
[原] KVM 虚拟化原理探究(6)— 块设备IO虚拟化
KVM 虚拟化原理探究(6)— 块设备IO虚拟化
标签(空格分隔): KVM
块设备IO虚拟化简介
上一篇文章讲到了网络IO虚拟化,作为另外一个重要的虚拟化资源,块设备IO的虚拟化也是同样非常重要的。同网络IO虚拟化类似,块设备IO也有全虚拟化和virtio的虚拟化方式(virtio-blk)。现代块设备的工作模式都是基于DMA的方式,所以全虚拟化的方式和网络设备的方式接近,同样的virtio-blk的虚拟化方式和virtio-net的设计方式也是一样,只是在virtio backend端有差别。
传统块设备架构
块设备IO协议栈

如上图所示,我们把块设备IO的流程也看做一个TCP/IP协议栈的话,从最上层说起。
Page cache层,这里如果是非直接IO,写操作如果在内存够用的情况下,都是写到这一级后就返回。在IO流程里面,属于writeback模式。 需要持久化的时候有两种选择,一种是显示的调用flush操作,这样此文件(以文件为单位)的cache就会同步刷到磁盘,另一种是等待系统自动flush。
VFS,也就是我们通常所说的虚拟文件系统层,这一层给我们上层提供了统一的系统调用,我们常用的create,open,read,write,close转化为系统调用后,都与VFS层交互。VFS不仅为上层系统调用提供了统一的接口,还组织了文件系统结构,定义了文件的数据结构,比如根据inode查找dentry并找到对应文件信息,并找到描述一个文件的数据结构struct file。文件其实是一种对磁盘中存储的一堆零散的数据的一种描述,在Linux上,一个文件由一个inode 表示。inode在系统管理员看来是每一个文件的唯一标识,在系统里面,inode是一个结构,存储了关于这个文件的大部分信息。这个数据结构有几个回调操作就是提供给不同的文件系统做适配的。下层的文件系统需要实现file_operation的几个接口,做具体的数据的读写操作等。
struct file_operations {
//文件读操作
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
//文件写操作
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
int (*readdir) (struct file *, void *, filldir_t);
//文件打开操作
int (*open) (struct inode *, struct file *);
};
再往下就是针对不同的文件系统层,比如我们的ext3,ext4等等。 我们在VFS层所说的几个文件系统需要实现的接口,都在这一层做真正的实现。这一层的文件系统并不直接操作文件,而是通过与下层的通用块设备层做交互,为什么要抽象一层通用块设备呢?我们的文件系统适用于不同的设备类型,比如可能是一个SSD盘又或者是一个USB设备,不同的设备的驱动不一样,文件系统没有必要为每一种不同的设备做适配,只需要兼容通用快设备层的接口就可以。
位于文件系统层下面的是通用快设备层,这一层在程序设计里面是属于接口层,用于屏蔽底层不同的快设备做的抽象,为上层的文件系统提供统一的接口。
通用快设备下层就是IO调度层。用如下命令可以看到系统的IO调度算法.
➜ ~ cat /sys/block/sda/queue/scheduler
noop deadline [cfq]
-
noop,可以看成是FIFO(先进先出队列),对IO做一些简单的合并,比如对同一个文件的操作做合并,这种算法适合比如SSD磁盘不需要寻道的块设备。
-
cfq,完全公平队列。此算法的设计是从进程级别来保证的,就是说公平的对象是每个进程。系统为此算法分配了N个队列用来保存来自不同进程的请求,当进程有IO请求的时候,会散列到不同的队列,散列算法是一致的,同一个进程的请求总是被散列到同一个队列。然后系统根据时间片轮训这N个队列的IO请求来完成实际磁盘读写。
-
deadline,在Linux的电梯调度算法的基础上,增加了两个队列,用来处理即将超时或者超时的IO请求,这两个队列的优先级比其他队列的优先级较高,所以避免了IO饥饿情况的产生。
块设备驱动层就是针对不同的块设备的真实驱动层了,块设备驱动层完成块设备的内存映射并处理块设备的中断,完成块设备的读写。
块设备就是真实的存储设备,包括SAS,SATA,SSD等等。块设备也可能有cache,一般称为Disk cache,对于驱动层来说,cache的存在是很重要的,比如writeback模式下,驱动层只需要写入到Disk cache层就可以返回,块设备层保证数据的持久化以及一致性。
通常带有Disk cache的块设备都有电池管理,当掉电的时候保证cache的内容能够保持一段时间,下次启动的时候将cache的内容写入到磁盘中。
块设备IO流程
应用层的读写操作,都是通过系统调用read,write完成,由Linux VFS提供的系统调用接口完成,屏蔽了下层块设备的复杂操作。write操作有直接IO和非直接IO之分(缓冲IO),非直接IO的写操作直接写入到page cache后就返回,后续的数据依赖系统的flush操作,如果在flush操作未完成的时候发生了系统掉电,那可能会丢失一部分数据。直接IO(Direct IO),绕过了page cache,数据必须达到磁盘后才返回IO操作完成。
对于I/O的读写流程,逻辑比较复杂,这里以写流程简单描述如下:
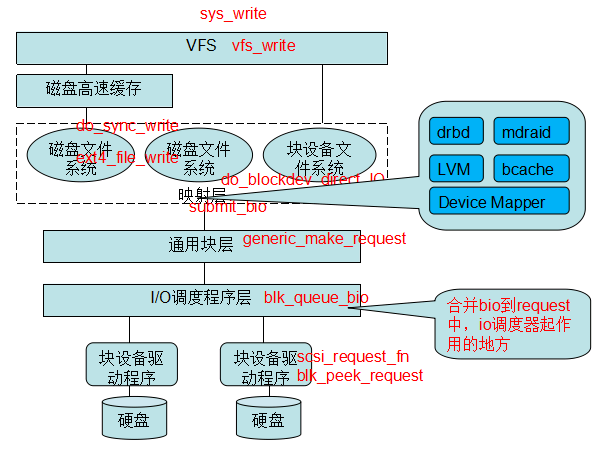
- 用户调用系统调用write写一个文件,会调到sys_write函数;
- 经过VFS虚拟文件系统层,调用vfs_write,如果是缓存写方式,则写入page cache,然后就返回,后续就是刷脏页的流程;如果是Direct I/O的方式,就会走到块设备直接IO(do_blockdev_direct_IO)的流程;
- 构造bio请求,调用submit_bio往具体的块设备下发请求,submit_bio函数通过generic_make_request转发bio,generic_make_request是一个循环,其通过每个块设备下注册的q->make_request_fn函数与块设备进行交互;
- 请求下发到底层的块设备上,调用块设备请求处理函数__make_request进行处理,在这个函数中就会调用blk_queue_bio,这个函数就是合并bio到request中,也就是I/O调度器的具体实现:如果几个bio要读写的区域是连续的,就合并到一个request;否则就创建一个新的request,把自己挂到这个request下。合并bio请求也是有限度的,如果合并后的请求超过阈值(在/sys/block/xxx/queue/max_sectors_kb里设置),就不能再合并成一个request了,而会新分配一个request;
- 接下来的I/O操作就与具体的物理设备有关了,块设备驱动的读写也是通过DMA方式进行。

如上图所示,在初始化IO设备的时候,会为IO设备分配一部分物理内存,这个物理内存可以由CPU的MMU和连接IO总线的IOMMU管理,作为共享内存存在。以一个读取操作为例子,当CPU需要读取块设备的某个内容的时候,CPU会通过中断告知设备内存地址以及大小和需要读取的块设备地址,然后CPU返回,块设备完成实际的读取数据后,将数据写入到共享的内存,并以中断方式通知CPU IO流程完成,并设置内存地址,接着CPU直接从内存中读取数据。
写请求类似,都是通过共享内存的方式,这样可以解放CPU,不需要CPU同步等待IO的完成并且不需要CPU做过多的运算操作。
因为块设备IO的虚拟化需要经过两次IO协议栈,一次Guest,一次HV。所以需要把块设备IO协议栈说的很具体一点。
至此,Linux块设备的IO层就基本介绍完整了,以上内容也只是做一个简单的介绍,这部分的内容可以很深入的去了解,在此限于篇幅限制,就不做过多介绍了。
块设备IO虚拟化
块设备的全虚拟化方式和网络IO的DMA设备虚拟化方式类似,这里就不过多介绍了,主要介绍一下virtio-blk。

如上图所示,块设备IO的虚拟化流程和网络IO的流程基本一致,差别在于virtio-backend一段,virtio-net是写入到tap设备,virtio-blk是写入到镜像文件中。
块设备IO的流程需要经过两次IO协议栈,一次位于Guest,一次位于HV。当我们指定virtio的cache模式的时候,实际上指定的是virtio-backend(下面简称v-backend)写入HV块设备的方式。
在虚拟化层次来看,Guest对于这几种Cache模式是没有感知的,也就是无论Cache模式是怎样,Guest都不会有所谓的绕过Guest的Page cache等操作,Virtio-front模拟的是驱动层的操作,不会涉及到更上层的IO协议栈。
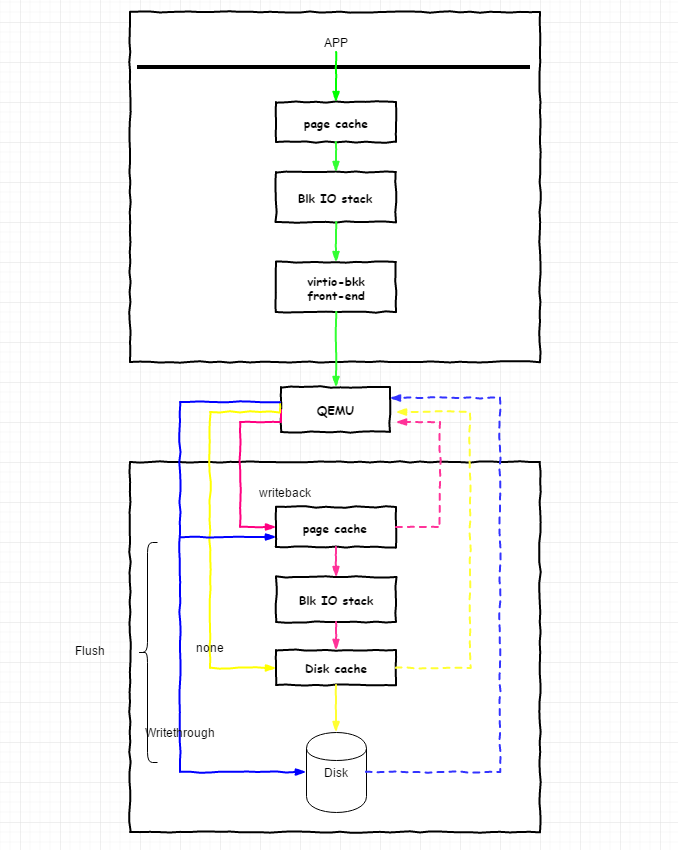
如上图所示,蓝色表示 writethrough,黄色表示 none,红色表示 writeback。其中虚线表示写到哪一个层次后write调用返回。
-
cache=writethrough (蓝色线)
表示v-backend打开镜像文件并写入时候采用非直接IO+flush操作,也就是说每次写入到Page cache并flush一次,直到数据被真实写入到磁盘后write调用返回,这样必然会导致数据写入变慢,但是好处就是安全性较高。 -
cache=none (黄色线)
cache为none模式表示了v-backend写入文件时候使用到了DIRECT_IO,将会绕过HV的Page cache,直接写入磁盘,如果磁盘有Disk cache的话,写入Disk cache就返回,此模式的好处在于保证性能的前提下,也能保证数据的安全性,在使用了Disk cache电池的情况下。但是对于读操作,因为没有写入HV Page cache,所以会有一定性能影响。 -
cache=writeback (红色线)
此模式表示v-backend使用了非直接IO,写入到HV的Page后就返回,有可能会导致数据丢失。
总结
块设备IO的虚拟化方式也是统一的virtio-x模式,但是virtio-blk需要经过两次IO协议栈,带来了不必要的开销。前面的铺垫都是为了介绍三种重要的cache模式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号