
软工-结对作业2
软工1816 · 第五次作业 - 结对作业2
优秀的结对队友:乐忠豪
分工明细
- 分工如下
- 蔡子阳:完成全部爬虫实现及附加题全部内容
- 乐忠豪:使用C++实现其余需求功能
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 90 | 150 |
| · Estimate | · 估计这个任务需要多少时间 | 90 | 150 |
| Development | 开发 | 780 | 740 |
| · Analysis | · 需求分析 (包括学习新技术) | 200 | 240 |
| · Design Spec | · 生成设计文档 | 0 | 0 |
| · Design Review | · 设计复审 | 10 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| · Design | · 具体设计 | 60 | 90 |
| · Coding | · 具体编码 | 360 | 180 |
| · Code Review | · 代码复审 | 30 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 150 |
| Reporting | 报告 | 25 | 40 |
| · Test Repor | · 测试报告 | 0 | 0 |
| · Size Measurement | · 计算工作量 | 5 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 30 |
| | 合计 |895 |930
解题思路描述与设计实现说明
1.爬虫实现及使用
- 用python代码编写爬虫
首先先对论文列表网页爬取每篇论文的网址
def getWebInfo(url):#获取网页中的内容
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
except:
print("request error")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
return soup
url = "http://openaccess.thecvf.com/CVPR2018.py"
soup = getWebInfo(url)
papersInfo = soup.find_all('dt')#每篇论文的网址形成的list
然后对每一篇论文的网页爬取相对应信息并进行正则表达式去除网页标签最后获得标题和摘要并写入到文件中
def getPaperInfo(paperLink):#获取论文主页的内容
url = "http://openaccess.thecvf.com/" + paperLink
soup = getWebInfo(url)
re_h=re.compile('</?\w+[^>]*>')#HTML标签
#利用正则表达式去除网页内容中的标签
title =re_h.sub('', str(soup.find('div',id="papertitle"))).strip()
abstract = re_h.sub('',str(soup.find('div',id="abstract"))).strip()
author = re_h.sub('',str(soup.find('i'))).strip().split(', ')
return title,abstract,author
with open(filename,'w',encoding='utf-8') as outfile:
for paperInfo in papersInfo:
title,abstract,author = getPaperInfo(paperInfo.find('a').get('href'))
outfile.write(str(i)+'\r\n')
i = i+1
outfile.write('Title: '+title+'\r\n')
outfile.write('Abstract: '+abstract+'\r\n\r\n\r\n')
2.代码组织与内部实现设计
- C++部分:原先计划使用一个论文类存储论文信息,但是在需求分析的时候发现这次的作业并不需要存储论文信息,所以直接使用字符串对文本进行分析统计。
-
结构图如下:

-
组织结构:根据需求实现4个功能(词频统计、行数统计、单词数统计、字符数统计),共4个头文件分别实现。函数接口如下:
-
int CountWords(char *filename) //统计单词数
int CountLines(char *filename) //统计行数
int CountChars(char *filename) //统计字符数
void CountWf(char *filename, ofstream &fout,char* outfile,int topNum,int itemLenth,int weight_Pid)
//词频统计,topNum为输出的词项数目,itemLenth为词项长度,weight_Pid为标题权重开关
3.说明算法的关键与关键实现部分流程图
- C++关键算法:
- 算法说明:
- 除了词频统计外其余三个函数实现简单,只需注意细节即可(如Title: 等不作为单词及字符看待等)。
- 词频统计和上次个人项目大同小异,用map容器实现,而且其实现方式为红黑二叉树,存储效率不低,复杂度为O(nlogn),针对排序使用vector容器辅助堆排序实现。要求输出前K个词项,时间复杂度为O(nlogK),
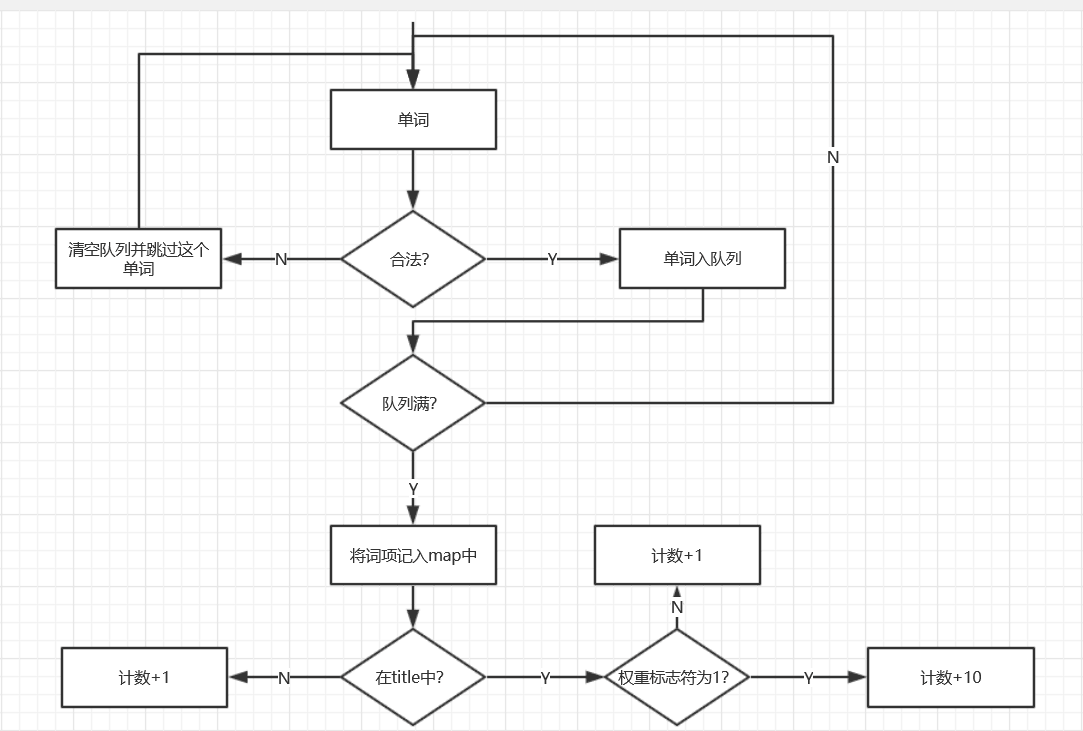
- 与上次作业有所不同的是不仅仅是单词,而是词项的统计,这里引入list队列容器,检测到一个合法单词则入队尾,若符合词项要求则输出队列内容,并令队首出队列。若碰到不合法单词则将当前队列清空。时间复杂度为O(n),与单词的词频统计耗费时间相差无几。
- 词频统计关键代码及流程图展示:
- 算法说明:
//为了节省篇幅仅展示部分代码
void CountWF(char *filename, ofstream &fout,char* outfile,int topNum,int itemLenth,int weigth_Pid)
{
int num = 0;
K = topNum;
ifstream in(filename); // 打开文件
if (!in)
{
cerr << "无法打开输入文件" << endl;
exit(0);
}
char readLine[100000];
string tempLine;
list<string> listString;
while (in.getline(readLine, 100000))//逐行处理文件
{
tempLine = readLine;//存储当前行的字符串
if (tempLine.length()<6) //论文序号
{
b.clear();
continue;
}
else if (readLine[0] == 'T'&&readLine[1] == 'i'&&readLine[2] == 't'&&readLine[3] == 'l'&&readLine[4] == 'e')//Title字段
{
Count(tempLine, itemLenth, 7,weigth_Pid);
}
else if (readLine[0] == 'A'&&readLine[1] == 'b'&&readLine[2] == 's'&&readLine[3] == 't'&&readLine[4] == 'r'&&readLine[5] == 'a'&&readLine[6] == 'c'&&readLine[7] == 't')//Abstract字段
{
Count(tempLine, itemLenth, 10, weigth_Pid);
}
else if(readLine)
{
Count(tempLine, itemLenth, 0,weigth_Pid);
}
}
if (essay.size() < K)K = essay.size();
vector < map<string, int> ::iterator> top(K, essay.begin());
topK(essay, top, fout,outfile);//堆排序算法
}
//队列使用
list<string> b('\0');
list<string>::iterator it1;
if (char_Count >= 4) //若是合法单词,则记录
{
char words[100] = { "\0" }; //单词存储
for (int k = i; k < i + count; k++)
{
words[k - i] = tempLine[k];
}
string s = words;//单词存入字符串中
b.push_back(s); //推入队列尾
s = "\0";
if (b.size() == MaxNum)//队列满
{
int nowNum = MaxNum;//当前队列长度
for (it1 = b.begin(); it1 != b.end(); it1++)
{
s.append(*it1);
nowNum--;
if (nowNum != 0)s.append(" ");
}
if(head==7&&weight_Pid==1)essay[s]+=10;//记录词组/单词
else essay[s]++;
b.pop_front(); //队首出队列
s = "\0";
}
i += count - 1;
}
else if (count > 0 && count < 4) //若遇到不合法单词情况队列
{
b.clear();
i += count - 1;
}
else continue;
}
if (head == 7)b.clear(); //若是Title字段结束时情况队列
词项/单词 词频统计流程图
附加题设计与展示
- 爬取作者信息
在getPaperInfo函数中加入如下代码
author = re_h.sub('',str(soup.find('i'))).strip().split(', ')
就能得到作者的信息

- 作者之间的联系图
将每个作者出现的次数写入到文件中,形成点集

将同时出现的作者以及出现的次数写入到文件中,以三元组形式,形成边集

代码如下
authors = []
i = 0
for paperInfo in papersInfo:#每篇论文的作者list的形式放入authors当中
title,abstract,author = getPaperInfo(paperInfo.find('a').get('href'))
authors.append(author)
for each in authors:#将同时出现的两个作者形成元组,放入到字典当中,并进行计数
for author1 in each:
for author2 in each:
if (author1,author2) not in relationships:
relationships[(author1,author2)] = 1
else:
relationships[(author1,author2)] = relationships[(author1,author2)] + 1
有了点集和边集后,用Gephi工具,将两个文本文档传然后就能形成作者之间的联系图了

这是总的作者联系图,因为作者太多,所以会很密集

这是放大后的图,每个点都是一个作者,作者之间的联系粗细大小代表同时出现的频率,越粗的线代表频率越高
性能分析与改进
- 测试文本为100w+字符数,花费时间在3s左右,运行结果如下:

- VS的性能分析工具来看将检测到的单词/词项存入map容器是最花时间的,分析结果如下:

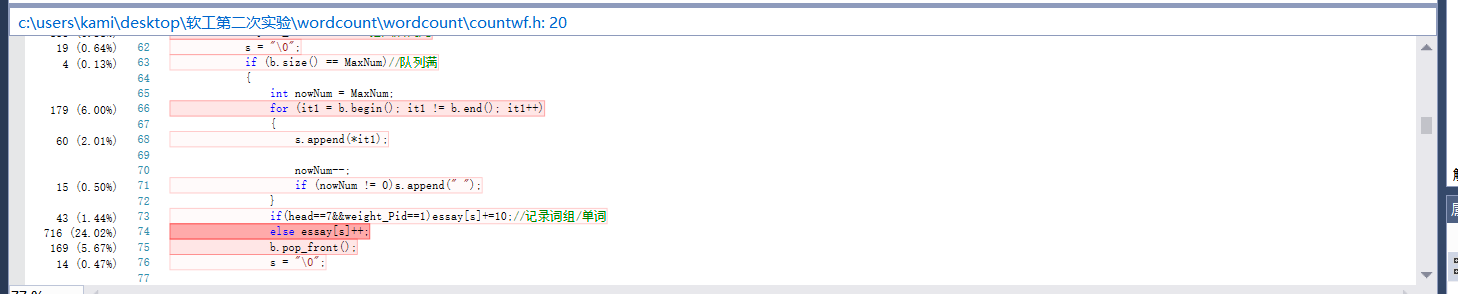
为了解决它想到之前将map改为unordered_map能减少一半的时间花费,但是这次花费时间差不多,结果如下:

除此之外其余花费时间较多的语句多为判断语句。。不知道应该怎么再改进了。
单元测试
- 构造测试数据思路
- 测试用例包括作业上的两个用例及对不同命令行参数的设置。
- 很惭愧的一点是没有使用VS写单元测试代码进行测试,仅仅手动改动输入文件和命令行参数进行测试。测试函数包括四个需求(行数、字符数、单词数、词频输出)
Github的代码签入记录
由于这次作业是在上一次的基础上进行改动,所以签入次数较少,bug都是在最后关头发现的(其实是原来就有然后想偷懒没有改,最后良心发现才改了)

遇到的代码模块异常或结对困难及解决方法
- 问题描述:C++程序无法读取爬虫的结果文件然后程序崩溃
- 做过的尝试:
- 发现爬虫文件为Unicode编码,C++无法识别,所以将文本改为Ascll编码(没有解决)
- 发现读取的文本Abstract字段不管有多少行都算作一行,尝试自动添加换行符解决(失败)
- 最后发现是C++程序中读取每行使用的Char[]容量过小无法读取Abstarct的全部内容导致崩溃,通过增大容量解决(暂时成功)
- 通过各种尝试终于解决啦
- 收获:细节决定成败。。。但是其实盲目增大容量的做法是很不可取的,改为动态开辟空间应该会好很多。
我的队友
我的队友是个可靠的小伙伴,是个深藏不漏的大佬,是个6到飞起的人。

