



结对编程作业--能不能起飞就靠这次了
结对情况
- cool_boy
- 学号:437
- 海辉
- pig_pig
- 旭
- 学号:311
- pig_link---press
项目链接
设计说明
-
类图
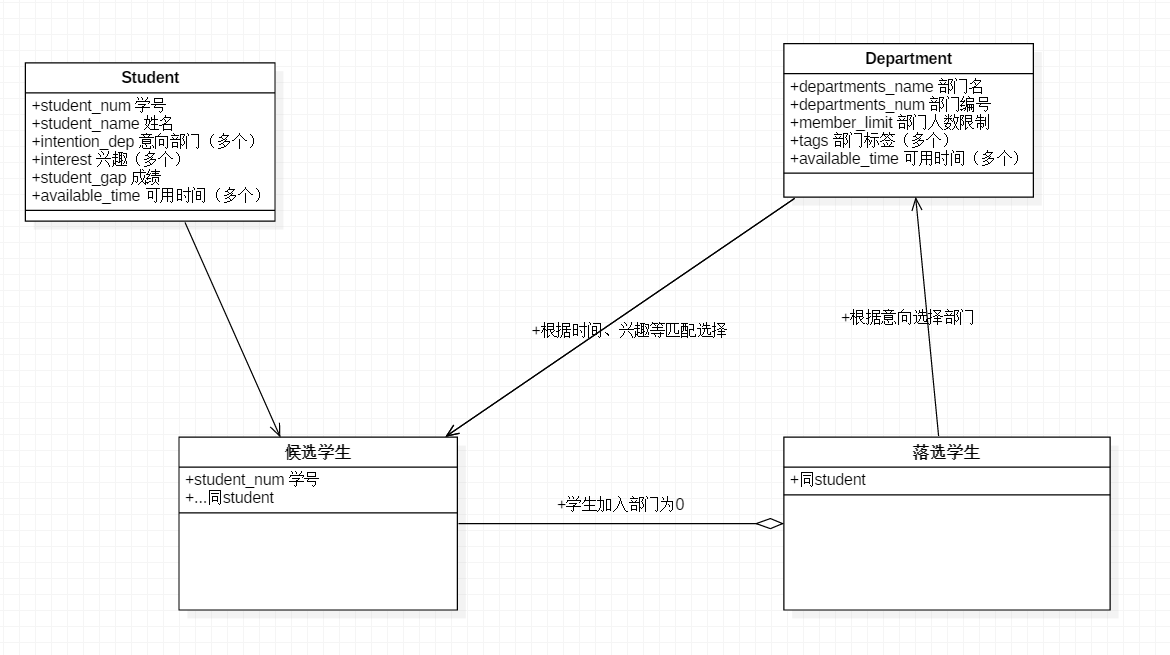
-
API接口设计
public MyC allocate
{
public void Myjson();//读入与处理json数据
public void FDmatching();//实现第一次分配
public void SDmatching();//实现第二次分配
public void TDmatching();//实现第三次分配
public void Prin();//输出
}
-
匹配算法的设计
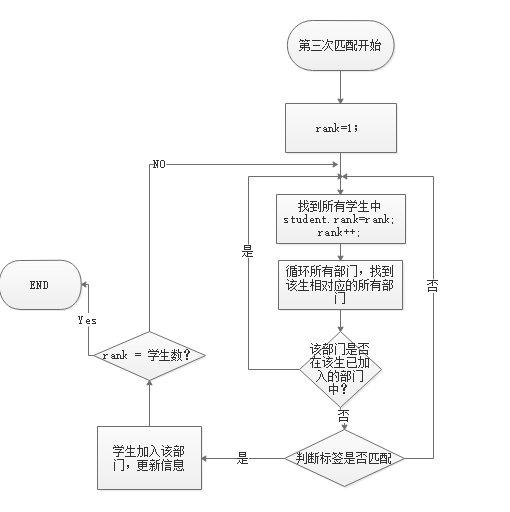
1. 流程图
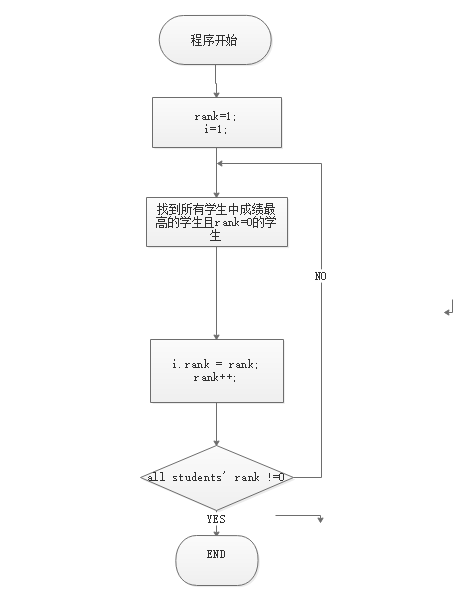
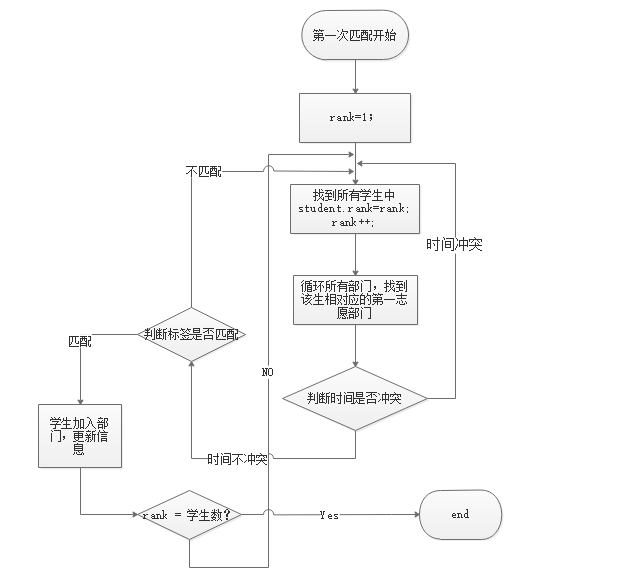
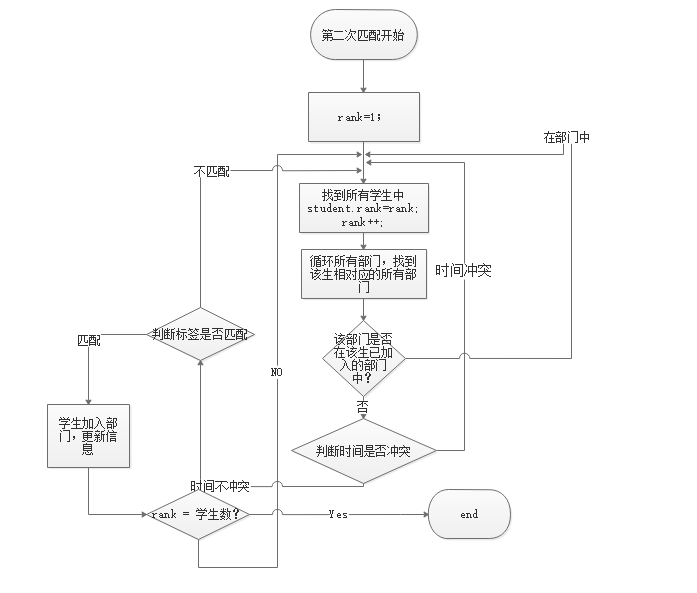
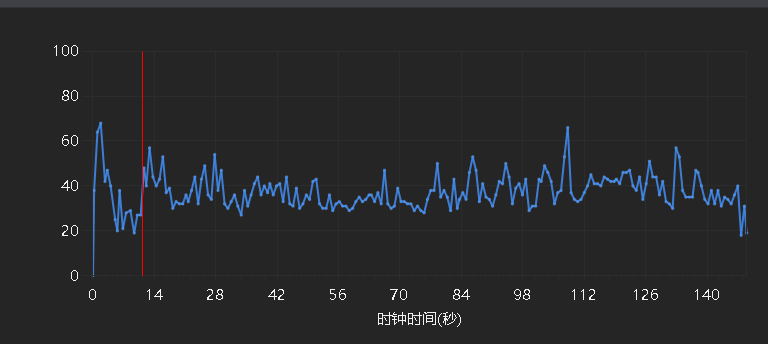
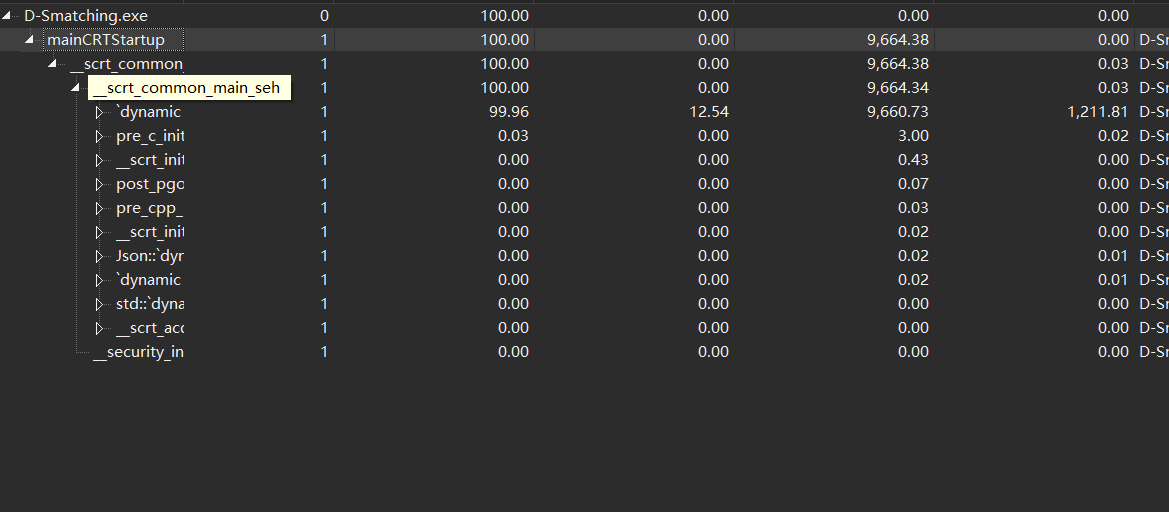
性能分析
-
接下来已s5000-d100为例,先上图
匹配思想
-
Step1:为了不让后生成的学生的优先级过低导致不能进入部门,首先以高考成绩换算成的评分(随机生成)排名,从高到低排名,给每个人一个rank排名。
-
Step2:在第一步的前提下,以第一志愿优先原则:从rank为1的学生开始,遍历其第一志愿,当第一志愿对应的部门的人数没有满的情况下,进行匹配判断,匹配判断分为以下两步:
-
Step 2.1 进行时间判断,将学生的空闲时间段与部门的基础活动时间段进行匹配,当两个时间段中有1个时间段互相匹配(同一时间段或者学生的空闲时间段大于部门的活动时间段),进行下一步判断。
-
Step 2.2 时间判断满足的情况下,进行标签匹配。将学生的兴趣标签与部门的标签进行一一对比,只要其中有两个两两匹配,即满足判断,更新学生信息与部门信息(学生:加入部门信息、加入部门数 部门:成员信息、部门人数、部门人数上限等)
-
Step3 对所有的学生,依旧按照成绩排名,从rank为1的学生开始,遍历其所有志愿,当其志愿对应的部门的人数没有满的情况下,进行匹配判断,匹配判断分为以下两步:同上
-
Step 3.1 进行时间判断,将学生的空闲时间段与部门的基础活动时间段进行匹配,当两个时间段中有1个时间段互相匹配(同一时间段或者学生的空闲时间段大于部门的活动时间段),进行下一步判断。
-
Step 3.2 时间判断满足的情况下,进行标签匹配。将学生的兴趣标签与部门的标签进行一一对比,只要其中有两个两两匹配,即满足判断,更新学生信息与部门信息(学生:加入部门信息、加入部门数 部门:成员信息、部门人数、部门人数上限等)
-
Step 4 最后一轮匹配,对所有的学生,依旧按照成绩排名,从rank为1的学生开始,遍历其所有志愿,当其志愿对应的部门的人数,且学生的已加入部门信息没有该部门没有满的情况下录取。
测试数据如何生成
部门部分
-
部门名(department_name):部门名由事先设定好的字符串,通过随机数的组合进行随机生成,由于在下面学生的意向部门中需要用到部门名,因此先用一个字符串数组先存起来。
-
人数上限(member_limit):单个,数值,在[0,15]内,这是题目要求,但是考虑到部门的实际情况,一个部门不可能纳新人数0人,而且数字比较小,也比较奇怪,因此我们加上底数限制,范围在[10,15]中,实现方法也比较简单,只要通过一个简单的随机程序,在这个区间内随意生成一个数字即可。
-
部门特点标签(tags):首先我们预设9个标签,但是当我们数据测试的时候其实有考虑标签的匹配,如果总标签数少,这一层的匹配率相对来说太高,也就是标签匹配没有发挥作用,因此我们将其扩充到17个,经过测试,效果上有所改善,匹配率下降了2个百分点左右,表明标签匹配发挥了作用。我们的实现方法也比较简单,预取3个目标标签,但是要考虑重复部分,因此在0-16随机生成三个数,经过简单的if去重,得到三个不重复的随机数,作为数组标志,抓取标志。
-
部门常规活动(schedule_time):最初的想法就是星期输与时间数的随机匹配,时间是控制在10点到23点。这是符合实际情况的,部门工作有一块很重要的内容就是值班,因此需要安排每个时间段都需要人值班,因此部门活动时间是一个跨度比较大的范围。实现方法也是,星期数是预存数组的随机,时间则是在10-21点随机一个数字,后一个是加上2,表示成字符串。
学生部分
-
学生姓名(student_name):原先采取和部门名一样的生成方法,生成一个乱码的字母组合来表示,后来可能觉得蛋疼,太蠢了!于是觉得做一点合乎常理的事,名字嘛,就该有正常的姓和名。于是做了三个姓和名的数组,全是将我们班级的人的姓,慢慢打入,还有所有名字拆成两个字,考虑到最终有5000个,因此每个数组分别20、35、38个,总数20 * 35 * 38 > 5000,即直接投入使用。当然会考虑到重复的问题,在下面的模块会简单阐述。
-
学号(student_number):作为一个并没有很大影响的标识(因为在名字设立板块采取去重,即无重复名字,因此名字可作为唯一标识),学号这块就主要是0315+8位的随机数组成学号,0315表示数计学院15级学生,也是有良好的寓意的。
-
兴趣标签(Interests):本块内容与部门部分的标签相似,不做累赘说明。
-
绩点(gap):绩点这块实现难度上就不说了,比较简单,谈谈实际情况。由于福州大学今年绩点改革,因此我们决定跟上潮流,才取阶梯制加上十分制,比如87分、80分和85分的绩点都算作9,65分和60分绩点都算作6.0,也就是不再是一分一绩点,而是一段一绩点的形式。
-
意向部门(intention_dep):这一块内容也比较简单,将部门生成名字时存入的数组进行调用,随机产生三个不同的该范围内的随机场,进行调取部门。
-
可用时间(available_time):最初的想法和部门常规活动时间一样,最终改变的原因主要有两个,一个是匹配的问题,因为时间以段为单位,在时间生成上产生了11*7=77种可能性,再加上部门和学生的可用时间需要三个标签最终进行匹配,导致匹配率极低;第二个是实际情况,如工作日的10点-17点,很明显是属于学生的学习时间,不太可能将部门活动时间定在这个时间段,正常的可用活动时间段应该控制在工作日的晚上19点-23点,以及周末的一整天,实现方法是在部门的简单随机上,加了两个if的判断,即可实现。
-
如何评价匹配算法
咳咳,算法方面一定要自我检讨一下了,因为匹配算法是自己写的。算法只考虑了匹配过程的可执行性,在复杂度方面没有做过多的考虑,甚至出现了三层嵌套for循环的情况,结果就是导致在最大的5000students、100departments时,要30几秒才能完成运行,每次都等得自己要疯,队友要打人。对不起队友,对不起老师,对不起国家。。。。。。
(attention)
以上来自写匹配的队友,那我也评价一下,写最终的生成的时候,当时只留了一个5000的数据,每一次改完都是等待1分钟,要抓狂。但是经过问其他同学之后,也有部分同学的复杂度达到了n^3,想想心里平衡了一些。由于我们的匹配算法都是简单的暴力枚举,用最蠢的办法干最酷的事,这也是我们所想或者说能力范围内,当然很多优秀的算法仍然需要我们去学习,希望这个周期不要太长。
关键代码解释
- 随机生成部分
const char CDH[] = "0123456789";
string form_dnum()//生成部门编号
{
char ch[nSIZE_CHAR + 1] = { 0 };
for (int i = 0; i < nSIZE_CHAR; ++i)
{
int x = rand() / (RAND_MAX / (sizeof(CDH) - 1));
ch[i] = CDH[x];
}
return ch;
}
这是一段普通的随机数生成程序,全是整个程序的基础,代码比较简单不做过多的复述,但是有个不同,
int x = rand() % (sizeof(CCH) - 1);
这个方法不好, 因为许多随机数发生器的低位比特并不随机,虽然没有太理解这句话,但是听起来很厉害,于是采用上面那种方法。RAND MAX 在ANSI 里#define 在<stdlib.h>
RAND MAX 是个常数, 它告诉你C库函数 rand() 的固定范围。
详情点击此处。
- 学生名字生成部分
void form_sname(int h)//生成学生姓名
{
int j = 0;
map<string, int> mapStudent;
mapStudent.insert(pair<string, int>("ye haihui", 1));
for (int i = 2; i <= h; i++)
{
int y1 = rand() / (RAND_MAX / (20 - 1));
int y2 = rand() / (RAND_MAX / (35 - 1));
int y3 = rand() / (RAND_MAX / (38 - 1));
string new_name = name_part1[y1] + " " + [y2] + name_part3[y3];
map<int, string>::iterator it;
int w1 = mapStudent.count(new_name);
if (w1 == 0)
{
mapStudent.insert(pair<string, int>(new_name, i));
name[j++] = new_name;
}
else i--;
}
}
这部分的代码主要想说的是map类型的运用,看了很多大佬的hash相关的内容,自愧不如,本部分主要是用于名字生成的去重,先预存一个名字在map中,然后每次随机生成的名字用count进行计数,如果没有,就把这个名字存进去,否则继续随机。对于我来说是个不错的方法,其实仔细一想这个方法有很大的局限性,一个是效率问题,随着基数不断扩大,重复随机的概率将不断提高,假如只剩下一个名字,重复率将无限提升,以目前对map的运用,只能将名字库不断扩大,以增加概率,方法有些取巧,其实并没有从根本上解决这个问题。其次这个方法本质意义上也不叫去重,而是存入无重复的名字。另外曾经尝试过用find函数,可是老是不能成功,看来还需要多多努力。下次将map类型做更深入的理解,同时涉足哈希相关,小白表示压力很大。
- 还有就是json,这个放在遇到的困难里详细谈一下。还有关于匹配算法,主要是队友完成,但是在筛选标准上两人还是进行深入的讨论。
- 参博客考也是唯一可用的,对于我的不知道什么情况的vs2015。
运行及测试结果展示
- 测试500位同学,30个部门的情况
- 测试1000位同学,50个部门的情况
- 测试5000位同学,100个部门的情况
-
输入输出
*测试200位同学,20个部门的情况
- s200-d20
link
本次匹配情况良好,所有部门都收到学生,并依据标签时间等严格条件筛选符合部门特色的学生,符合实际情况。
- s500-d30
link - 所有部门都收到学生,并依据标签时间等严格条件筛选符合部门特色的学生,符合实际情况。
- s1000-d50
link - 所有部门都收到学生,并依据标签时间等严格条件筛选符合部门特色的学生,符合实际情况。
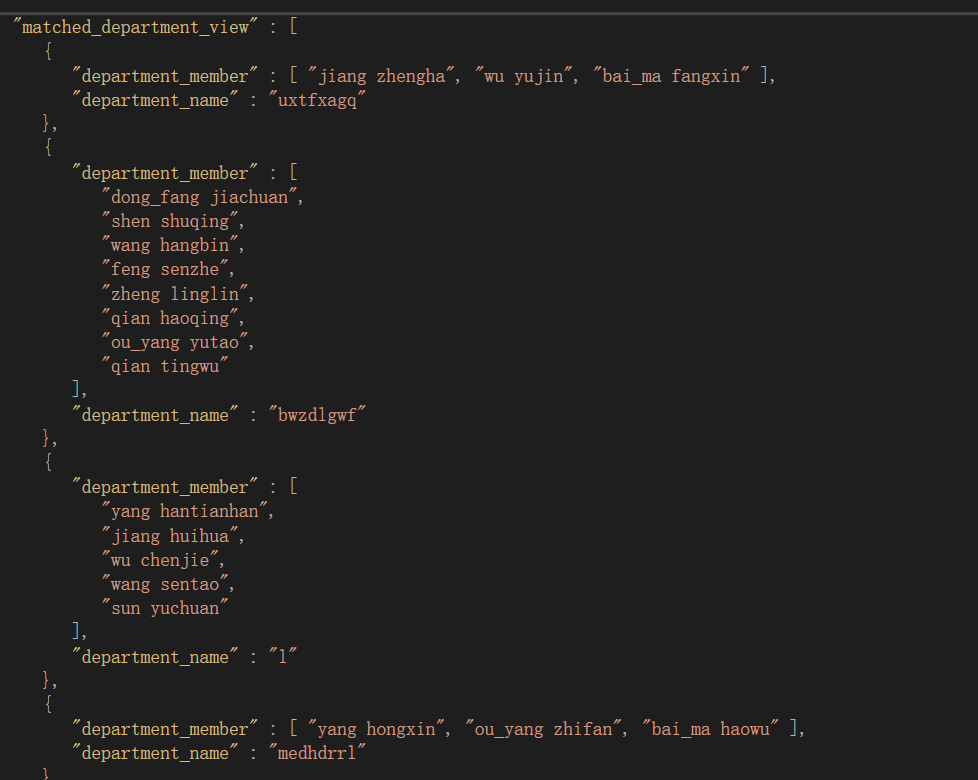
- s5000-d100
link - 所有部门都收到学生,并依据标签时间等严格条件筛选符合部门特色的学生,符合实际情况。生成过程较久,但不影响匹配的成功率,匹配的算法描述上面已有描述。
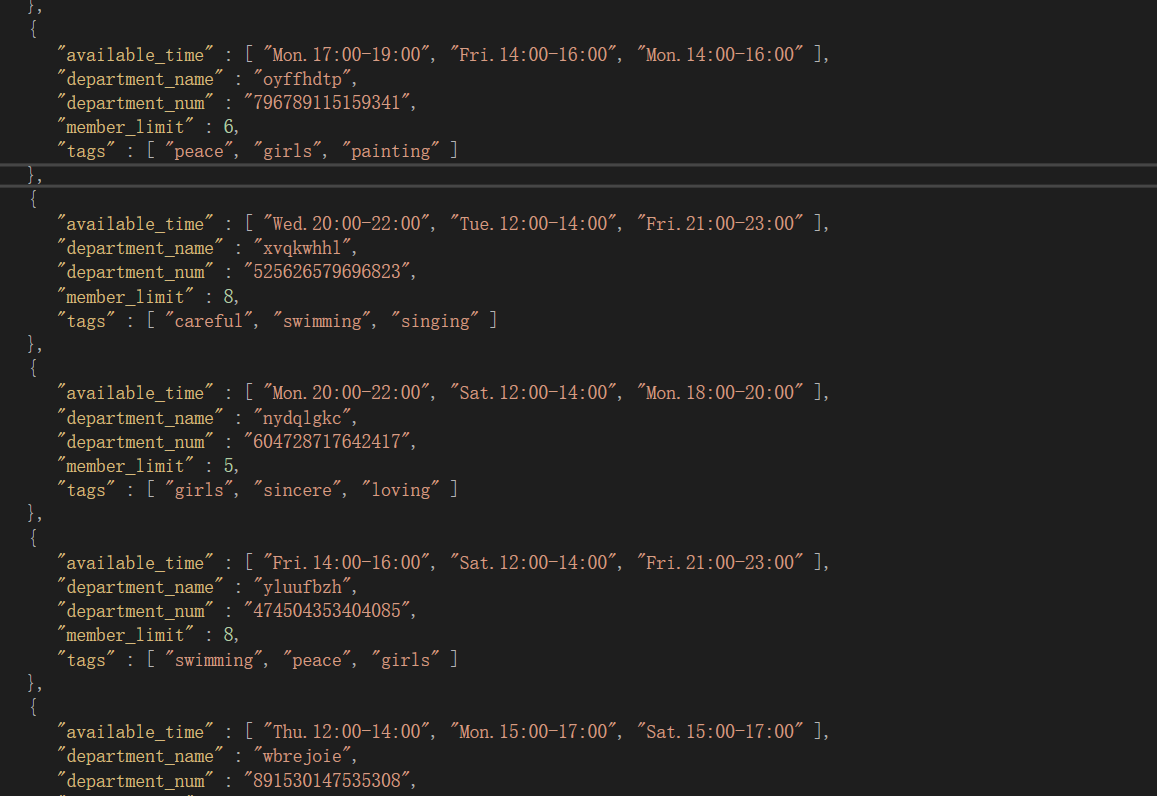
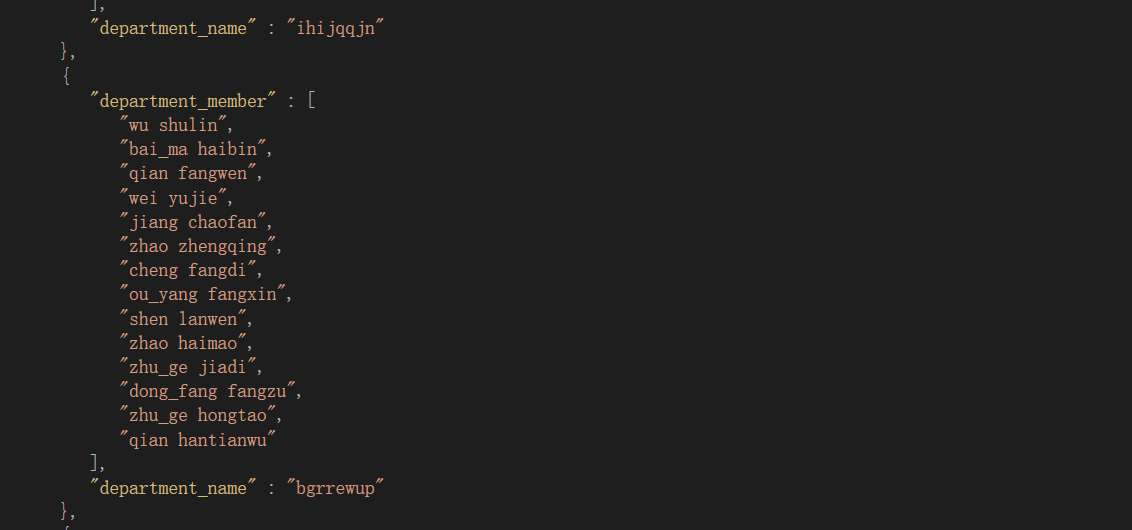
遇到的困难及解决方法
作为生成部分,遇到的困难主要是json的安装、生成两块。
-
困难描述
--首先对json这个东西,以为和txt的输出一样,一直没太注意。某次无聊了百度了一下,咦?好像有那么点内容,再过了几天,准备开始做了,先动手吧,于是按着教程来,喵喵喵? 经过了两天的尝试,竟然毫无进展,当然时间是每天2-3小时的那种。主要问题是不知道问题在哪,整个毫无地方可以入手,三个头文件write、value、read竟然都无法用,一直报各种各样的问题,总之归结起来就是,json.h无法打开,即使打开也无法使用。 -
尝试及解决--这个做了可就多了,不过后期看来并没有多少有意义,后来找到一篇听起来很有道理的博客,于是进行尝试,果真!成功了!他是采用一次性的方法,将头文件手动插入工程,然后json的头文件也是手动插入,相当于每次新建工程都需要从新配置一下,但是配置的过程并不复杂,无需太多精力,能力有限但是头脑简单的我当然选择这个办法了。
-
关于json的理解,其实经过几段代码的实践很好理解,json的输出类似一棵树,先定义一个根节点与各节点,赋值的方式也比较直接,同时配合上数组的运用就可以彻底理解透json的输出格式,在json的读入更是符合这个思想,将json按规矩读入然后存到相应的类中。
Json::Value partner_dep;//部门子节点;
Json::Value root;//根节点
Json::Value students;//学生结点
Json::Value departments;//部门节点
root["students"] = Json::Value(students);
root["departments"] = Json::Value(departments);
Json::Value dep;//部门子节点;
dep["department_num"] = Json::Value(form_dnum());//赋值
root["departments"].append(dep);//数组赋值
//输出到文件
Json::StyledWriter sw;
ofstream os("s5000-d100-in.json", ios::app);
os << sw.write(root);
os.close();
主要的应用如上所示,相信能够很快理解。这也是这次结队编程对于我最大的收获了。同时这次编程有一个更大的收获就是发现自己在这段时间好像变了,对于代码没有原先的那种排斥的感觉,随着熟练度的上升,爱上了研究未知的类和函数,爱上了花一定量的时间专注编程,爱上了运行框上成功运行的快感,仿佛大门被打开了,现在每天都会有意识的去摸索,去编程。这次作业的雏形其实在10.8就完成了,当时以最紧的时间要求自己,后面的天本来想玩耍,但是某次看到自己的代码,真的太蠢了,毫无任何含金量,于是后面的几天开始行动了,将自己的每一部分都尽可能的完善,向舍友请教,有没有更洋气的办法,有没有更好的算法,一次次请教中,了解了map、hash等等用法,也入门级地探索了一波,仿佛有那么点的兴趣。也希望自己在一次次中,找到属于自己的那份热爱。
对队友的评价
(黄旭勿看,价值一顿饭)
如果评价的时间在国庆放假内,那肯定就一个字--坑!2号就在摸索的我,5号他才来学校。来了之后他主要负责匹配的算法的设计,一天他就和我说设计好了,然后我就拿了一组数据给他跑。
炸了!
程序?
不,还有vs!
我的哥,8号下午我在陪他重装!
心里头是******;
某天夜里,1点了,我问他改得怎么样,他说还在改,准备睡了。
***我基本完成了我都还在完善,你还敢早我睡觉。
那天我做到了两点。
但是
也不是都这样的不堪。10月8号以后如果要用一个字来评价,那应该是--切。
如果用三个字--一般般。
五个字--也算还好吧。
后来的两天,不知道是怎的了,他仿佛醒悟了一番,进度特别快,一天后,就做出了一个成品,并且把匹配的算法自行优化了一遍。看着他努力,老夫总算叹了一口气。吾儿终成吾所愿,幸哉!
但是,还没完。。。算了下次再说,毕竟是大作业队友嘛哈哈哈
PSP
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 600 | 600 |
| Development | 开发 | 60 | 60 |
| · Analysis | · 需求分析 (包括学习新技术) | 20 | 200 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 20 | 60 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 300 |
| · Design | · 具体设计 | 120 | 60 |
| · Coding | · 具体编码 | 500 | 600 |
| · Code Review | · 代码复审 | 30 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 100 |
| Reporting | 报告 | 30 | 120 |
| · Test Report | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 40 | 60 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 30 |
| 合计 | 1550 | 2070 |
学习进度表
| 第N周 | 新增代码 | 耗时(小时) | 重要成长 |
|---|---|---|---|
| 第一周 | 100 | 30 | 复习了vs2015,、github、回溯思想 |
| 第二周 | 100 | 30 | 深入了解了github等用法 |
| 第五周 | 500 | 30 | 掌握了json和map的相关用法 |

