
【CSWS2014 Summer School】互联网广告中的匹配和排序算法-蒋龙(上)
Title:互联网广告中的匹配和排序算法
蒋龙博士,通联数据
Abstract:互联网广告是利用互联网提供的基础设施进行产品和服务营销的一种新形式,具有比传统广告方式更精准,成本收益更透明的优势。互联网广告是当今众多互联网企业实现价值变现的最主要形式之一,可以说,互联网广告产业是当今互联网能蓬勃发展的重要动力。
本次讲座将首先对互联网广告产业做一个简要的介绍,包括目前主流的几种广告模式,每种模式下主要的参与者及广告形态和特点。接下来分析几种主流广告模式中应用到的匹配和排序技术,包括搜索广告系统中的查询匹配算法,定向广告中的行为定向和个性化推荐技术,以及基于反馈数据的点击率预估系统。
Bio: 蒋龙,毕业于北京大学,现任通联数据首席数据科学家。曾任职于阿里巴巴集团,负责阿里妈妈事业部机器学习和排序,推荐和用户模型,基础算法和数据等团队。加入阿里之前曾任职微软亚洲研究院,从事自然语言处理、机器学习研究工作。主要感兴趣的领域包括机器学习,自然语言处理,互联网广告,量化投资等。
PS:以下照片并不包含全部PPT内容,仅包含个人感兴趣并认为有价值的PPT。
其中涉及的内容还是比较丰富的,但是不是十分详细,不过,大家可以从中了解一下工业界是如何解决一些实际问题的,同时能够了解一下我们所学的算法、模型是如何在实际中应用的。

Fig1,介绍了广告算法的基本策略,总结的很简单的两个步骤,也很容易理解。

Fig2,这幅图主要介绍了在搜索引擎广告系统(比如淘宝、京东、百度这种,你在搜索框输入Query[查询语句/词条],系统显示结果)中涉及的角色,下面我对其中几个不易明白的内容进行解释说明。
广告主:“买词”的意思就是购买关键词,当用户搜索该关键词,那么就会优先推荐竞价高的广告主的广告;
“为点击付费”就是说用户只要点击过广告主的广告,无论最终是否进行了交易,广告主都要付给搜索引擎一定的费用;
搜索引擎:“Query分析”就是对用户输入的文本进行分析
“展示搜索结果+广告”也就是说既要保证用户体验,又要做到广告推荐。

Fig3,GSP的意思就是,竞价排行最高的广告主,只需要支付竞价排行第二的广告主所提出的价格,比如以前会有这种情况,A出了500W,B出了300W,当A得知自己最高的时候,会逐渐降低自己的出价,而GSP方法就可以有效的避免这种麻烦的情况出现。
其中有一个推广质量,这个数值是为了解决这种情况,举个比较极端的例子,广告主A是汽车公司,广告主B是服装公司,双方可以购买适合自己领域的词,但是有可能A购买了服装领域的词W并且竞价比B高,这时候W在A领域的推广质量定不如在B领域的推广质量,因此在关键词为W的广告排序的时候,不一定是A的在第一个,而且收费也会随之进行相应调整。

Fig4,广告主ROI:广告主营销投资回报;其他内容,后边会有详细的介绍。

Fig5,针对用户错误或者不准确的输入,系统要有“自动纠错”的功能;

Fig6,从图中下方的图片可以看出“模糊匹配”的意思就是,用户的输入与广告主购买的关键词并不是完全一样,但是确实指向同一物品,这时候就需要“推荐系统”来推测用户想要什么。

Fig7,从上边的例子可以看出,用户输入的字符串如果太长,那么就要对其进行切分,找出中心词,修饰词,然后组成新的Query,再从系统中查询。
Term重要度计算模型,也就是说怎么计算中心词。【★,重要度计算,在科研中经常会遇到】
类目熵的意思就是,阿里内部有自己手工构建的商品类目知识库,根据这个知识库来计算重要度(具体怎么计算,没有详细说);
TF-IDF:词频-逆文档频率;

Fig8,这个的意思就是用户输入了一个Query,然后点击了一个广告,采集大量这种数据,就可以构造“Query-广告”的一个二部图(从定义可以很容易看懂这个图的组成)
原理:(1)如果两个Query连接到相似的广告,那么这两个Query也是相似的;(2)如果两个广告连接到相似的Query,那么这两个广告也是相似的。
【建议看一下推荐系统方面的书籍,推荐的方法中有很多有意思、有道理但是一般不会注意或者被想到的原理(我看的是《推荐系统实践》 项亮 著)】
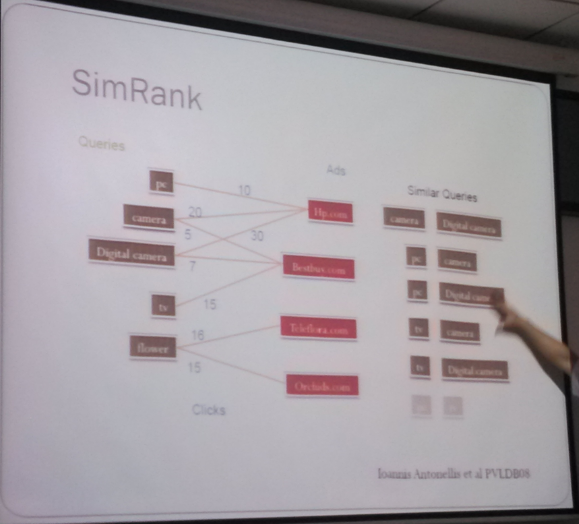
Fig9,左边是Query,右边是Ads,中间的边上的权重是Clicks;最右边是相似Query的结果;

Fig10,还是SimRank,其中提到的随机游走。。。我也不懂 - -!【★待学习】

Fig11,这个就是充分利用sessions中的信息进行Term改写(就是计算机网络中的那个“会话”)
1-7是用户输入的Query,可能第一次没找到满意的,就自己改了一下,后来又突然想找4的内容,然后又回去找之前的东西,这些用户行为都是可以通过Sessions来获取的。

Fig12,查询日志的数据挖掘,在Query Segmentation部分的那个相关性,其实就很类似与共现了,A和B就是相邻Query;但是其中的符号“>>”,应该是远大于的意思,所以我不太明白上边的意思。。。
假设检验的方法验证A和B是否独立,H1的情况表示独立,H2的情况表示不独立;

Fig13,基于N-gram的term替换方法,其中的“#”代表“诺基亚”,对应的3-gram就是:新款-红色-诺基亚,红色-诺基亚-手机

Fig14,计算Query和广告的相关性,类似于信息检索中计算网页和查询的相关性。【★SVM模型】
====================广告众多分类中的两个分类=======================
(搜索广告:百度、淘宝、京东这种大型电商网站,用“搜索引擎”做广告)
(展示广告:比如新浪新闻首页,这种非专门做广告的网站,只能在用户浏览一些内容的时候,顺便展示一些广告)
==========================================================

Fig15,展示广告的一个目录,下面主要介绍三种方式

Fig16,很容易理解。

Fig17,很容易理解。

Fig18,无法直接确定,那么就可以利用语义信息(广告类别、网页类别等等)进行决策。

找我内推: 字节跳动各种岗位
作者:
ZH奶酪(张贺)
邮箱:
cheesezh@qq.com
出处:
http://www.cnblogs.com/CheeseZH/
*
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

