
Python3实现机器学习经典算法(二)KNN实现简单OCR
一、前言
1、ocr概述
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即,针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术(摘自百度百科:光学字符识别)。
KNN在OCR的识别过程中能发挥作用的地方在于将图像中的文字转换为文本格式,而OCR的其他部分,比如图像预处理、二值化等操作将其丢给OpenCV去操作。
2、训练集简介
由于我们采用的是KNN来转换图像中的文字为文本格式,需要一个庞大的手写字符训练集来支撑我们的算法。这里我使用的是《机器学习实战》2.3实例:手写识别系统中使用的数据集,其下载地址为:https://www.manning.com/books/machine-learning-in-action,在Source Code\Ch02\digits\trainingDigits中的两千多个手写字符既是我所使用的训练集。
这个训练集配合上它所提供的测试集,提供了一个准确度非常高的分类器:
训练集是由0~9十个数字组成的,每个数字有两百个左右的训练样本。所有的训练样本统一被处理为一个32*32的0/1矩阵,其中所有值为1的连通区域构成了形象上的数字,如下所示:

所以,在构造我们的测试集的时候,所有的手写数字图片必须被处理为这样的格式才能够使得分类算法正确地进行,这也是KNN的局限所在。
二、算法实现
1、构建测试集
上面已经提到,要想算法正确地进行,测试集的样式应该和训练集相同,也就是说我们要把一张包含有手写数字的图像,转换为一个32*32的0/1点阵。
测试集使用我自己手写的10个数字:










这里存在一个非常大的问题:这个数据集的作者是土耳其人,他们书写数字的习惯和我们有诸多不同,比如上面的数字4和数字8,下面这样子的数字就无法识别:4/8。哈哈,也就是说它连印刷体都无法识别,这是这个训练集的一大缺陷之一。
1)图像预处理
图像预处理的过程是一个数字图像处理(DIP)的过程,观察上面的10个数字,可以发现每张图像的大小/对比度的差距都非常大,所以图像预处理应该消除这些差距。
第一步是进行图像的放大/缩小。由于我们很难产生一个小于32*32像素的手写数字图像,所以这里主要是缩小图像:
1 import cv2 2 def readImage(imagePath): 3 image = cv2.imread(imagePath,cv2.IMREAD_GRAYSCALE) 4 image = cv2.resize(image,(32,32),interpolation = cv2.INTER_AREA) 5 return image
这里我没有去实现图像重采样的方法(实现在后面的博客会写),而是采用的OpenCV,通过area来确定取样点的灰度值(推荐用bicubic interpolation,对应的插入函数应该是INTER_CUBIC),在读入图像的时候读入方式位IMRAD_GRAYSCALE,因为我们需要的是识别手写字符,灰度图对比彩色图能更好的突出重点。
进行图像的缩放是不够的,因为观察上面的图片可以发现:拍摄环境对于对比度的影响非常大,所以我们应该突出深色区域(数字部分),来保证后面的工作顺利进行,这里采用的是伽马变换(也可以采用对数变换):
1 def imageGamma(image): 2 for i in range(32): 3 for j in range(32): 4 image[i][j]=3*pow(image[i][j],0.8) 5 return image
2)图像二值化
缩小/放大后的图像已经是一个32*32的图像了,下一步则是将非数字区域填充0,数字区域填充1,这里我采用的是阈值二值化处理:
def imageThreshold(image): ret,image = cv2.threshold(image,150,255,cv2.THRESH_BINARY) return image
经过二值化处理,数字部分的灰度值应该为0,而非数字部分的连通区域的灰度值应该为255,如下所示:
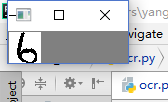
3)去噪
图像去噪的方式有很多种,这里建立使用自适应中值滤波器进行降噪,因为我们的图像在传输过程中可能出现若干的椒盐噪声,这个噪声在上述的二值化处理中有时候是非常棘手的。
到目前为止,一副手机摄像的手写数字图像就可以转换为一个32*32的二值图像。
4)生成训练样本
如何将这个32*32的二值图像转换为0/1图像,这个处理非常简单:
1 def imageProcess(image): 2 with open(r'F:\Users\yang\PycharmProjects\OCR_KNN\testDigits\6_0.txt','w+') as file: 3 for i in range(32): 4 for j in range(32): 5 if image[i][j] == 255: 6 file.write('0') 7 else: 8 file.write('1') 9 file.writelines('\n')
这里我的代码在扫描这个图像的同时,将其保存为一个训练样本,命名和训练集的明明要求一样为N_M.txt,其中N代表这个训练样本的实际分类是什么数字,M代表这是这个数字的第几个样本。这里对图像进行灰度变换已经是多此一举了,我所需要的是0/1矩阵而非一个0/1图像,所以在扫描过程中一并生成训练样本更加省时直观。
5)形成训练集
上面的示例只是生成一个图像的训练样本的,而实际上我们往往需要一次性生成一个训练集,这就要求这个图像预处理、二值化并且生成0/1矩阵的过程是自动的:
1 from os import listdir 2 def imProcess(imagePath): 3 testDigits = listdir(imagePath) 4 for i in range(len(testDigits)): 5 imageName = testDigits[i]#图像命名格式为N_M.png,NM含义见4)生成训练样本 6 #imageClass = int((imageName.split('.')[0]).split('_')[0])#这个图像的数字是多少 7 image = cv2.imread(imageName,cv2.IMREAD_GRAYSCALE) 8 image = cv2.resize(image, (32, 32), interpolation=cv2.INTER_AREA) 9 ret, image = cv2.threshold(image, 150, 255, cv2.THRESH_BINARY) 10 with open(r'F:\Users\yang\PycharmProjects\OCR_KNN\testDigits\\'+imageName.split('.')[0]+'.txt','w+') as file: 11 for i in range(32): 12 for j in range(32): 13 if image[i][j] == 255: 14 file.write('0') 15 else: 16 file.write('1') 17 file.writelines('\n')
这个函数将imagePath文件夹中所有的N_M命名的手写数字图像读取并经过预处理、二值化、最后保存为对应的0/1矩阵,命名为N_M.txt,这就构成一个训练集了。
2、构建分类器
分类器使用上一节的分类器(classify):
1 def classify(vector,dataSet,labels,k): 2 distance = sqrt(abs(((tile(vec,(dataSet.shape[0],1)) - dataSet) ** 2).sum(axis = 1))); #计算距离 3 sortedDistance = distance.argsort() 4 dict={} 5 for i in range(k): 6 label = labels[sortedDistance[i]] 7 if not label in dict: 8 dict[label] = 1 9 else: 10 dict[label]+=1 11 sortedDict = sorted(dict,key = operator.itemgetter(1),reverse = True) 12 return sortedDict[0][0] 13 14 def dict2list(dic:dict):#将字典转换为list类型 15 keys=dic.keys() 16 values=dic.values() 17 lst=[(key, value)for key,value in zip(keys,values)] 18 return lst
distance的计算和dict2list函数的详解在上一节,戳上面的classify既可以跳转过去。
分类器已经构建完成,下一步是提取每一个测试样本,提取训练集,提取label的过程:(这个过程大部分用的是《机器学习实战》中的代码,对于难以理解的代码在下文中做了解释:)
1)读取0/1矩阵文件:
1 def img2vector(filename): 2 returnvec = numpy.zeros((1,1024)) 3 file = open(filename) 4 for i in range(32): 5 line = file.readline() 6 for j in range(32): 7 returnvec[0,32*i+j] = int(line[j]) 8 return returnvec
这里要注意:构造一个32*32的全零矩阵的时候,应该是numpy.zeros((1,1024)),双层括号!双层括号!双层括号!代表构造的是一个二维矩阵!
2)读取训练集和测试集并求解准确率:
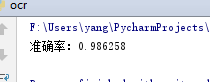
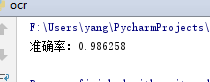
1 def handWritingClassifyTest(): 2 labels=[] 3 trainingFile = listdir(r'F:\Users\yang\PycharmProjects\OCR_KNN\trainingDigits') 4 m = len(trainingFile) 5 trainingMat = numpy.zeros((m,1024)) 6 for i in range(m): 7 file = trainingFile[i] 8 filestr = file.strip('.')[0] 9 classnum = int(filestr.strip('_')[0]) 10 labels.append(classnum) 11 trainingMat[i,:] = img2vector('trainingDigits/%s' % file) 12 testFileList = listdir(r'F:\Users\yang\PycharmProjects\OCR_KNN\testDigits') 13 error = 0.0 14 testnum = len(testFileList) 15 for i in range(testnum): 16 file_test = testFileList[i] 17 filestr_test = file_test.strip('.')[0] 18 classnum_test = int(filestr_test.strip('_')[0]) 19 vector_test = img2vector('testDigits/%s'%file_test) 20 result = classify(vector_test,trainingMat,labels,1) 21 if(result!=classnum_test):error+=1.0 22 print("准确率:%f"%(1.0-(error/float(testnum))))
代码其实没有很难懂的地方,主要任务就是读取文件,通过img2vctor函数转换为矩阵,还有切割文件名获取该测试样本的类别和该训练样本的类别,通过对比获得准确率。
3、使用分类器
现在为止,我们的分类器已经构建完成,下面就是测试和使用阶段:
1)测试《机器学习实战》中给出的训练集:
2)测试手写训练集:
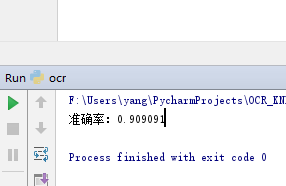
emmm果然学不出来大佬写字,附上几张无法识别的0/1数字矩阵:(0,4,6无法识别的原因是比划太细哈哈,8无法识别的原因……太端正了吧)




4、完整代码:
1 from os import listdir 2 import numpy 3 import operator 4 import cv2 5 6 def imProcess(imagePath): 7 testDigits = listdir(imagePath) 8 for i in range(len(testDigits)): 9 imageName = testDigits[i]#图像命名格式为N_M.png,NM含义见4)生成训练样本 10 #imageClass = int((imageName.split('.')[0]).split('_')[0])#这个图像的数字是多少 11 image = cv2.imread(imageName,cv2.IMREAD_GRAYSCALE) 12 image = cv2.resize(image, (32, 32), interpolation=cv2.INTER_AREA) 13 ret, image = cv2.threshold(image, 150, 255, cv2.THRESH_BINARY) 14 with open(r'F:\Users\yang\PycharmProjects\OCR_KNN\testDigits\\'+imageName.split('.')[0]+'.txt','w+') as file: 15 for i in range(32): 16 for j in range(32): 17 if image[i][j] == 255: 18 file.write('0') 19 else: 20 file.write('1') 21 file.writelines('\n') 22 23 def img2vector(filename): 24 returnvec = numpy.zeros((1,1024)) 25 file = open(filename) 26 for i in range(32): 27 line = file.readline() 28 for j in range(32): 29 returnvec[0,32*i+j] = int(line[j]) 30 return returnvec 31 32 def handWritingClassifyTest(): 33 labels=[] 34 trainingFile = listdir(r'F:\Users\yang\PycharmProjects\OCR_KNN\trainingDigits') 35 m = len(trainingFile) 36 trainingMat = numpy.zeros((m,1024)) 37 for i in range(m): 38 file = trainingFile[i] 39 filestr = file.strip('.')[0] 40 classnum = int(filestr.strip('_')[0]) 41 labels.append(classnum) 42 trainingMat[i,:] = img2vector('trainingDigits/%s' % file) 43 testFileList = listdir(r'F:\Users\yang\PycharmProjects\OCR_KNN\testDigits') 44 error = 0.0 45 testnum = len(testFileList) 46 for i in range(testnum): 47 file_test = testFileList[i] 48 filestr_test = file_test.strip('.')[0] 49 classnum_test = int(filestr_test.strip('_')[0]) 50 vector_test = img2vector('testDigits/%s'%file_test) 51 result = classify(vector_test,trainingMat,labels,1) 52 if(result!=classnum_test):error+=1.0 53 print("准确率:%f"%(1.0-(error/float(testnum)))) 54 55 def classify(inX,dataSet,labels,k): 56 size = dataSet.shape[0] 57 distance = (((numpy.tile(inX,(size,1))-dataSet)**2).sum(axis=1))**0.5 58 sortedDistance = distance.argsort() 59 count = {} 60 for i in range(k): 61 label = labels[sortedDistance[i]] 62 count[label]=count.get(label,0)+1 63 sortedcount = sorted(dict2list(count),key=operator.itemgetter(1),reverse=True) 64 return sortedcount[0][0] 65 66 def dict2list(dic:dict):#将字典转换为list类型 67 keys=dic.keys() 68 values=dic.values() 69 lst=[(key, value)for key,value in zip(keys,values)] 70 return lst 71 72 # def imProcess(image): 73 # image = cv2.resize(image, (32, 32), interpolation=cv2.INTER_AREA) 74 # ret, image = cv2.threshold(image, 150, 255, cv2.THRESH_BINARY) 75 # cv2.imshow('result',image) 76 # cv2.waitKey(0) 77 # with open(r'F:\Users\yang\PycharmProjects\OCR_KNN\testDigits\6_0.txt','w+') as file: 78 # for i in range(32): 79 # for j in range(32): 80 # if image[i][j] == 255: 81 # file.write('0') 82 # else: 83 # file.write('1') 84 # file.writelines('\n') 85 86 87 88 # iamge = cv2.imread(r'C:\Users\yang\Desktop\6.png',cv2.IMREAD_GRAYSCALE) 89 # image = imProcess(iamge) 90 imProcess(r'F:\Users\yang\PycharmProjects\OCR_KNN\testDigits') 91 handWritingClassifyTest()
5、github:https://github.com/hahahaha1997/OCR
三、总结
KNN还是不适合用来做OCR的识别过程的,虽然《机器学习实战》的作者提到这个系统是美国的邮件分拣系统实际运行的一个系统,但是它肯定无法高准确率地识别中国人写的手写文字就对了,毕竟中国有些地方的“9”还会写成“p”的样子的。这一节主要是将KNN拓展到实际运用中的,结合上一节的理论,KNN的执行效率还是太低了,比如这个系统,要识别一个手写数字,它需要和所有的训练样本做距离计算,每个距离计算又有1024个(a-b)²,还有运行效率特别低下的sqrt(),如果是一个非常大的测试集,需要的时间就更加庞大,如果训练集非常庞大,在将0/1矩阵读入内存中的时候,内存开销是非常巨大的,所以整个程序可能会非常耗时费力。不过KNN仍旧是一个精度非常高的算法,并且也是机器学习分类算法中最简单的算法之一。下一节将带来机器学习经典算法——ID3决策树。转载注明出处哦:https://www.cnblogs.com/DawnSwallow/p/9440516.html

