

Python学习【第二篇】Python入门
Python入门
Hello World程序
在linux下创建一个叫hello.py,并输入
print("Hello World!")
然后执行命令:python hello.py ,输出:
# vim hello.py # python hello.py Hello World!
Python内部执行过程如下:
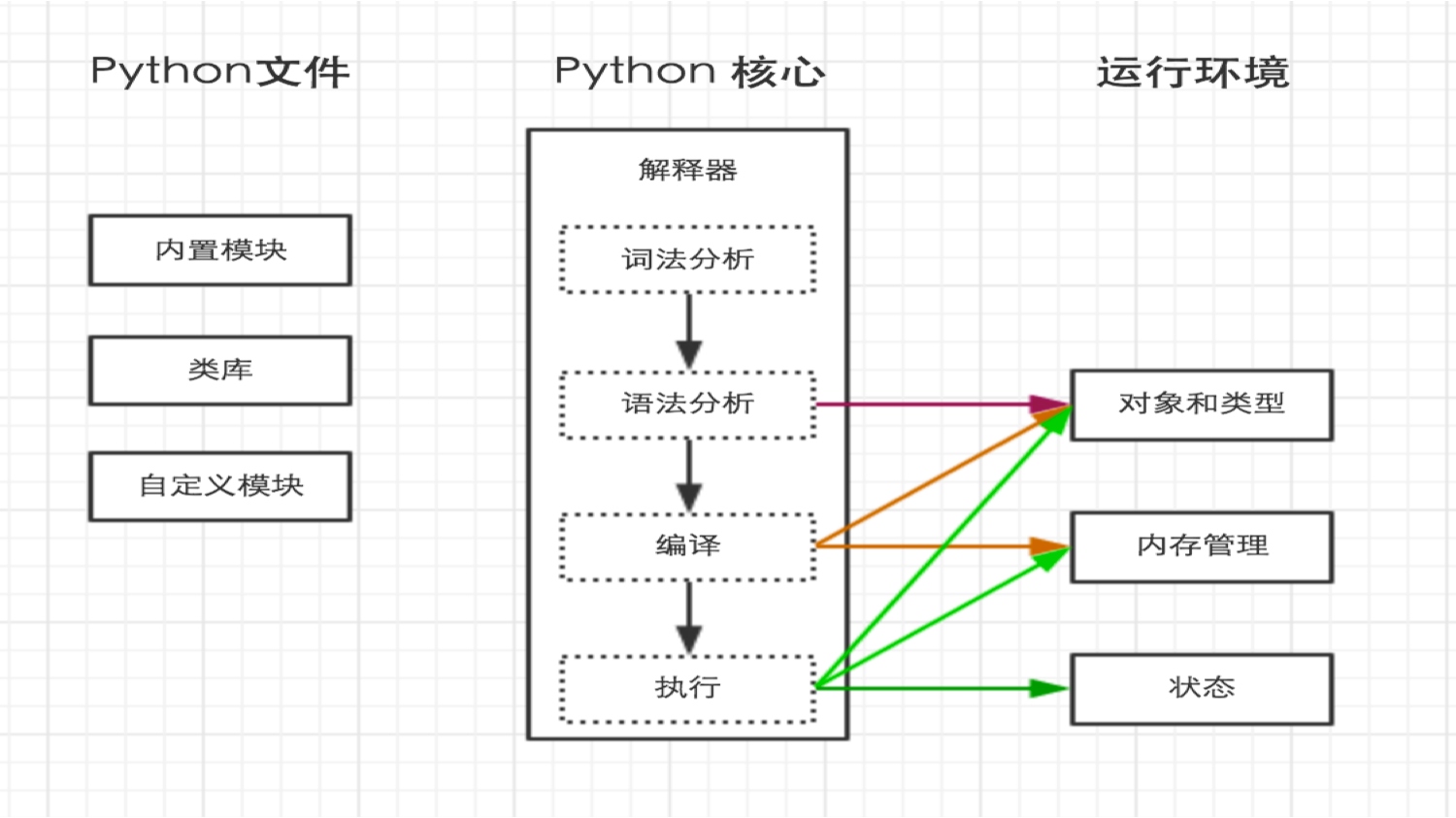
指定解释器
上一步中执行python hello.py 时,明确的指出hello.py脚本由python解释器来执行。
如果想要类似于执行shelljiaoben一样执行python脚本,例如:./hello.py ,那么我们就需要在hello.py文件头部指定解释器,如下:
#!/usr/bin/env python print "hello,world"
如此一来,执行: ./hello.py 即可。
ps:执行前需给予 hello.py 执行权限,chmod 755 hello.py
在交互器中执行
除了把程序写在文件里,还可以直接调用Python自带的交互器运行代码,
# python
Python 2.7.10 (default, Oct 23 2015, 18:05:06)
[GCC 4.2.1 Compatible Apple LLVM 7.0.0 (clang-700.0.59.5)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> print("Hello World!")
Hello World!
内容编码
Python解释器在加载.py文件中的代码时,会对内容进行编码(默认ascill)
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用8位来表示(一个字节),即:2**8=256,所以,ASCII码最多只能表示255个符号。

显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要更新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定所有的字符和符号最少由16位来表示(2个字节),即:2**16=65536,
注:此处说的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,它不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ASCII码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存......
所以,python解释器在加载.py文件中的代码是,会对内容进行编码(默认ASCII),如果是如下代码的话:
报错:ascii码无法表示中文
#!/usr/bin/env python print "你好,世界"
改正:应该告诉python解释器,用什么编码来执行源代码,即:
#!/usr/bin/env python # -*- coding: utf-8 -*- print "你好,世界"
注意:Python2需要指定字符集,但在python3中就支持万国编码,不需要再指定,默认支持中文。
注释
当行注释:
#被注释的内容 #开发规范:(每一行最多不能超过80个字符)
多行注释:
''' 被注释的内容 '''
初识模块
Python的强大之处在于它有非常非常丰富和强大的库,几乎你想实现的任何功能都有相应的Python库支持,从而使得开发Python程序非常简洁。类库包括三种:
·python内部提供的模块
·业内开源的模块
·程序员自己开发的模块
现在,我们先来象征性的学习两个简单的。
sys
#!/usr/bin/env python import sys print(sys.argv) # 输出 $ python test.py helo world ['test.py', 'helo', 'world'] #把执行脚本时传递的参数获取到了
os
#!/usr/bin/env python
import os
os.system("df -h") #调用系统命令
完全结合一下
import os,sys
os.system(''.join(sys.argv[1:])) #把用户的输入的参数当作一条命令交给os.system来执行
自己写一个模块
python tab补全模块


1 #!/usr/bin/env python 2 # python startup file 3 import sys 4 import readline 5 import rlcompleter 6 import atexit 7 import os 8 # tab completion 9 readline.parse_and_bind('tab: complete') 10 # history file 11 histfile = os.path.join(os.environ['HOME'], '.pythonhistory') 12 try: 13 readline.read_history_file(histfile) 14 except IOError: 15 pass 16 atexit.register(readline.write_history_file, histfile) 17 del os, histfile, readline, rlcompleter
1 import sys 2 import readline 3 import rlcompleter 4 5 if sys.platform == 'darwin' and sys.version_info[0] == 2: 6 readline.parse_and_bind("bind ^I rl_complete") 7 else: 8 readline.parse_and_bind("tab: complete") # linux and python3 on mac
写完后就可以保存使用了
localhost:~ jieli$ python Python 2.7.10 (default, Oct 23 2015, 18:05:06) [GCC 4.2.1 Compatible Apple LLVM 7.0.0 (clang-700.0.59.5)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import tab
你会发现,上面自己写的tap.py模块只能在当前目录下导入,如果想在系统的任何一个地方都使用怎么办?此时你就要把这个tab.py放到python全局环境变量目录里啦,基本一般都放在一个叫 Python/2.7/site-packages 目录下,这个目录在不同的OS里放的位置不一样,用 print(sys.path) 可以查看python环境变量列表。
.pyc是什么鬼?
执行python代码时,如果导入了其他的.py文件,那么,执行过程中会自动生成一个与其同名的.pyc文件,该文件就是Python解释器编译之后产生的字节码。
当Python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则重复上面的过程。
ps:代码经过编译可以产生字节码;字节码通过反编译也可以得到代码。
