
SQL Server-聚焦聚集索引对非聚集索引的影响(四)
前言
在学习SQL 2012基础教程过程中会时不时穿插其他内容来进行讲解,相信看过SQL Server 2012 T-SQL基础教程的童鞋知道前面写的所有内容并非都是摘抄书上内容,如若是这样那将没有任何意义,学习的过程必须同时也是一个思考的过程,无论是独立思考也好还是查资料也罢都是思考而非走马观花,要不然过一段时间又会健忘。简短的内容,深入的理解,Always to review the basics。
话题
非聚集索引定义:非聚集索引也是一个B树结构,与聚集索引不同的是,B树的叶子节点存的是指向堆或聚集索引的指针。你真的理解了吗??你能举出例子吗??其实本节最终想表达的就是这个意思,定义太长,我们抽象一点来定义并得出最终结论,请往下看。
聚集索引对非聚集索引影响
关于聚集索引和非聚集索引的概念、原理、创建都不会再叙述,若对此不太了解请参考园中其他园友的详细介绍。
首先我们创建测试表
USE SQLStudy GO CREATE TABLE [dbo].[Test]( [ID] [int] NOT NULL, [First] [nchar](10) NULL, [Second] [nchar](10) NULL ) GO
接下来我们再来创建测试数据

INSERT INTO [SQLStudy].[dbo].[Test] ([ID],[First],[Second]) SELECT 1,'First1','Second1' UNION ALL SELECT 2,'First2','Second2' UNION ALL SELECT 3,'First3','Second3' UNION ALL SELECT 4,'First4','Second4' UNION ALL SELECT 5,'First5','Second5' GO
紧接着我们对表上的First和Second列创建聚集索引,如下
CREATE NONCLUSTERED INDEX [IX_MyTable_NonClustered] ON [dbo].[Test] (
[First] ASC,
[Second] ASC
)
此时我们来同时运行两个查询,看看其执行计划【注】:上一篇已经说过,请启用包括实际执行的计划。
SELECT ID FROM [dbo].[Test] WHERE [First] = 'First1' AND [Second] = 'Second1' SELECT Second FROM [dbo].[Test] WHERE [First] = 'First1' AND [Second] = 'Second1' GO
此时我们看到的执行计划如下:
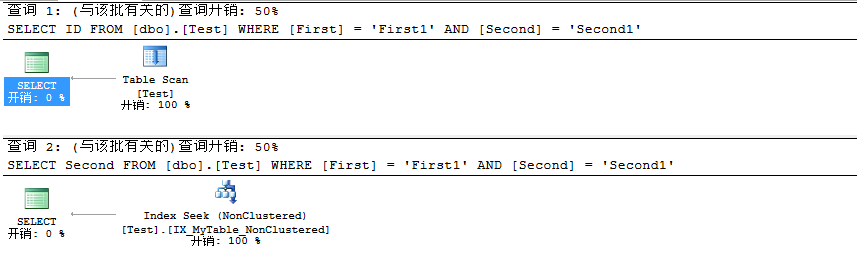
通过上述毫无疑问我们可以得出结论:查询1是利用的全表扫描,而查询2利用的非聚集索引查找。我们应该对于这个结论没有任何怀疑,因为要第二个查询的Second列在此之前已经创建额非聚集索引,而对于查询1中的ID则没有,所以会造成查询1的全表扫描,而查询2则是非聚集索引查找。
下面我们对表上的列ID创建聚集索引。
CREATE CLUSTERED INDEX [IX_MyTable_Clustered] ON [dbo].[Test] (
[ID] ASC
)
此时我们再来运行如下查询:
SELECT ID FROM [dbo].[Test] WHERE [First] = 'First1' AND [Second] = 'Second1' SELECT Second FROM [dbo].[Test] WHERE [First] = 'First1' AND [Second] = 'Second1' GO
此时再来看看查询执行计划:

通过上述我们对列ID创建了聚集索引,我们肯定能立马知道两者都是利用索引查找,确实没错,但是,但是你发现没有,睁大眼睛看看,我们明明在列ID上创建的是聚集索引,理论上应该是聚集索引查找才对啊,这就是我们本文所需要讨论的问题。
问题探讨
我们将问题进行如下概述,当我们在列上创建聚集索引时且查询返回该列,同时查询条件是创建了非聚集索引的列,此时对于创建了聚集索引的列的查询执行计划则是非聚集索引查找,这其中到底发生了什么?
实际发生的情况是非聚集索引内部引用了聚集索引, 当聚集索引被创建后在表中的数据会按照物理逻辑进行排序,当聚集索引没有被创建时此时非聚集索引指向的表中的数据并最终返回数据,但是一旦聚集索引创建了此时非聚集索引则会重建从而此时指向的是聚集索引,说到这里对于园友CareySon对于非聚集索引的描述:非聚集索引也是一个B树结构,与聚集索引不同的是,B树的叶子节点存的是指向堆或聚集索引的指针。概括的非常精准,若创建了聚集索引此时非聚集索引的指针则指向的是聚集索引,否则此时指向的是堆也就是表中的数据。所以此时在这种情况下,当查询创建了聚集索引的列时是进行了非聚集索引查找。
至此,我们可以得出结论:当在检索的列上创建了聚集索引时(仅仅返回创建聚集索引的列),此时查询不会使用聚集索引查找来检索结果而是使用非聚集索引查找来检索结果。
总结
个人觉得对于一个定义出来之前我们得首先抛出这样一个问题,如上述非聚集索引的定义:非聚集索引也是一个B树结构,与聚集索引不同的是,B树的叶子节点存的是指向堆或聚集索引的指针。初次看到这句感觉没什么,泛泛而谈,感觉似乎理解了,当遇到这样的问题时却不知所措,其实就是对定义理解的不够深入或者说不够透,当一个定义出来时你能举出这个定义的例子或者场景,那可能才算是真正了解了。本节我们到此结束,对于SQL这一系列会秉着简短的内容,深入的理解来讲解,同时也会循序渐进讲讲查询性能问题,由抛出问题到最终解决问题才算是收货多多。

为了方便大家在移动端也能看到我分享的博文,现已注册个人公众号,扫描上方左边二维码即可,欢迎大家关注,有时间会及时分享相关技术博文。
感谢花时间阅读此篇文章,如果您觉得这篇文章你学到了东西也是为了犒劳下博主的码字不易不妨打赏一下吧,让楼主能喝上一杯咖啡,在此谢过了!
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!
本文版权归作者和博客园共有,来源网址:http://www.cnblogs.com/CreateMyself)/欢迎各位转载,但是未经作者本人同意,转载文章之后必须在文章页面明显位置给出作者和原文连接,否则保留追究法律责任的权利。





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构