www.cnblogs.com/ECJTUACM-873284962/
关于作者:阿里云ACE,目前主要研究方向是Web安全漏洞以及反序列化。如有问题或建议,请多多赐教!
版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。
特此声明:所有评论和私信都会在第一时间回复。也欢迎园子的大大们指正错误,共同进步。或者直接私信我
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是作者坚持原创和持续写作的最大动力!
欢迎大家关注我的微信公众号IT老实人(IThonest),如果您觉得文章对您有很大的帮助,您可以考虑赏博主一杯咖啡以资鼓励,您的肯定将是我最大的动力。thx.

我的公众号是IT老实人(IThonest),一个有故事的公众号,欢迎大家来这里讨论,共同进步,不断学习才能不断进步。扫下面的二维码或者收藏下面的二维码关注吧(长按下面的二维码图片、并选择识别图中的二维码),个人QQ和微信的二维码也已给出,扫描下面👇的二维码一起来讨论吧!!!

欢迎大家关注我的Github,一些文章的备份和平常做的一些项目会存放在这里。

