
Webpack系列-第一篇基础杂记
前言
公司的前端项目基本都是用Webpack来做工程化的,而Webpack虽然只是一个工具,但内部涉及到非常多的知识,之前一直靠CV来解决问题,之知其然不知其所以然,希望这次能整理一下相关的知识点。
简介
这是webpack官方的首页图
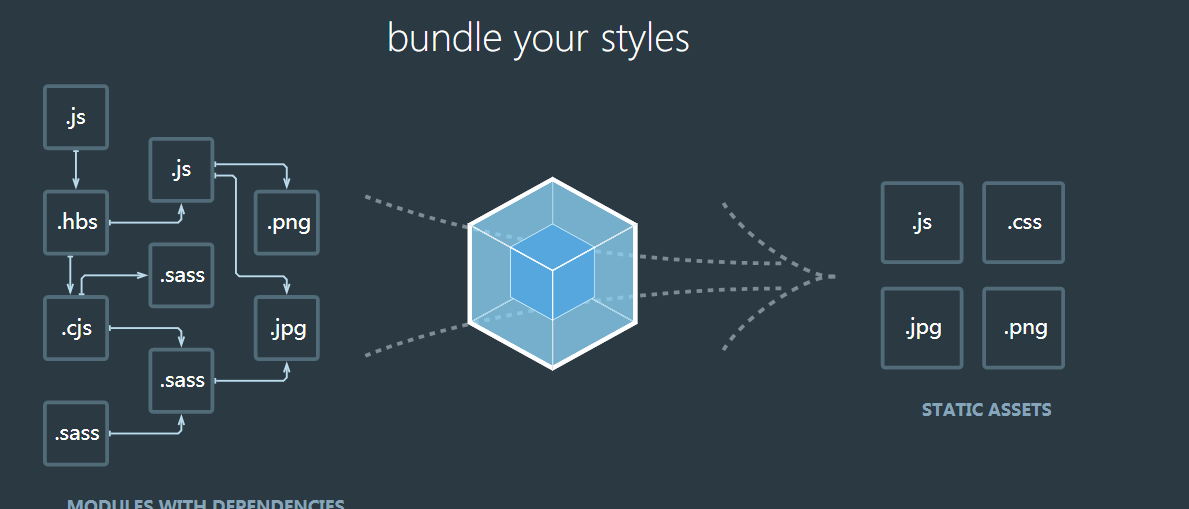
本质上,webpack 是一个现代 JavaScript 应用程序的静态模块打包器(module bundler)。当 webpack 处理应用程序时,它会递归地构建一个依赖关系图(dependency graph),其中包含应用程序需要的每个模块,然后将所有这些模块打包成一个或多个 bundle。
那么打个比方就是我们搭建一个项目好比搭建一个房子,我们把所需要的材料(js文件、图片等)交给webpack,最后webpack会帮我们做好一切,并把房子(即bundle)输出。
webpack中有几个概念需要记住
entry(入口)
入口起点(entry point)即是webpack通过该起点找到本次项目所直接或间接依赖的资源(模块、库等),并对其进行处理,最后输出到bundle中。入口文件由用户自定义,可以是一个或者多个,每一个entry最后对应一个bundle。
output(出口)
通过配置output属性可以告诉webpack将bundle命名并输出到对应的位置。
loader
webpack核心,webpack本身只能识别js文件,对于非js文件,即需要loader转换为js文件。换句话说,,Loader就是资源转换器。由于在webpack里,所有的资源都是模块,不同资源都最终转化成js去处理。针对不同形式的资源采用不同的Loader去编译,这就是Loader的意义。
插件(plugin)
webpack核心,loader处理非js文件,那么插件可以有更广泛的用途。整个webpack其实就是各类的插件形成的,插件的范围包括,从打包优化和压缩,一直到重新定义环境中的变量。插件接口功能极其强大,可以用来处理各种各样的任务。
Chunk
被entry所依赖的额外的代码块,同样可以包含一个或者多个文件。chunk也就是一个个的js文件,在异步加载中用处很大。chunk实际上就是webpack打包后的产物,如果你不想最后生成一个包含所有的bundle,那么可以生成一个个chunk,并通过按需加载引入。同时它还能通过插件提取公共依赖生成公共chunk,避免多个bundle中有多个相同的依赖代码。
配置
webpack的相关配置语法官方文档比较详细,这里就不赘述了。
指南
配置
实践&优化
url-loader & image-webpack-loader
url-loader 可以在文件大小(单位 byte)低于指定的限制,将文件转换为DataURL,这在实际开发中非常有效,能够减少请求数,在vue-cli和create-react-app中也都能看到对这个loader的使用。
// "url" loader works just like "file" loader but it also embeds
// assets smaller than specified size as data URLs to avoid requests.
{
test: [/\.bmp$/, /\.gif$/, /\.jpe?g$/, /\.png$/],
loader: require.resolve('url-loader'),
options: {
limit: 10000,
name: 'static/media/[name].[hash:8].[ext]',
},
},
image-webpack-loader 这是一个可以通过设置质量参数来压缩图片的插件,但个人觉得在实际开发中并不会经常使用,图片一般是UI提供,一般来说,他们是不会同意图片的质量有问题。
资源私有化
以这种方式加载资源,你可以以更直观的方式将模块和资源组合在一起。无需依赖于含有全部资源的 /assets 目录,而是将资源与代码组合在一起。例如,类似这样的结构会非常有用
- |- /assets
+ |– /components
+ | |– /my-component
+ | | |– index.jsx
+ | | |– index.css
+ | | |– icon.svg
+ | | |– img.png
当然,这种选择见仁见智
Tree-Shaking
前端中的tree-shaking就是将一些无关的代码删掉不打包。在Webpack项目中,我们通常会引用很多文件,但实际上我们只引用了其中的某些模块,但却需要引入整个文件进行打包,会导致我们的打包结果变得很大,通过tree-shaking将没有使用的模块摇掉,这样来达到删除无用代码的目的。
归纳起来就是
1.ES6的模块引入是静态分析的,故而可以在编译时正确判断到底加载了什么代码。
2.分析程序流,判断哪些变量未被使用、引用,进而删除此代码
归纳起来就是
因为Babel的转译,使得引用包的代码有了副作用,而副作用会导致Tree-Shaking失效。
Webpack 4 默认启用了 Tree Shaking。对副作用进行了消除,以下是我在4.19.1的实验
index.js
import { cube } from './math.js'
console.log(cube(5))
math.js
// 不打包square
export class square {
constructor() {
console.log('square')
}
}
export class cube {
constructor(x) {
return x * x * x
}
}
// babel编译后 同不打包
'use strict';
Object.defineProperty(exports, "__esModule", {
value: true
});
exports.cube = cube;
function _classCallCheck(instance, Constructor) { if (!(instance instanceof Constructor)) { throw new TypeError("Cannot call a class as a function"); } }
var square = exports.square = function square() {
_classCallCheck(this, square);
console.log('square');
};
function cube(x) {
console.log('cube');
return x * x * x;
}
// 不打包
export function square(x) {
console.log('square')
return x.a
}
export function cube (x) {
return x * x * x
}
// wow 被打包
export function square() {
console.log('square')
return x.a
}
square({a: 1})
export function cube () {
return x * x * x
}
sourcemap
简单说,Source map就是一个信息文件,里面储存着位置信息。也就是说,转换后的代码的每一个位置,所对应的转换前的位置。
有了它,出错的时候,除错工具将直接显示原始代码,而不是转换后的代码。这无疑给开发者带来了很大方便。
webpack中的devtool配置项可以设置sourcemap,可以参考官方文档然而,devtool的许多选项都讲的不是很清楚,这里推荐该文章,讲的比较详细
要注意,避免在生产中使用 inline-* 和 eval-*,因为它们可以增加 bundle 大小,并降低整体性能。
模块热替换
热替换这一块目前大多数都是用的webpack-dev-middleware插件配合服务器使用的,而官方提供的watch模式反而比较少用,当然,webpack-dev-middleware的底层监听watch mode,至于为什么不直接使用watch模式,则是webpack-dev-middleware快速编译,走内存;只依赖webpack的watch mode来监听文件变更,自动打包,每次变更,都将新文件打包到本地,就会很慢。
DefinePlugin
webpack.DefinePlugin 定义环境变量process.env,这在实际开发中比较常用,参考create-react-app中的代码如下:
// Makes some environment variables available to the JS code, for example:
// if (process.env.NODE_ENV === 'development') { ... }. See `./env.js`.
new webpack.DefinePlugin(env.stringified),
不过,要注意不能在config中使用,因为
process.env.NODE_ENV === 'production' ? '[name].[hash].bundle.js' : '[name].bundle.js'
NODE_ENVis set in the compiled code, not in the webpack.config.js file. You should not use enviroment variables in your configuration. Pass options via--env.option abcand export a function from the webpack.config.js.
大致意思就是NODE_ENV是设置在compiled里面,而不是config文件里。
ExtractTextWebpackPlugin
ExtractTextWebpackPlugin,将css抽取成单独文件,可以通过这种方式配合后端对CSS文件进行缓存。
SplitChunksPlugin
webpack4的代码分割插件。
webpack4中支持了零配置的特性,同时对块打包也做了优化,CommonsChunkPlugin已经被移除了,现在是使用optimization.splitChunks代替。
SplitChunksPlugin的配置有几个需要比较关注一下
chunks: async | initial | all
- async: 默认值, 将按需引用的模块打包
- initial: 分开优化打包异步和非异步模块
- all: all会把异步和非异步同时进行优化打包。也就是说moduleA在indexA中异步引入,indexB中同步引入,initial下moduleA会出现在两个打包块中,而all只会出现一个。
cacheGroups
使用cacheGroups可以自定义配置打包块。
更多详细内容参考该文章
动态引入
则是利用动态引入的文件打包成另一个包,并懒加载它。其与SplitChunksPlugin的区别:
- Bundle splitting:实际上就是创建多个更小的文件,并行加载,以获得更好的缓存效果;主要的作用就是使浏览器并行下载,提高下载速度。并且运用浏览器缓存,只有代码被修改,文件名中的哈希值改变了才会去再次加载。
- Code splitting:只加载用户最需要的部分,其余的代码都遵从懒加载的策略;主要的作用就是加快页面加载速度,不加载不必要加载的东西。
参考代码:
+ import _ from 'lodash';
+
+ function component() {
var element = document.createElement('div');
+ var button = document.createElement('button');
+ var br = document.createElement('br');
+ button.innerHTML = 'Click me and look at the console!';
element.innerHTML = _.join(['Hello', 'webpack'], ' ');
+ element.appendChild(br);
+ element.appendChild(button);
+
+ // Note that because a network request is involved, some indication
+ // of loading would need to be shown in a production-level site/app.
+ button.onclick = e => import(/* webpackChunkName: "print" */ './print').then(module => {
+ var print = module.default;
+
+ print();
+ });
return element;
}
+ document.body.appendChild(component());
注意当调用 ES6 模块的 import() 方法(引入模块)时,必须指向模块的 .default 值,因为它才是 promise 被处理后返回的实际的 module 对象。
缓存runtimeChunk
因为webpack会把运行时代码放到最后的一个bundle中, 所以即使我们修改了其他文件的代码,最后的一个bundle的hash也会改变,runtimeChunk是把运行时代码单独提取出来的配置。这样就有利于我们和后端配合缓存文件。
配置项
- single: 所有入口共享一个生成的runtimeChunk
- true/mutiple: 每个入口生成一个单独的runtimeChunk
模块标识符
有时候我们只是添加了个文件print.js, 并在index引入
import Print from './print'
打包的时候,期望只有runtime和main两个bundle的hash发生改变,但是通常所有bundle都发生了变化,因为每个 module.id 会基于默认的解析顺序(resolve order)进行增量。也就是说,当解析顺序发生变化,ID 也会随之改变。
可以使用两个插件来解决这个问题。第一个插件是 NamedModulesPlugin,将使用模块的路径,而不是数字标识符。虽然此插件有助于在开发过程中输出结果的可读性,然而执行时间会长一些。第二个选择是使用 HashedModuleIdsPlugin。
参考文章
ProvidePlugin
通过ProvidePlugin处理全局变量
其他更细粒度的处理
polyfills的处理
首先了解一下polyfills, 虽然在webpack中能够使用es6\es7等的API,但并不代表编译器支持这些API,所以通常我们会用polyfills来自定义一个API。
那么在webpack中,一般是使用babel-polyfill VS babel-runtime VS babel-preset-env等来支持这些API,而这三种怎么选择也是一个问题。
在真正进入主题之前,我们先看一个preset-env的配置项,同时也是package.json中的一个配置项browserslist
{
"browserslist": [
"last 1 version",
"> 1%",
"maintained node versions",
"not dead"
]
}
根据这个配置,preset-env或者postcss等会根据你的参数支持不同的polyfills,具体的参数配置参考该文章
另外推荐一个网站,可以看各种浏览器的使用情况。
- babel-polyfill 只需要引入一次,但会重写一些原生的已支持的方法,而且体积很大。
- transform-runtime 是利用 plugin 自动识别并替换代码中的新特性,你不需要再引入,只需要装好 babel-runtime 和 配好 plugin 就可以了。好处是按需替换,检测到你需要哪个,就引入哪个 polyfill,值得注意的是,instance 上新添加的一些方法,babel-plugin-transform-runtime 是没有做处理的,比如 数组的 includes, filter, fill 等
- babel-preset-env 根据当前的运行环境,自动确定你需要的 plugins 和 polyfills。通过各个 es标准 feature 在不同浏览器以及 node 版本的支持情况,再去维护一个 feature 跟 plugins 之间的映射关系,最终确定需要的 plugins。
参考文章
后编译
日常我们引用的Npm包都是编译好的,这样带来的方便的同时也暴露了一些问题。
代码冗余:一般来说,这些 NPM 包也是基于 ES2015+ 开发的,每个包都需要经过 babel 编译发布后才能被主应用使用,而这个编译过程往往会附加很多“编译代码”;每个包都会有一些相同的编译代码,这就造成大量代码的冗余,并且这部分冗余代码是不能通过 Tree Shaking 等技术去除掉的。
非必要的依赖:考虑到组件库的场景,通常我们为了方便一股脑引入了所有组件;但实际情况下对于一个应用而言可能只是用到了部分组件,此时如果全部引入,也会造成代码冗余。
所以我们自己的公司组件可以采用后编译的形式,即发布的是未经编译的npm包,在项目构建时才编译,我们公司采用的也是这种做法,因为我们的包都在一个目录下,所以不用考虑递归编译的问题。
更多的详细请直接参考该文章
设置环境变量
这个比较简单,直接看代码或者官方文档即可
webpack --env.NODE_ENV=local --env.production --progress
其他插件
- CompressionWebpackPlugin 将文件压缩 文件大小减小很多 需要后端协助配置
- mini-css-extract-plugin将CSS分离出来
- wbepack.IgnorePlugin忽略匹配的模块
- uglifyjs-webpack-plugin代码丑化,webpack4的mode(product)自动配置
- optimize-css-assets-webpack-plugincss压缩
- webpack-md5-hash使你的chunk根据内容生成md5,用这个md5取代 webpack chunkhash。
总结
Webpack本身并不难于理解,难的是各种各样的配置和周围生态带来的复杂,然而也是这种复杂给我们带来了极高的便利性,理解这些有助于在搭建项目更好的优化。后面会继续写出两篇总结,分别是webpack的内部原理流程和webpack的插件开发原理。


