
在GRAPHQL服务器中修复性能问题
在GraphQL中暴露API允许前端容易构建数据的任何视图,并且仅请求该视图所需的数据。后端可以用dataloader高效地查询数据库。
在上周,我注意到前台响应很慢。查询对后端占用了5秒钟以上,超时。这使得UI几乎不可用,所以我查看了一下。
我的第一站是主机指标:
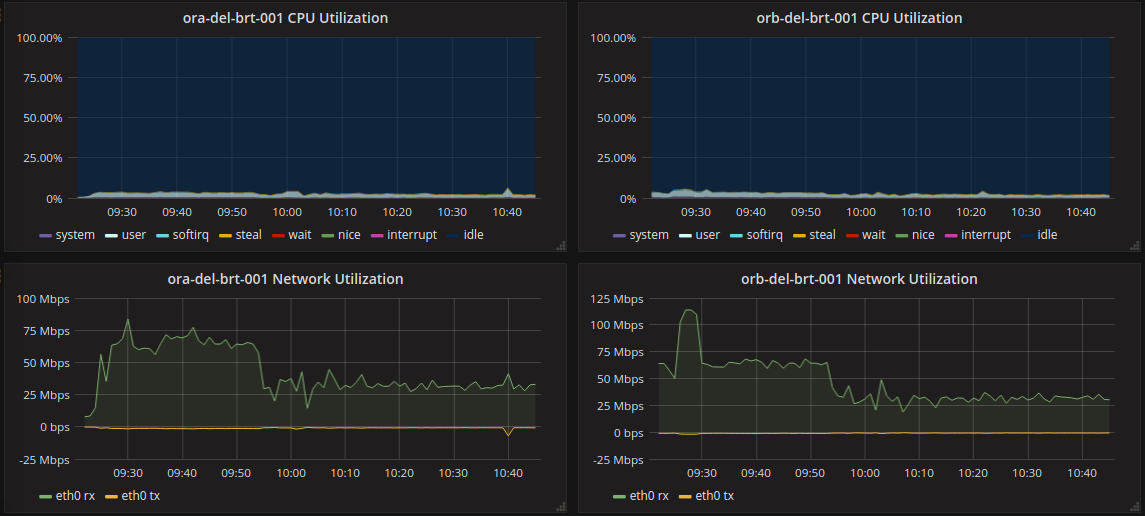
这些指标没有什么可以立即跳出我的怀疑。CPU看起来不错,没有什么是最大或尖峰,所以我转到数据库。实例很小,也许是过度担心了?不幸的是,对于我的调查,数据库指标也看起来很好,所以我去了主机指标。经过思考,网络流量开始看起来很可疑。考虑到这个服务器的大部分工作是查询数据库并将结果格式化回到前端,rx(接收到的字节)应该大致匹配tx(发送的字节)。在上图中,每个主机正在接收30 mbps,只发送0.7 mbps。显然,我们要求数据库中的东西在被发送到前端之前被丢弃。
这个应用程序中最常见的屏幕是:
要显示该页面,前端将使用以下graphql查询来询问所有管道实例及其中的步骤:
pipeline(id: 1) {
pipeline_instances {
version
pipeline_steps {
Type
name
inProgress
error
completed
}
}
}
此查询每打开一个浏览器标签每3秒运行一次,因此可以向用户显示更新。当您单击单个步骤时,它将被扩展,并开始轮询另一个查询并附加详细信息。
这里最相关的补充是日志:
pipeline_step(id: 1) {
type
name
inProgress
error
completed
logs
}
这是GraphQL正好按设计工作。前端只需要它需要的字段。
在考虑后端从数据库中抛出什么数据的同时,我记得后端没有像前端在与数据库通信时一样的进行。每次请求任何项目时,应用程序SELECT *将从数据库中获取所有字段。在管道步骤的情况下,这包括日志,这些日志通常可能非常大。考虑到主查询将加载每个流水线实例中每个步骤的每个日志,我感到这些日志表示被丢弃的数据。无论这是否是性能问题,我都不知道,但是不能修复。
要实现此修复,首先我更改了流水线步骤的默认负载,不包括日志。这些数据在后端没有使用,所以安全地从默认对象中删除。这意味着更改SELECT *替换*除了对象之外的对象的所有字段的列表logs领域。接下来,我不得不将这些日志重新添加到请求它们的graphql查询中。我添加了一个单独的dataloader,只会选择日志字段。虽然这将导致对要求日志的客户端进行额外的数据库查询,但是它们在少数情况下,当通过主键ID请求单个行时,调用非常快。这种变化对客户来说是透明的,完全向后兼容。我不认为这可能是几乎没有像graphql这样容易的可能。它将需要两个新的端点或现有端点的附加参数化以及客户端代码更改。
结果
一旦这个新的代码被部署,结果是戏剧性的。
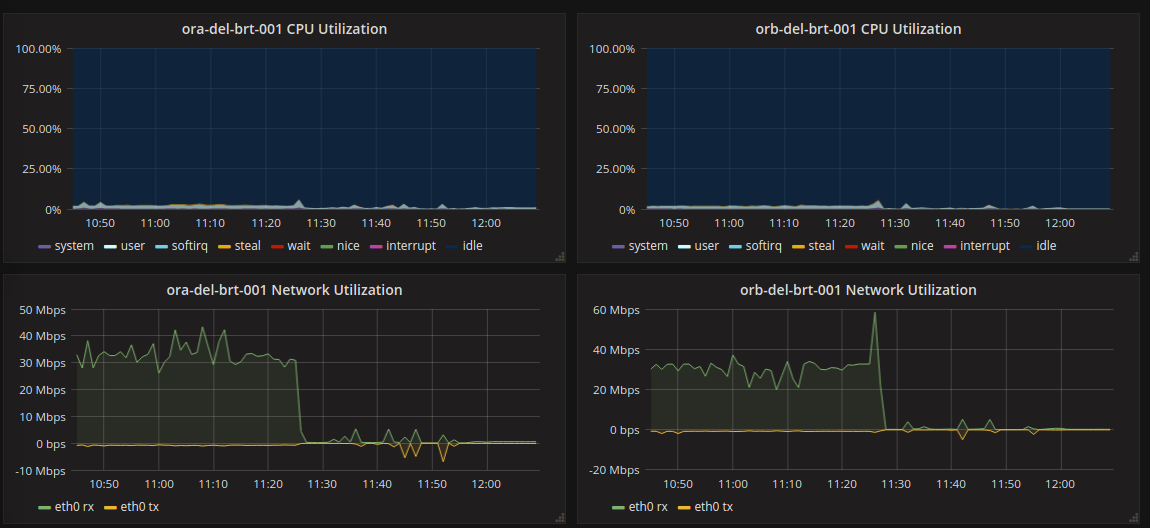
rx马上掉下悬崖。正在使用5+秒的相同查询现在在50ms内完成,性能问题已经解决。看来,瓶颈是将查询结果从数据库传输到API服务器。这表明db.t2.micro实例类型具有“低”的非特定网络性能实际上提供了约70mbps的容量。这与我在AWS的其他地方看到的一致。如果无法减少带宽,我可能不得不升级实例类型,只是为了更好的网络。同样地,GraphQL的灵活性和声明性使得性能问题容易解决。
-----Brasrom
