


《BI那点儿事》数据流转换——模糊分组转换
在模糊查找中我们提到脏数据是怎样进入到表中的事情,主要还是由于一些“Lazy-add”造成的。这种情况我们的肉眼很容易被欺骗,看上去是同一个单词,其实就差那么一个字母,变成了两个不同的单词。一个简单的例子是X-Ray Tech和xRey,我们很有可能认为他们是同一个职务,CT操作员,但是如果让计算机来处理的话,它们是两种截然不同的东西。
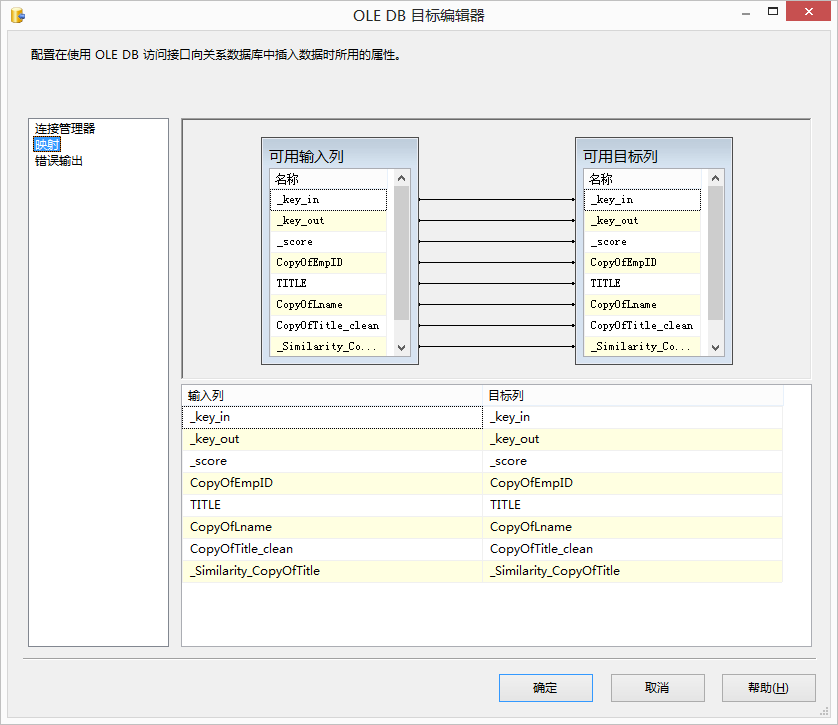
和模糊查找一样,模糊分组可以查找出多行中出现的类似的单词进行归类。我们可以使用这些归类得到的结果清洗数据源或者在不修改基础数据的情况下对原表进行修改。模糊分组也需要一个输入字符流,还需要一个OLE DB数据连接,用于存放分析得到的结果。
模糊分组任务的编辑界面有下面三个标签
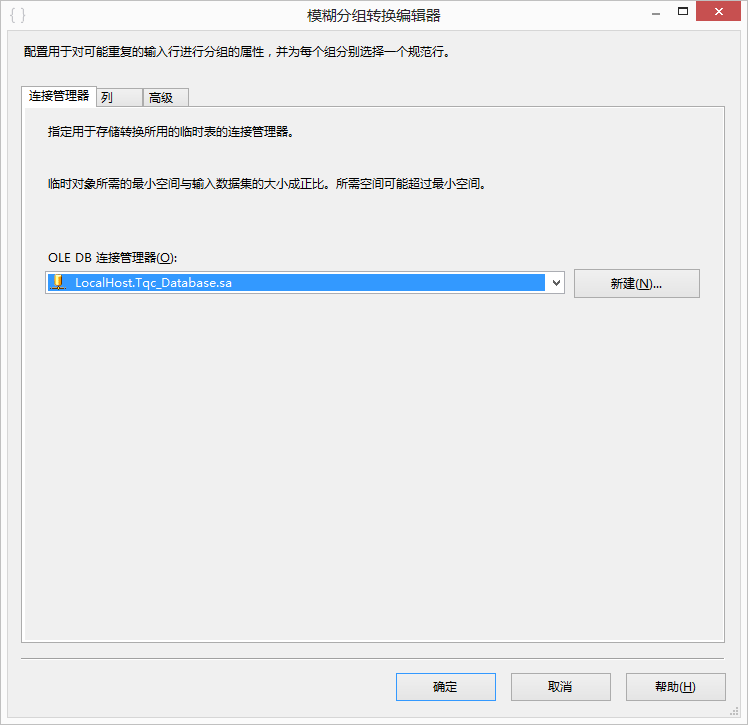
- 连接管理:这个标签用来设置OLE DB连接,在这个连接的数据库中存放分组结果,这个标签和前面提到的是一样的效果
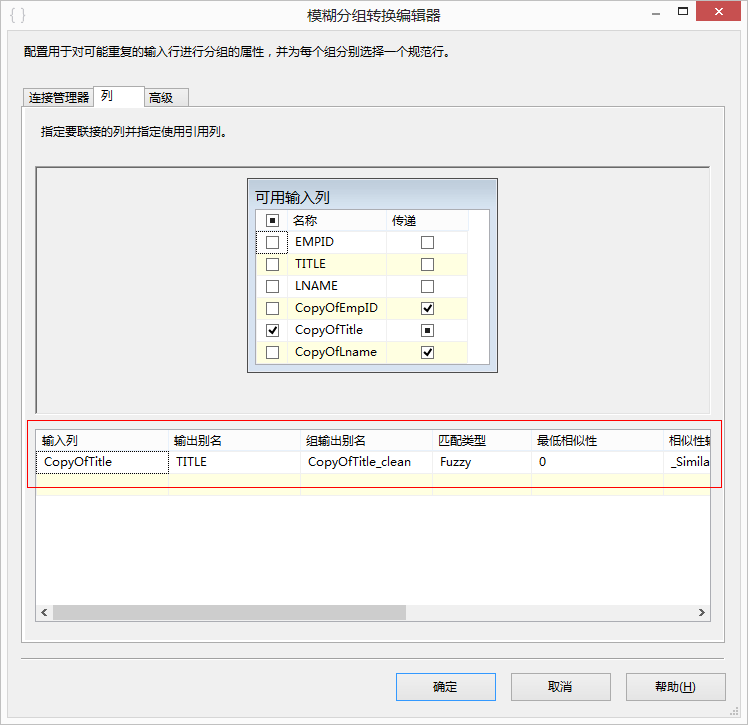
- 列:这个标签显示输入流中的列,在这里需要选择一些需要进行模糊分组的列。每一个被选中的列将会被分析,产生一些新的结果列。如果没有选择的话,这些列将会被标记为PassThrow列,意思是不进行模糊分组,直接将导出到输出流中。在这里也可以根据自己的意愿修改Group Output Alias,Output Alias,CleanMatch和Similarity Alias的名字。Numerals选项,如图2,这个选项有前导,后导,前导和后导,不用前导后导,四个选项。在对类似地址的一些数据进行模糊分组的时候这个选项会很有用。最后有一个Comparison flags选项可以设置忽略大小写,忽略符号等设置。
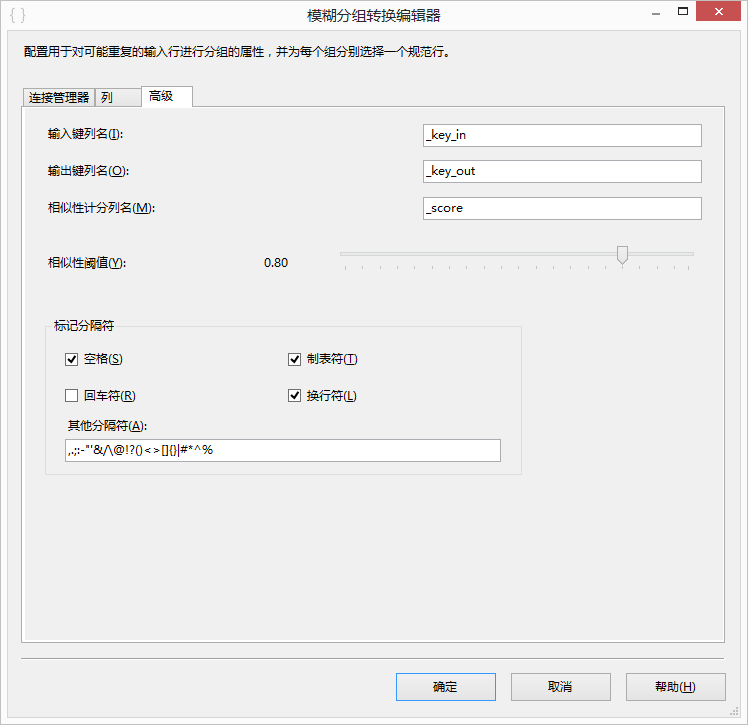
- 高级:这个标签选项中可以设置与模糊分组算法有关的选项。在这里可以修改将要派生的三个列的列名,默认情况下它们分别是“_key_out”,“_key_in”,“_score”。下面的Similarity threshold可以控制相似度,默认的值是0.5。分隔符选项中可以设置忽略输入字符流中的“.”或空字符等,默认情况下会忽略所有常见字符。
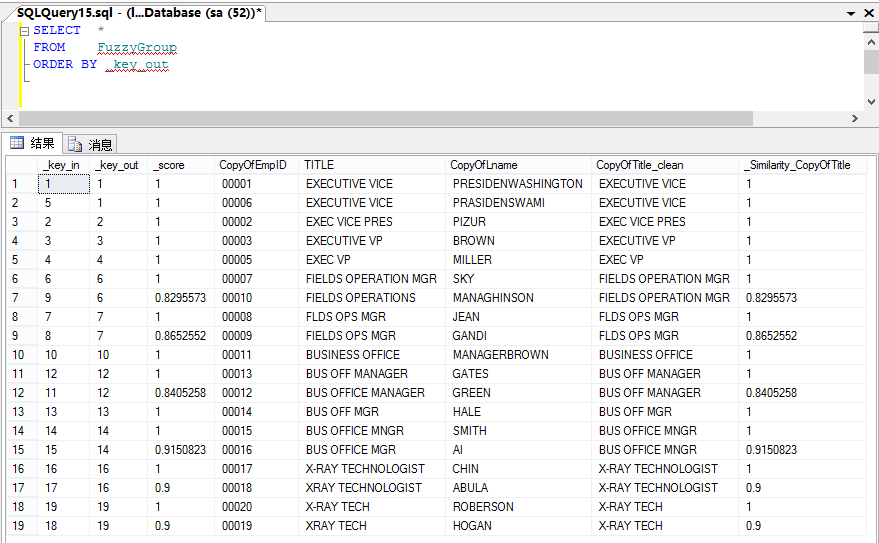
下面我们做一个例子来说明模糊分组的用法。
执行结果: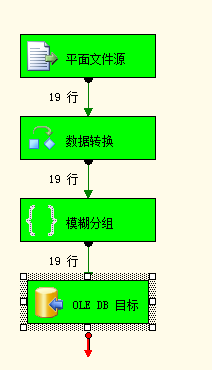

 浙公网安备 33010602011771号
浙公网安备 33010602011771号