

MySQL 8.0窗口函数
团队介绍
网易乐得DBA组,负责网易乐得电商、网易邮箱、网易技术部数据库日常运维,负责数据库私有云平台的开发和维护,负责数据库及数据库中间件Cetus的开发和测试等等。
一、窗口函数的使用场景
作为IT人士,日常工作中经常会遇到类似这样的需求:
医院看病,怎样知道上次就医距现在的时间?环比如何计算?怎么样得到各部门工资排名前N名员工列表?查找各部门每人工资占部门总工资的百分比?
对于这样的需求,使用传统的SQL实现起来比较困难。这类需求都有一个共同的特点,需要在单表中满足某些条件的记录集内部做一些函数操作,不是简单的表连接,也不是简单的聚合可以实现的,通常会让写SQL的同学焦头烂额、绞尽脑汁,费了大半天时间写出来一堆长长的晦涩难懂的自连接SQL,且性能低下,难以维护。
要解决此类问题,最方便的就是使用窗口函数。
二、MySQL窗口函数简介
MySQL从8.0开始支持窗口函数,这个功能在大多商业数据库和部分开源数据库中早已支持,有的也叫分析函数。
什么叫窗口?
窗口的概念非常重要,它可以理解为记录集合,窗口函数也就是在满足某种条件的记录集合上执行的特殊函数。对于每条记录都要在此窗口内执行函数,有的函数随着记录不同,窗口大小都是固定的,这种属于静态窗口;有的函数则相反,不同的记录对应着不同的窗口,这种动态变化的窗口叫滑动窗口。
窗口函数和普通聚合函数也很容易混淆,二者区别如下:
-
聚合函数是将多条记录聚合为一条;而窗口函数是每条记录都会执行,有几条记录执行完还是几条。
-
聚合函数也可以用于窗口函数中,这个后面会举例说明。
下面是一个窗口函数的简单例子:

上面例子中,row_number()over(partition by user_no order by amount desc)这部分都属于窗口函数,它的功能是显示每个用户按照订单金额从大到小排序的序号。
按照功能划分,可以把MySQL支持的窗口函数分为如下几类:
-
序号函数:row_number() / rank() / dense_rank()
-
分布函数:percent_rank() / cume_dist()
-
前后函数:lag() / lead()
-
头尾函数:first_val() / last_val()
-
其他函数:nth_value() / nfile()
三、窗口函数如何使用
窗口函数的基本用法如下:
函数名([expr]) over子句
其中,over是关键字,用来指定函数执行的窗口范围,如果后面括号中什么都不写,则意味着窗口包含满足where条件的所有行,窗口函数基于所有行进行计算;如果不为空,则支持以下四种语法来设置窗口:
-
window_name:给窗口指定一个别名,如果SQL中涉及的窗口较多,采用别名可以看起来更清晰易读。上面例子中如果指定一个别名w,则改写如下:
select * from
(
select row_number()over w as row_num,
order_id,user_no,amount,create_date
from order_tab
WINDOW w AS (partition by user_no order by amount desc)
)t ;
-
partition子句:窗口按照那些字段进行分组,窗口函数在不同的分组上分别执行。上面的例子就按照用户id进行了分组。在每个用户id上,按照order by的顺序分别生成从1开始的顺序编号。
-
order by子句:按照哪些字段进行排序,窗口函数将按照排序后的记录顺序进行编号。可以和partition子句配合使用,也可以单独使用。上例中二者同时使用,如果没有partition子句,则会按照所有用户的订单金额排序来生成序号。
-
frame子句:frame是当前分区的一个子集,子句用来定义子集的规则,通常用来作为滑动窗口使用。比如要根据每个订单动态计算包括本订单和按时间顺序前后两个订单的平均订单金额,则可以设置如下frame子句来创建滑动窗口:
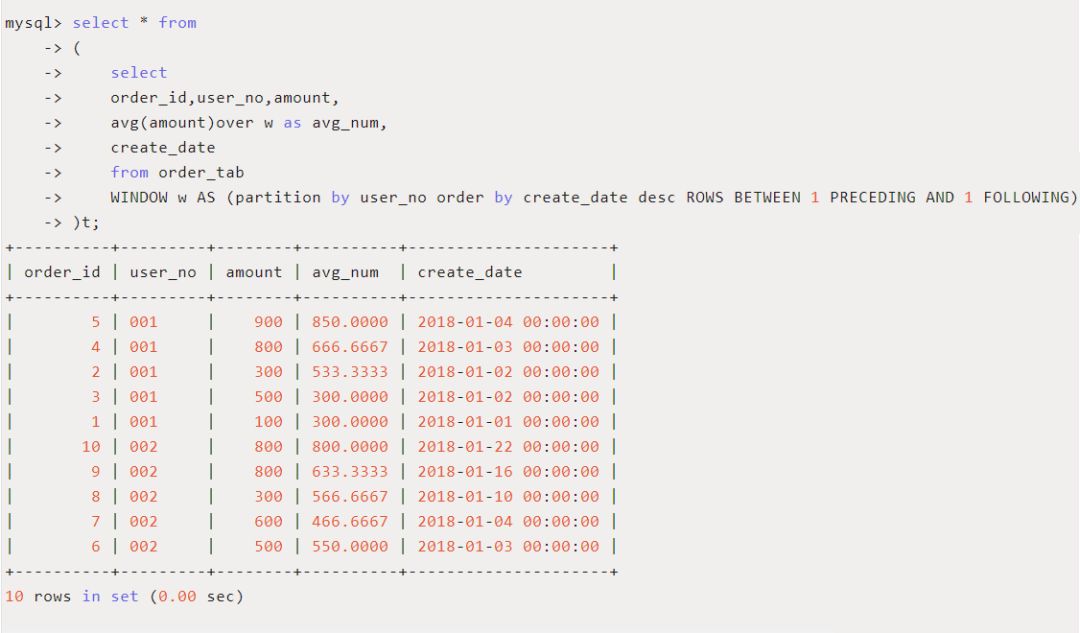
从结果可以看出,order_id为5订单属于边界值,没有前一行,因此平均订单金额为(900+800)/2=850;order_id为4的订单前后都有订单,所以平均订单金额为(900+800+300)/3=666.6667,以此类推就可以得到一个基于滑动窗口的动态平均订单值。此例中,窗口函数用到了传统的聚合函数avg(),用来计算动态的平均值。
对于滑动窗口的范围指定,有两种方式,基于行和基于范围,具体区别如下:
基于行:
通常使用BETWEEN frame_start AND frame_end语法来表示行范围,frame_start和frame_end可以支持如下关键字,来确定不同的动态行记录:
CURRENT ROW 边界是当前行,一般和其他范围关键字一起使用
UNBOUNDED PRECEDING 边界是分区中的第一行
UNBOUNDED FOLLOWING 边界是分区中的最后一行
expr PRECEDING 边界是当前行减去expr的值
expr FOLLOWING 边界是当前行加上expr的值
比如,下面都是合法的范围:
rows BETWEEN 1 PRECEDING AND 1 FOLLOWING 窗口范围是当前行、前一行、后一行一共三行记录。
rows UNBOUNDED FOLLOWING 窗口范围是当前行到分区中的最后一行。
rows BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING 窗口范围是当前分区中所有行,等同于不写。
基于范围:
和基于行类似,但有些范围不是直接可以用行数来表示的,比如希望窗口范围是一周前的订单开始,截止到当前行,则无法使用rows来直接表示,此时就可以使用范围来表示窗口:INTERVAL 7 DAY PRECEDING。Linux中常见的最近1分钟、5分钟负载是一个典型的应用场景。
有的函数不管有没有frame子句,它的窗口都是固定的,也就是前面介绍的静态窗口,这些函数包括如下:
-
CUME_DIST()
-
DENSE_RANK()
-
LAG()
-
LEAD()
-
NTILE()
-
PERCENT_RANK()
-
RANK()
-
ROW_NUMBER()
接下来我们以上例的订单表为例,来介绍每个函数的使用方法。表中各字段含义按顺序分别为订单号、用户id、订单金额、订单创建日期。
四、序号函数
序号函数——row_number() / rank() / dense_rank()。
-
用途:显示分区中的当前行号
-
使用场景:希望查询每个用户订单金额最高的前三个订单
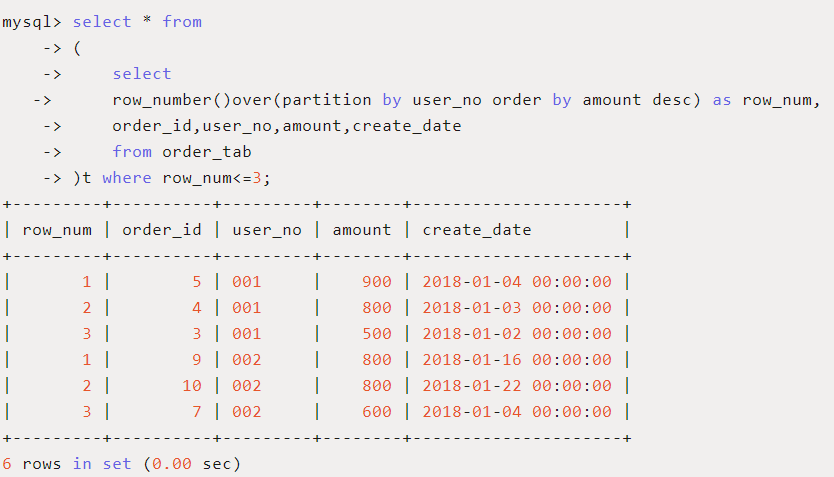
此时可以使用ROW_NUMBER()函数按照用户进行分组并按照订单日期进行由大到小排序,最后查找每组中序号<=3的记录。
对于用户‘002’的订单,大家发现订单金额为800的有两条,序号随机排了1和2,但很多情况下二者应该是并列第一,而订单为600的序号则可能是第二名,也可能为第三名,这时候,row_number就不能满足需求,需要rank和dense_rank出场。
这两个函数和row_number()非常类似,只是在出现重复值时处理逻辑有所不同。
上面例子我们稍微改一下,需要查询不同用户的订单中,按照订单金额进行排序,显示出相应的排名序号,SQL中用row_number() / rank() / dense_rank()分别显示序号,我们看一下有什么差别:
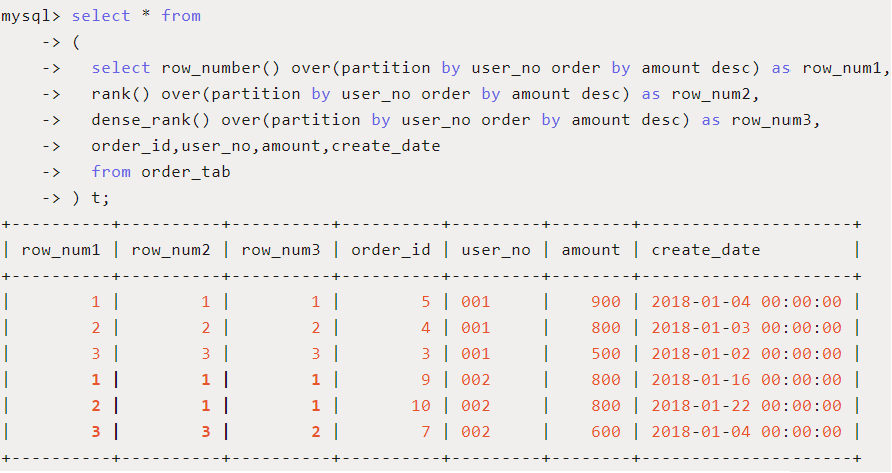
上面红色粗体显示了三个函数的区别,row_number()在amount都是800的两条记录上随机排序,但序号按照1、2递增,后面amount为600的的序号继续递增为3,中间不会产生序号间隙;rank()/dense_rank()则把amount为800的两条记录序号都设置为1,但后续amount为600的需要则分别设置为3(rank)和2(dense_rank)。即rank()会产生序号相同的记录,同时可能产生序号间隙;而dense_rank()也会产生序号相同的记录,但不会产生序号间隙。
五、分布函数
分布函数——percent_rank()/cume_dist()。
percent_rank()
-
用途:和之前的RANK()函数相关,每行按照如下公式进行计算:
(rank - 1) / (rows - 1)
其中,rank为RANK()函数产生的序号,rows为当前窗口的记录总行数。
-
应用场景:没想出来……感觉不太常用,看个例子吧↓

从结果看出,percent列按照公式(rank - 1) / (rows - 1)带入rank值(row_num列)和rows值(user_no为‘001’和‘002’的值均为5)。
cume_dist()
-
用途:分组内小于等于当前rank值的行数/分组内总行数,这个函数比percen_rank使用场景更多。
-
应用场景:大于等于当前订单金额的订单比例有多少。
SQL如下:

列cume显示了预期的数据分布结果。
六、前后函数
前后函数——lead(n)/lag(n)。
-
用途:分区中位于当前行前n行(lead)/后n行(lag)的记录值。
-
使用场景:查询上一个订单距离当前订单的时间间隔。
SQL如下:
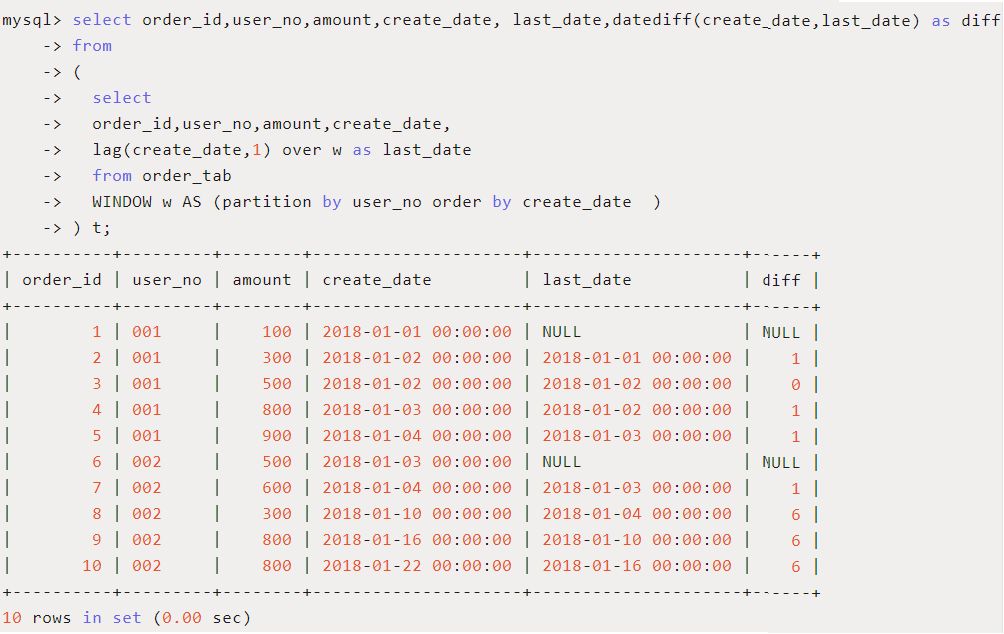
内层SQL先通过lag函数得到上一次订单的日期,外层SQL再将本次订单和上次订单日期做差得到时间间隔diff。
七、头尾函数
头尾函数——first_val(expr)/last_val(expr)。
-
用途:得到分区中的第一个/最后一个指定参数的值。
-
使用场景:查询截止到当前订单,按照日期排序第一个订单和最后一个订单的订单金额。
SQL如下:
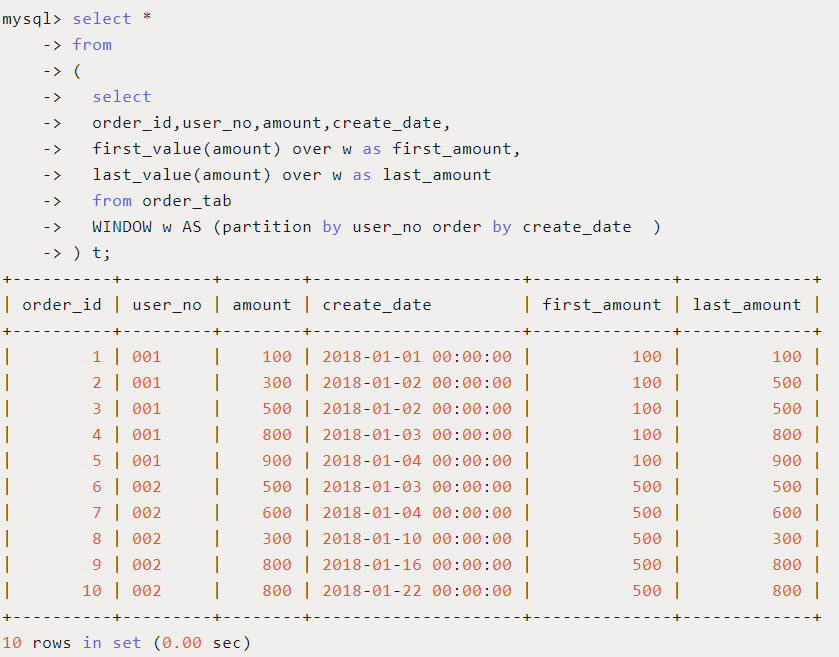
结果和预期一致,比如order_id为4的记录,first_amount和last_amount分别记录了用户‘001’截止到时间2018-01-03 00:00:00为止,第一条订单金额100和最后一条订单金额800,注意这里是按时间排序的最早订单和最晚订单,并不是最小金额和最大金额订单。
八、其他函数
其他函数——nth_value(expr,n)/nfile(n)。
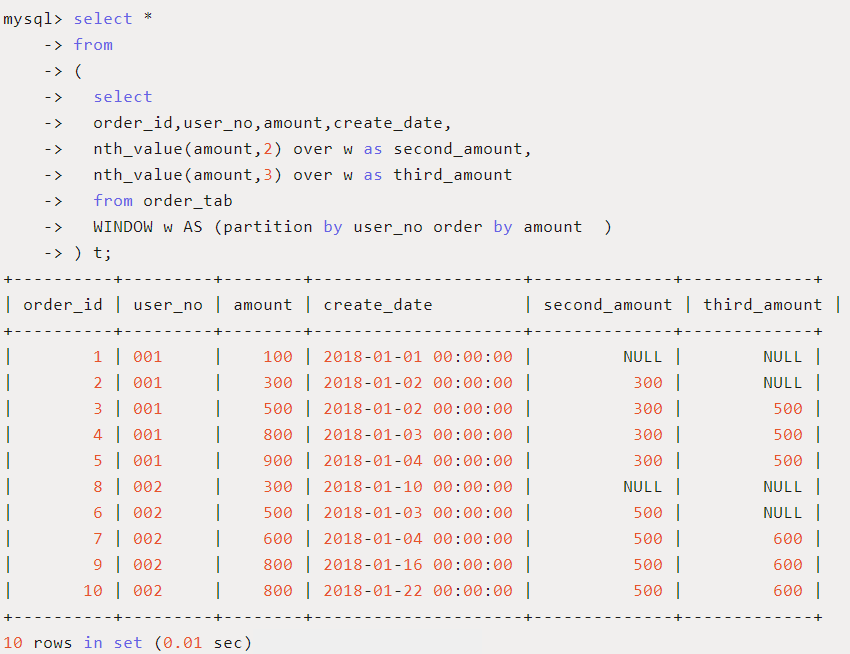
nth_value(expr,n)
-
用途:返回窗口中第N个expr的值,expr可以是表达式,也可以是列名。
-
应用场景:每个用户订单中显示本用户金额排名第二和第三的订单金额。
SQL如下:
nfile(n)
-
用途:将分区中的有序数据分为n个桶,记录桶号。
-
应用场景:将每个用户的订单按照订单金额分成3组。
SQL如下:
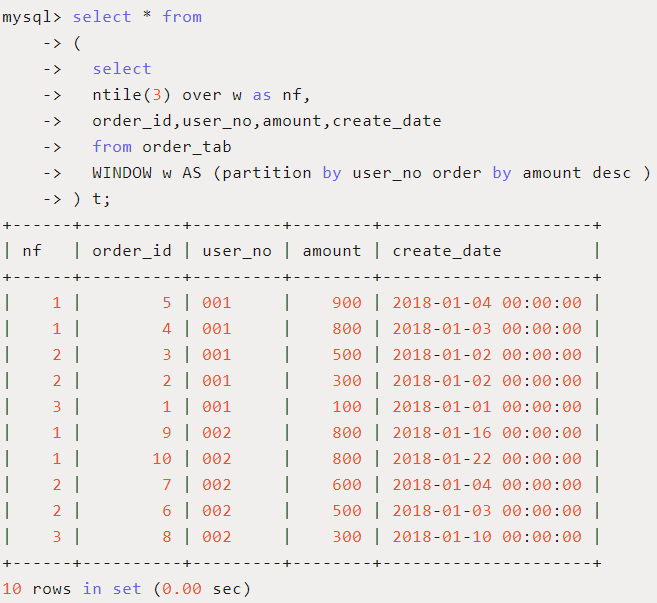
此函数在数据分析中应用较多,比如由于数据量大,需要将数据平均分配到N个并行的进程分别计算,此时就可以用NFILE(N)对数据进行分组,由于记录数不一定被N整除,所以数据不一定完全平均,然后将不同桶号的数据再分配。
九、聚合函数作为窗口函数
-
用途:在窗口中每条记录动态应用聚合函数(sum/avg/max/min/count),可以动态计算在指定的窗口内的各种聚合函数值。
-
应用场景:每个用户按照订单id,截止到当前的累计订单金额/平均订单金额/最大订单金额/最小订单金额/订单数是多少?
SQL如下:
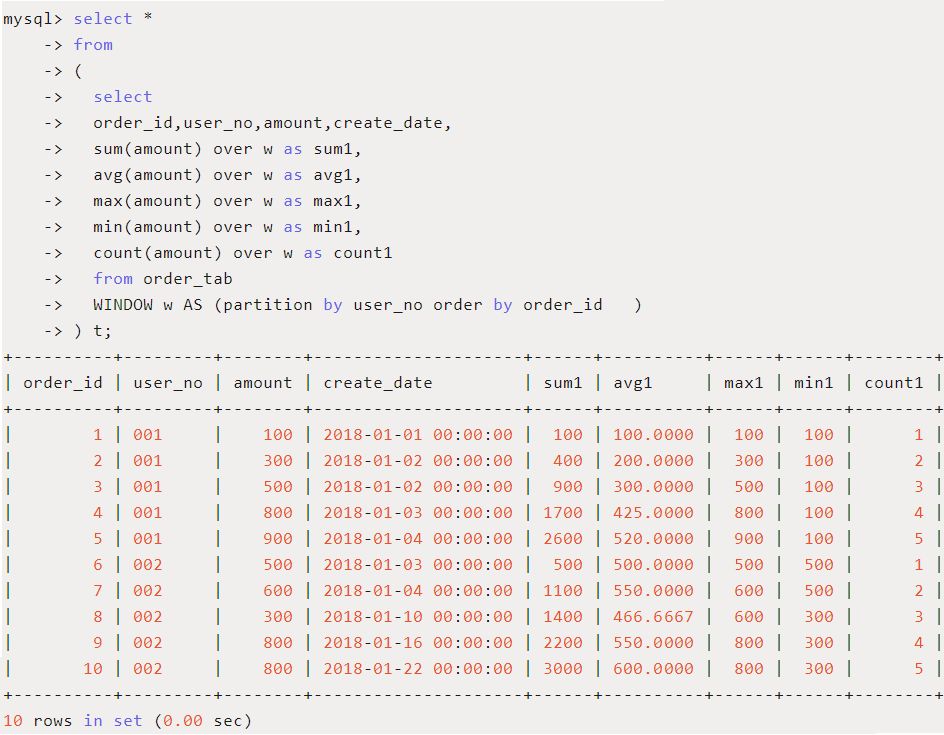
除了这几个常用的聚合函数,还有一些也可以使用,比如BIT_AND()、STD()等等,具体查看官方文档。
窗口函数非常有意思,对于一些使用常规思维无法实现的SQL需求,大家尝试一下窗口函数吧,相信会有意想不到的收获。

