
云时代架构阅读笔记二——一次CPU负载超高的分析
本文为转载,博客原地址:http://www.jianshu.com/p/4a6fe6c82311
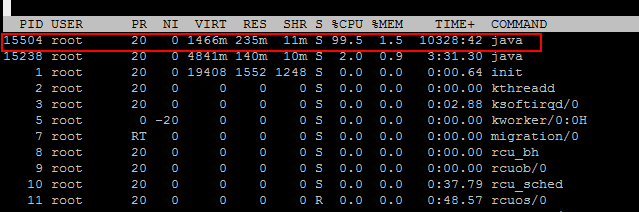
上线发号器,发现该进程的cpu占用率很高,接近100% 。
top结果如下:
查询具体的线程cpu占用率,如下:

可以看到 15505号线程基本占用了全部的cpu资源 。继续查看该线程的具体执行情况。如下:
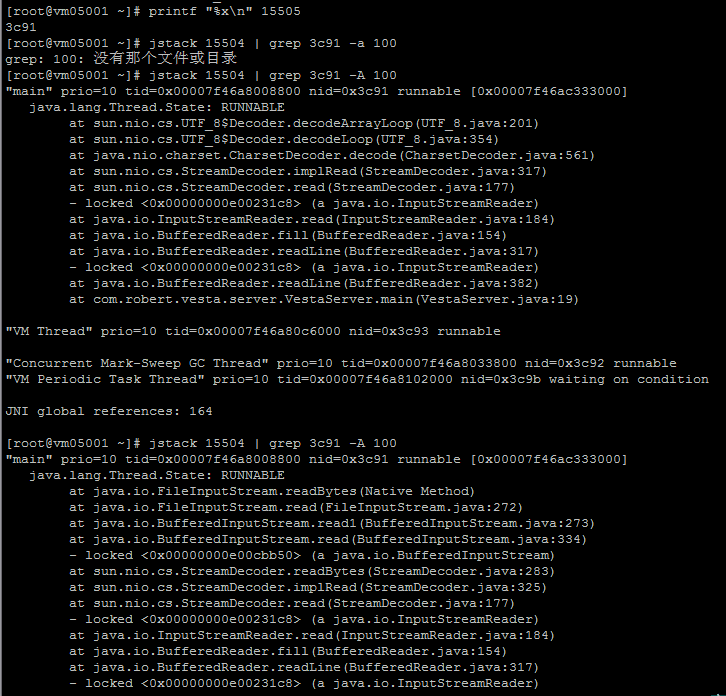
FileInputStream.java中关于readBytes的代码,如下:
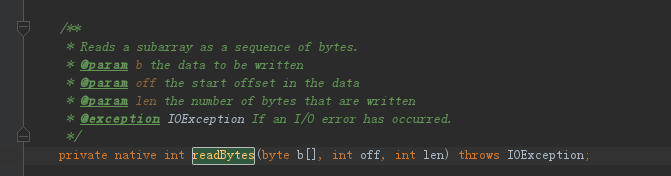
从代码中可知, 该方法调用的是 native readBytes 。本地方法如下:

继续跟代码:

通过代码可以看到 ,readBytes 是通过调用IO_Read来实现文件读取。
在io_util_md.h 可以找到 IO_Read的宏定义:

在 jvm.h 找到JVM_Read的申明:
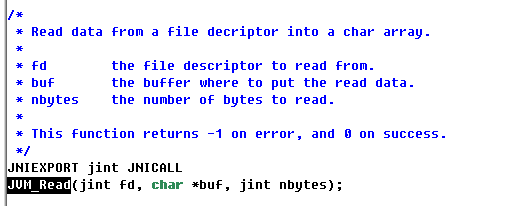
在往下无法找到JVM_Read的实现 ,故只能猜测其调用了系统的read 或fread实现读取。为证明猜测选用windows的实现做旁证 。前面都一样 ,从 io_util_md.h 开始有变化
\openjdk\jdk\src\windows\native\java\io\io_util_md.h 发现 IO_Read的宏定义如下:

\openjdk\jdk\src\windows\native\java\io\io_util_md.c 找到 handleRead的实现:

可以看到windows提供的ReadFile是最终读取数据的地方。
相同的代码在本地windows上运行 ,cpu利用率一直极低,可见IO的阻塞效果很好 ;而在服务器上cpu利用高,则怀疑是因为Linux在操作系统read上与windows优化不一致。此外还需要继续分析不同版本linux系统才能得出这是单独某个版本的问题亦或是系列问题。
本次分析所用系统相关信息如下:
linux相关版本信息

windows相关版本信息
回到应用层看发号器服务化版本实现,发号器简单的轮训等待控制台实现,修改为每一分钟轮训一次控制台,因为发号器的主线程仅仅用于启动服务线程,并不做任何有用的事情,保持运行状态即可,修改后的代码如下:
BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); while (!"exit".equals(br.readLine())) try { Thread.sleep(60000); } catch (InterruptedException e) { // If error, print it to console e.printStackTrace(); };

