
Oracle复习
转发自:https://www.cnblogs.com/shellway/p/3912745.html
描述一个表用 desc employees
过滤重复的部门 select distinct department_id from employees
别名的三种方式: 1、空格 2、加as 3、" "(多个单词组成的别名必须加空格,要么用下划线分开)
条件匹配日期的: where to_char(date,'yyyy-mm-dd')='1997-06-07'
默认格式: where date = '7-6月-1997'
like: where name like '%\_%' escape '\' (%:0个或者多个字符,_表示任意一个字符,escape表示转义关键字)
order by salary asc(升序) desc(降序)
多层排序: order by salary asc,name asc (在工资相同的情况下按照名字升序排列)
删除表中字段重复的记录:
delete from job_grades j1
where rowid <> (select min(rowid) from job_grades j2 where j1.grade_level = j2.grade_level);
如果删除表中自然顺序的第15行,下面语句可实现。
(rowid是数据库的一个伪列,建立表的时候数据库会自动为每个表建立ROWID列
用来唯一标识一行记录。rowid是存储每条记录的实际物理地址,对记录的访问是基于ROWID。)
delete from tab where rowid=(
select ii from (select ROWNUM nn,ROWID ii from tab WHERE ROWNUM<=15) WHERE nn=15);
等值连接:
select employee_id,e.department_id,department_name,city
from employees e,departments d,locations l
where e.department_id = d.department_id and d.location_id = l.location_id
或者
select employee_id,e.department_id,department_name,city
from employees e
join departments d on e.department_id = d.department_id
join locations l on d.location_id = l.location_id
等值连接另外方式:
select last_name,department_id,department_name
from employees join departments
--using (department_id) (前提是两表的列名以及列的数据类型要一样)
非等值连接
select employee_id,last_name,salary,grade_level
from employees e,job_grades j
where e.salary between j.lowest_sal and j.highest_sal
左外连接(哪边空就把“+”号放在哪个表上)
select e.employee_id,e.last_name,d.department_name
from employees e,departments d
where e.department_id = d.department_id(+)
左外(右外、满)连接
select employee_id,e.department_id,department_name
from employees e
left outer
--right outer
--full
join departments d on e.department_id = d.department_id
自连接
--查询公司中员工‘Chen’的manager的信息。
select e1.last_name,e2.last_name,e2.email,e2.salary
from employees e1,employees e2
where e1.manager_id = e2.employee_id and lower(e1.last_name) = 'chen'
组函数:(注意:只要不是组函数中的列都应该放在group by中,group by中的顺序不做限定,且其中有的列select中可以没有)
select department_id,job_id,avg(salary)
from employees
group by department_id,job_id
order by department_id asc
有组函数的过滤条件用having而不能用where:
select department_id,avg(salary)
from employees
having avg(salary)>6000
group by department_id
order by department_id asc
查询全公司奖金基数的平均值(注意:avg、count默认是不把值为null的计入,此时要想计入的话必须使用nvl()函数):
select avg(nvl(commission_pct,0))
from employees
查询公司在1995-1998年之间,每年雇佣的人数:
select count(*) "total",
count(decode(to_char(hire_date,'YYYY'),'1995',1,null)) "1995",
count(decode(to_char(hire_date,'YYYY'),'1996',1,null)) "1996",
count(decode(to_char(hire_date,'YYYY'),'1997',1,null)) "1997",
count(decode(to_char(hire_date,'YYYY'),'1998',1,null)) "1998"
from employees
where to_char(hire_date,'YYYY') in ('1995','1996','1997','1998')
单行子查询:
谁的工资比‘Abel’的高
select last_name,salary
from employees
where salary > (select salary from employees where last_name = 'Abel')
查询员工为Chen的manager的信息
方法一:(使用自连接)
select e2.last_name,e2.manager_id,e2.email,e2.salary
from employees e1,employees e2
where e1.manager_id = e2.employee_id and e1.last_name = 'Chen'
方法二:
select employee_id,last_name,email,salary
from employees
where employee_id = (
select manager_id
from employees
where last_name = 'Chen')
返回job_id与141号员工相同,salary比143号员工多的员工姓名、job_id和工资
select employee_id,last_name,email,salary
from employees
where employee_id = (
select manager_id
from employees
where last_name = 'Chen')
返回公司工资最少的员工的last_name,job_id,salary
select last_name,job_id,salary
from employees
where salary = (select min(salary) from employees)
查询最低工资大于50号部门最低工资的部门id和其最低工资
select department_id,min(salary)
from employees
group by department_id
having min(salary)>(select min(salary) from employees where department_id = 50)
多行子查询(in,any,all):
返回其它部门中比job_id为‘IT_PROG’部门任一工资低的员工的员工号、姓名、job_id以及salary
select employee_id,last_name,job_id,salary
from employees
where job_id <>'IT_PROG' and salary < any (select salary from employees where job_id = 'IT_PROG')
order by last_name asc
返回其它部门中比job_id为‘IT_PROG’部门所有(任意)工资低的员工的员工号、姓名、job_id以及salary
select employee_id,last_name,job_id,salary
from employees
where job_id <>'IT_PROG' and salary < any (select salary from employees where job_id = 'IT_PROG')
order by last_name asc
查询平均工资最低的部门信息
select *
from departments
where department_id = (select department_id
from employees
having avg(salary) = (select min(avg(salary))from employees
group by department_id)
group by department_id)
查询平均工资最低的部门信息和该部门的平均工资
select d.* ,(select avg(salary) from employees where department_id = d.department_id)
from departments d
where department_id = (select department_id
from employees
having avg(salary) = (select min(avg(salary))from employees
group by department_id)
group by department_id)
查询平均工资最高的job信息
select *
from jobs
where job_id in (select job_id
from employees
having avg(salary) = (select max(avg(salary))from employees group by job_id)
group by job_id)
查询平均工资高于公司的部门有哪些
select department_id,avg(salary)
from employees
group by department_id
having avg(salary)>(select avg(salary) from employees)
查询公司中所有manager的详细信息
select *
from employees
where employee_id in (select manager_id from employees)
各个部门中,最高工资中最低的那个部门的 最低工资是多少
select min(salary)
from employees
where department_id = (select department_id
from employees
having max(salary)=(select min(max(salary))
from employees
group by department_id)
group by department_id
)
查询平均工资最高的的部门的manager的详细信息:last_name,department_id,email,salary
select last_name,department_id,email,salary
from employees
where employee_id in (select manager_id
from employees
where department_id = (select department_id
from employees
having avg(salary) = (select max(avg(salary))
from employees
group by department_id)
group by department_id))
查询1999年来公司的员工中的最高工资的那个员工的信息
select *
from employees
where salary = (select max(salary)
from employees
where employee_id in (select employee_id
from employees
where to_char(hire_date,'YYYY') = '1999'))
and to_char(hire_date,'YYYY') = '1999'
查看用户定义的表:
select table_name from user_tables;
查询数据库有哪些对象(表、视图、序列、同义词)
select * from user_catalog;
查看用户定义的各种数据库对象
select distinct object_type from user_objects;
创建表的第一种方式:(白手起家)
create table emp1(
id number(10),
name varchar2(20),
salary number(10,2),
hire_date date
)
第二种方式:借助现有的表来创建(数据也会在原有的表中搬过来)
create table emp2
as select employee_id id,last_name name,hire_date,salary
from employees
(where department_id = 80)
(where department_id = 800):不想要任何数据就给它写个没有的部门或者:where 1=2
修改表:
给表追加多一列:
alter table emp1
add (email varchar2(20))
修改表中的列属性:
1、alter table emp1
modify (id number(15))
2、alter table emp1
modify (salary number(20,2) default 2000)
删除一个列:
alter table emp1
drop column email
重命名列:
alter table emp1
rename column salary to sal
删除表:
drop table emp5
清空表:
truncate table emp3;(不可以回滚)
delete from emp2;(可以回滚)
重命名表:
rename emp2 to employees2;
表数据的增、删、改:
向表中增加数据
1、insert into emp1 ‘sysdate’或者
values (1002,'BB',to_date('1998-08-08','yyyy-mm-dd'),20000)
2、insert into emp1
values (1002,'BB',to_date('1998-08-08','yyyy-mm-dd'),null)
3、insert into emp1(employee_id,last_name,hire_date) 注意:这里是只给部分列赋值,有非空约束的必须赋值
values (1004,'DD',to_date('1990-08-08','yyyy-mm-dd'))
4、注意:只想赋值一部分列的话,其它必须是允许放空值的列,这里默认salary是NULL(即有非空约束的必须赋值)
insert into emp1(employee_id,last_name,hire_date)
values (1005,'EE',to_date('1996-08-08','yyyy-mm-dd'))
5、弹窗式的插入数据
insert into emp1(employee_id,last_name,hire_date,salary)
values (&id,'&last_name','&hire_date',&salary)
基于现有表的记录插入数据
insert into emp1(employee_id,last_name,hire_date,salary)
select employee_id,last_name,hire_date,salary
from employees
where department_id = 80
更新数据:
update emp1
set salary = 22000
where employee_id = 179
更新114员工的工作和工资使其与206号员工相同
1、select employee_id,job_id,salary
from employees1
where employee_id in (114,205)
2、update employees1
set job_id = (
select job_id from employees1 where employee_id = 205
),salary = (
select salary from employees1 where employee_id = 205
)
where employee_id = 114
调整与employee_id为200的员工的job_id相同的
员工的department_id为employee_id为100的员工的department_id
update employees1
set department_id = (select department_id from employees1 where employee_id = 100)
where job_id = (select job_id from employees1 where employee_id = 200)
容易出现的数据完整性的错误如:
update employees
set department_id = 55
where department_id = 100; 问题出现在表中55号部门本来就不存在
从employees表中删除departments部门名称中含有Public字符的部门id
delete from employees1
where department_id = (select department_id from departments where department_name like '%Public%')
增:
insert into ...
values(...)
insert into ...
select...from...where...
改:
update ...
set ...
where ...
删:
delete from ...
where ...
事务:
commit;
savepoint A;
rollback to savepoint A;
当用户操作表的时候,还没有commit之前,其它用户是不能够对当前的表进行操作的
更改108号员工的信息:使其工资变为所在部门中的最高工资,job变为公司中平均工资最低的 job
update employees
set salary = (select max(salary)
from employees
where department_id = (
select department_id
from employees
where employee_id = 108)
group by department_id),
job_id = (select job_id
from employees
having avg(salary) = (
select min(avg(salary))
from employees
group by job_id )
group by job_id)
where employee_id = 108
删除108号员工所在部门中工资最低的那个员工
delete from employees
where employee_id = (
select employee_id
from employees
where department_id = (select department_id
from employees
where employee_id = 108)
and salary = (select min(salary)
from employees
where department_id =(select department_id
from employees
where employee_id = 108)
)
)
可以优化成:
delete from employees e
where department_id = (select department_id
from employees
where employee_id = 108)
and salary = (select min(salary)
from employees
where department_id = e.department_id
)
使用约束not null和unique创建表:其中在有unique约束中给它赋值多个null,null之间是不冲突的
create table emp3(
--列级约束:
id number(10) constraint emp3_id_uk unique,
name varchar2(20) constraint emp3_name_nn not null,
email varchar2(20),
salary number(10),
--表级约束:
constraint emp3_email_uk unique(email)
)
主键约束:能够唯一的确定一条记录,同样也分表级约束和列级约束,primary key不仅是not null而且unique
create table emp4(
id number(10) constraint emp4_id_pk primary key,
name varchar2(20) constraint emp4_name_nn not null,
email varchar2(20),
salary number(10),
constraint emp4_email_uk unique(email)
)
或者
create table emp4(
id number(10),
name varchar2(20) constraint emp4_name_nn not null,
email varchar2(20),
salary number(10),
constraint emp4_email_uk unique(email),
constraint emp4_id_pk primary key(id)
)
外键约束:(注意:在emp6中插入数据的时候,不能够插入departments表中department_id没有的数据记录。另外,外键引用的列起码要有一个唯一的约束)
create table emp6(
id number(10),
name varchar2(20) constraint emp6_name_nn not null,
email varchar2(20),
salary number(10),
department_id number(10),
constraint emp6_email_uk unique (email),
constraint emp6_id_pk primary key(id),
constraint emp6_dept_id_fk foreign key(department_id) references departments(department_id)
)
向表中插入departments表中存在的department_id(主键)数据
insert into emp6
values(1002,'AA',null,10000,20)
on delete set null:(级联置空:子表中相应的列置空)
on delete cascade:(级联删除:当父表中的列被删除时,子表中相对应的列也被删除)
create table emp7(
id number(10),
name varchar2(20) constraint emp7_name_nn not null,
email varchar2(20),
salary number(10),
department_id number(10),
constraint emp7_email_uk unique (email),
constraint emp7_id_pk primary key(id),
constraint emp7_dept_id_fk foreign key(department_id) references departments(department_id) on delete set null
)
check约束:比如约束工资的范围
create table emp8(
id number(10),
name varchar2(20) constraint emp8_name_nn not null,
email varchar2(20),
salary number(10) constraint emp8_salary check(salary>1500 and salary<30000),
department_id number(10),
constraint emp8_email_uk unique (email),
constraint emp8_id_pk primary key(id),
constraint emp8_dept_id_fk foreign key(department_id) references departments(department_id) on delete set null
)
修改约束:
添加not null约束
alter table emp5
modify (salary number(10,2) not null)
删除约束:
alter table emp5
drop constraint emp5_name_nn
添加unique约束
alter table emp5
add constraint emp5_name_uk unique(name)
无效化约束:
alter table emp3
disable constraint emp3_email_uk
激活约束:
alter table emp3
enable constraint emp3_email_uk
查询约束:(注意:其中条件里的表名要大写)
select constraint_name,constraint_type,search_condition
from user_constraints
where table_name = 'EMPLOYEES'
查询定义有约束的列有哪些:
select constraint_name,column_name
from user_cons_columns
where table_name = 'EMPLOYEES'
视图:
它实际上是一个虚表,它是依赖于基表的,当视图中的数据更改时,基表中的相应数据也被更改
为什么要使用视图?
答:1、可以控制数据访问 2、简化查询 3、避免重复访问相同的数据
创建视图:
create view empview
as
select employee_id,last_name,salary
from employees
where department_id = 80
基于多张表来创建视图:
create view empview3
as
select employee_id id,last_name name,salary,e.department_name
from employees e,departments d
where e.department_id = d.department_id
修改视图:create or replace
create or replace view empview2
as
select employee_id id,last_name name,department_name
from employees e,departments d
where e.department_id = d.department_id
屏蔽DML操作:with read only (其他用户只能查看,不能增、删、改)
create or replace view empview2
as
select employee_id id,last_name name,department_name
from employees e,departments d
where e.department_id = d.department_id
with read only
简单视图和复杂视图的区别:简单视图没有分组函数,在复杂视图中若使用了组函数创建的,则对它不能使用DML(增、删、改)的操作,因为有些列在基表中原本是不存在的。
创建一个复杂视图:(注意:基表中不存在的列,创建视图时要给它个别名,如下面的平均工资。)
create or replace view empview3
as
select department_name dept_name,avg(salary) avg_sal
from employees e ,departments d
where e.department_id = d.department_id
group by department_name
rownum是一个伪列,跟id有点相关,且有它自己的一个排序。
比如,你想找到表中工资最高的前10位的员工,以下用rownum作为条件是不行的,因为它有自己默认的排列顺序
select rownum,employee_id,last_name,salary
from employees
where rownum <= 10
order by salary desc
要真想用rownum达到查询最高工资的前10位则要如下这样:(注意:rownum只能使用<或<=,而用=,>,>=都不会返回任何数据)
select rownum,employee_id,last_name,salary
from (select employee_id,last_name,salary
from employees
order by salary desc)
where rownum <=10
那么要查询最高工资排列40-50名的数据要怎么办?如下:(此时最外层的rn已经不是伪列了)
select rn,employee_id,last_name,salary
from (select rownum rn,employee_id,last_name,salary
from (select employee_id,last_name,salary
from employees
order by salary desc))
where rn <40 and rn<=50
序列:主要用来提供主键值
创建序列:
create sequence empseq
increment by 10
start with 10
maxvalue 100
cycle
nocache
序列在数据插入表时在主键位置的作用:
先:
create table emp01
as
select employee_id,last_name,salary
from employees
where 1=2
然后:
insert into emp01
values(empseq.nextval,'BB',3300)
修改序列:(能修改增量、最大值、最小值、是否循环以及是否装入内存,如要更改初始值则要通过删除序列重新创建序列,因为改后可能会与之前的数据发生冲突,因为序列是唯一的)
alter sequence empseq
increment by 1
nocycle
序列一以下情况中会出现裂缝:
1、回滚
2、系统出现异常
3、多个表同时使用同一个序列
查询序列:(如果指定了nocache选项,则last_number返回的是序列中下一个有效值)
select sequence_name,min_value,max_value,increment_by,last_number
from user_sequences
删除序列
drop sequence empseq
索引的作用,能够加速 oracle服务器的查询速度,主键和唯一约束中系统默认为它所约束的列创建所引,也可以为非唯一的列手动创建所引,创建好之后系统会自动调用索引,不用你手动编码调用
创建索引:
create index emp01_id_ix
on emp01(employee_id)
删除索引:
drop index emp01_id_ix
什么时候创建索引?
1、列中数据值分布范围很广
2、列经常在where子句或者连接条件中出现
3、表经常被访问而且数据量很大,访问的数据大概占数据总量的2%到4%
什么时候不要创建索引?
1、表很小
2、表经常更新
3、查询的数据大于2%到4%
4、表不经常作为where子句或者连接条件中出现
---------------------------
游标:
游标的概念:
游标是SQL的一个内存工作区,由系统或用户以变量的形式定义。游标的作用就是用于临时存储从数据库中提取的数据块。在某些情况下,需要把数据从存放在磁盘的表中调到计算机内存中进行处理,最后将处理结果显示出来或最终写回数据库。这样数据处理的速度才会提高,否则频繁的磁盘数据交换会降低效率。
游标有两种类型:显式游标和隐式游标。在前述程序中用到的SELECT...INTO...查询语句,一次只能从数据库中提取一行数据,对于这种形式的查询和DML操作,系统都会使用一个隐式游标。但是如果要提取多行数据,就要由程序员定义一个显式游标,并通过与游标有关的语句进行处理。显式游标对应一个返回结果为多行多列的SELECT语句。
游标一旦打开,数据就从数据库中传送到游标变量中,然后应用程序再从游标变量中分解出需要的数据,并进行处理。
隐式游标
如前所述,DML操作和单行SELECT语句会使用隐式游标,它们是:
* 插入操作:INSERT。
* 更新操作:UPDATE。
* 删除操作:DELETE。
* 单行查询操作:SELECT ... INTO ...。
当系统使用一个隐式游标时,可以通过隐式游标的属性来了解操作的状态和结果,进而控制程序的流程。隐式游标可以使用名字SQL来访问,但要注意,通过SQL游标名总是只能访问前一个DML操作或单行SELECT操作的游标属性。所以通常在刚刚执行完操作之后,立即使用SQL游标名来访问属性。游标的属性有四种,如下所示。
- 隐式游标的属性 返回值类型 意 义
- SQL%ROWCOUNT 整型 代表DML语句成功执行的数据行数
- SQL%FOUND 布尔型 值为TRUE代表插入、删除、更新或单行查询操作成功
- SQL%NOTFOUND 布尔型 与SQL%FOUND属性返回值相反
- SQL%ISOPEN 布尔型 DML执行过程中为真,结束后为假
【训练1】 使用隐式游标的属性,判断对雇员工资的修改是否成功。
步骤1:输入和运行以下程序:
- SET SERVEROUTPUT ON
- BEGIN
- UPDATE emp SET sal=sal+100 WHERE empno=1234;
- IF SQL%FOUND THEN
- DBMS_OUTPUT.PUT_LINE('成功修改雇员工资!');
- COMMIT;
- ELSE
- DBMS_OUTPUT.PUT_LINE('修改雇员工资失败!');
- END IF;
- END;
运行结果为:
- 修改雇员工资失败!
- PL/SQL 过程已成功完成。
步骤2:将雇员编号1234改为7788,重新执行以上程序:
运行结果为:
- 成功修改雇员工资!
- PL/SQL 过程已成功完成。
说明:本例中,通过SQL%FOUND属性判断修改是否成功,并给出相应信息。
显式游标
游标的定义和操作
游标的使用分成以下4个步骤。
1.声明游标
在DECLEAR部分按以下格式声明游标:
CURSOR 游标名[(参数1 数据类型[,参数2 数据类型...])]
IS SELECT语句;
参数是可选部分,所定义的参数可以出现在SELECT语句的WHERE子句中。如果定义了参数,则必须在打开游标时传递相应的实际参数。
SELECT语句是对表或视图的查询语句,甚至也可以是联合查询。可以带WHERE条件、ORDER BY或GROUP BY等子句,但不能使用INTO子句。在SELECT语句中可以使用在定义游标之前定义的变量。
2.打开游标
在可执行部分,按以下格式打开游标:
OPEN 游标名[(实际参数1[,实际参数2...])];
打开游标时,SELECT语句的查询结果就被传送到了游标工作区。
3.提取数据
在可执行部分,按以下格式将游标工作区中的数据取到变量中。提取操作必须在打开游标之后进行。
FETCH 游标名 INTO 变量名1[,变量名2...];
或
FETCH 游标名 INTO 记录变量;
游标打开后有一个指针指向数据区,FETCH语句一次返回指针所指的一行数据,要返回多行需重复执行,可以使用循环语句来实现。控制循环可以通过判断游标的属性来进行。
下面对这两种格式进行说明:
第一种格式中的变量名是用来从游标中接收数据的变量,需要事先定义。变量的个数和类型应与SELECT语句中的字段变量的个数和类型一致。
第二种格式一次将一行数据取到记录变量中,需要使用%ROWTYPE事先定义记录变量,这种形式使用起来比较方便,不必分别定义和使用多个变量。
定义记录变量的方法如下:
变量名 表名|游标名%ROWTYPE;
其中的表必须存在,游标名也必须先定义。
4.关闭游标
CLOSE 游标名;
显式游标打开后,必须显式地关闭。游标一旦关闭,游标占用的资源就被释放,游标变成无效,必须重新打开才能使用。
以下是使用显式游标的一个简单练习。
【训练1】 用游标提取emp表中7788雇员的名称和职务。
- SET SERVEROUTPUT ON
- DECLARE
- v_ename VARCHAR2(10);
- v_job VARCHAR2(10);
- CURSOR emp_cursor IS
- SELECT ename,job FROM emp WHERE empno=7788;
- BEGIN
- OPEN emp_cursor;
- FETCH emp_cursor INTO v_ename,v_job;
- DBMS_OUTPUT.PUT_LINE(v_ename||','||v_job);
- CLOSE emp_cursor;
- END;
执行结果为:
- SCOTT,ANALYST
- PL/SQL 过程已成功完成。
说明:该程序通过定义游标emp_cursor,提取并显示雇员7788的名称和职务。
作为对以上例子的改进,在以下训练中采用了记录变量。
【训练2】 用游标提取emp表中7788雇员的姓名、职务和工资。
- SET SERVEROUTPUT ON
- DECLARE
- CURSOR emp_cursor IS SELECT ename,job,sal FROM emp WHERE empno=7788;
- emp_record emp_cursor%ROWTYPE;
- BEGIN
- OPEN emp_cursor;
- FETCH emp_cursor INTO emp_record;
- DBMS_OUTPUT.PUT_LINE(emp_record.ename||','|| emp_record.job||','|| emp_record.sal);
- CLOSE emp_cursor;
- END;
执行结果为:
- SCOTT,ANALYST,3000
- PL/SQL 过程已成功完成。
说明:实例中使用记录变量来接收数据,记录变量由游标变量定义,需要出现在游标定义之后。
注意:可通过以下形式获得记录变量的内容:
记录变量名.字段名。
显式游标属性
虽然可以使用前面的形式获得游标数据,但是在游标定义以后使用它的一些属性来进行结构控制是一种更为灵活的方法。显式游标的属性如下所示。
- 游标的属性 返回值类型 意 义
- %ROWCOUNT 整型 获得FETCH语句返回的数据行数
- %FOUND 布尔型 最近的FETCH语句返回一行数据则为真,否则为假
- %NOTFOUND 布尔型 与%FOUND属性返回值相反
- %ISOPEN 布尔型 游标已经打开时值为真,否则为假
可按照以下形式取得游标的属性:
游标名%属性
要判断游标emp_cursor是否处于打开状态,可以使用属性emp_cursor%ISOPEN。如果游标已经打开,则返回值为“真”,否则为“假”。具体可参照以下的训练。
【训练1】 使用游标的属性练习。
- SET SERVEROUTPUT ON
- DECLARE
- V_ename VARCHAR2(10);
- CURSOR emp_cursor IS
- SELECT ename FROM emp;
- BEGIN
- OPEN emp_cursor;
- IF emp_cursor%ISOPEN THEN
- LOOP
- FETCH emp_cursor INTO v_ename;
- EXIT WHEN emp_cursor%NOTFOUND;
- DBMS_OUTPUT.PUT_LINE(to_char(emp_cursor%ROWCOUNT)||'-'||v_ename);
- END LOOP;
- ELSE
- DBMS_OUTPUT.PUT_LINE('用户信息:游标没有打开!');
- END IF;
- CLOSE emp_cursor;
- END;
执行结果为:
- 1-SMITH
- 2-ALLEN
- 3-WARD
- PL/SQL 过程已成功完成。
说明:本例使用emp_cursor%ISOPEN判断游标是否打开;使用emp_cursor%ROWCOUNT获得到目前为止FETCH语句返回的数据行数并输出;使用循环来获取数据,在循环体中使用FETCH语句;使用emp_cursor%NOTFOUND判断FETCH语句是否成功执行,当FETCH语句失败时说明数据已经取完,退出循环。
【练习1】去掉OPEN emp_cursor;语句,重新执行以上程序。
游标参数的传递
【训练1】 带参数的游标。
- SET SERVEROUTPUT ON
- DECLARE
- V_empno NUMBER(5);
- V_ename VARCHAR2(10);
- CURSOR emp_cursor(p_deptno NUMBER, p_job VARCHAR2) IS
- SELECT empno, ename FROM emp
- WHERE deptno = p_deptno AND job = p_job;
- BEGIN
- OPEN emp_cursor(10, 'CLERK');
- LOOP
- FETCH emp_cursor INTO v_empno,v_ename;
- EXIT WHEN emp_cursor%NOTFOUND;
- DBMS_OUTPUT.PUT_LINE(v_empno||','||v_ename);
- END LOOP;
- END;
执行结果为:
- 7934,MILLER
- PL/SQL 过程已成功完成。
说明:游标emp_cursor定义了两个参数:p_deptno代表部门编号,p_job代表职务。语句OPEN emp_cursor(10, 'CLERK')传递了两个参数值给游标,即部门为10、职务为CLERK,所以游标查询的内容是部门10的职务为CLERK的雇员。循环部分用于显示查询的内容。
详细可参考如下:转发自:https://blog.csdn.net/liyong199012/article/details/8948952、
---------------------------
存储过程介绍:
简单的说,就是一组SQL语句集,功能强大,可以实现一些比较复杂的逻辑功能,类似于JAVA语言中的方法;
ps:存储过程跟触发器有点类似,都是一组SQL集,但是存储过程是主动调用的,且功能比触发器更加强大,触发器是某件事触发后自动调用;
存储过程特性:
有输入输出参数,可以声明变量,有if/else, case,while等控制语句,通过编写存储过程,可以实现复杂的逻辑功能;
函数的普遍特性:模块化,封装,代码复用;
速度快,只有首次执行需经过编译和优化步骤,后续被调用可以直接执行,省去以上步骤;
创建一个简单的存储过程
存储过程proc_adder功能很简单,两个整型输入参数a和b,一个整型输出参数sum,功能就是计算输入参数a和b的结果,赋值给输出参数sum;
几点说明:
DELIMITER ;;:之前说过了,把默认的输入的结束符;替换成;;。
DEFINER:创建者;

-- ----------------------------
-- Procedure structure for `proc_adder`
-- ----------------------------
DROP PROCEDURE IF EXISTS `proc_adder`;
DELIMITER ;;
CREATE DEFINER=`root`@`localhost` PROCEDURE `proc_adder`(IN a int, IN b int, OUT sum int)
BEGIN
#Routine body goes here...
DECLARE c int;
if a is null then set a = 0;
end if;
if b is null then set b = 0;
end if;
set sum = a + b;
END
;;
DELIMITER ;
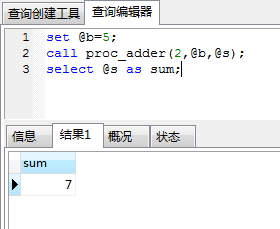
执行以上存储结果,验证是否正确,如下图,结果OK:
set @b=5; call proc_adder(2,@b,@s); select @s as sum;
存储过程中的控制语句
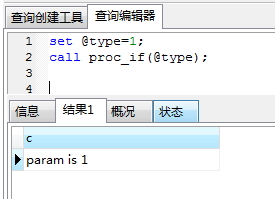
IF语句:
-- ----------------------------
-- Procedure structure for `proc_if`
-- ----------------------------
DROP PROCEDURE IF EXISTS `proc_if`;
DELIMITER ;;
CREATE DEFINER=`root`@`localhost` PROCEDURE `proc_if`(IN type int)
BEGIN
#Routine body goes here...
DECLARE c varchar(500);
IF type = 0 THEN
set c = 'param is 0';
ELSEIF type = 1 THEN
set c = 'param is 1';
ELSE
set c = 'param is others, not 0 or 1';
END IF;
select c;
END
;;
DELIMITER ;
CASE语句:
-- ----------------------------
-- Procedure structure for `proc_case`
-- ----------------------------
DROP PROCEDURE IF EXISTS `proc_case`;
DELIMITER ;;
CREATE DEFINER=`root`@`localhost` PROCEDURE `proc_case`(IN type int)
BEGIN
#Routine body goes here...
DECLARE c varchar(500);
CASE type
WHEN 0 THEN
set c = 'param is 0';
WHEN 1 THEN
set c = 'param is 1';
ELSE
set c = 'param is others, not 0 or 1';
END CASE;
select c;
END
;;
DELIMITER ;

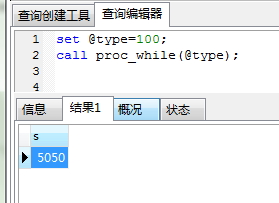
循环while语句:
-- ----------------------------
-- Procedure structure for `proc_while`
-- ----------------------------
DROP PROCEDURE IF EXISTS `proc_while`;
DELIMITER ;;
CREATE DEFINER=`root`@`localhost` PROCEDURE `proc_while`(IN n int)
BEGIN
#Routine body goes here...
DECLARE i int;
DECLARE s int;
SET i = 0;
SET s = 0;
WHILE i <= n DO
set s = s + i;
set i = i + 1;
END WHILE;
SELECT s;
END
;;
DELIMITER ;
其它:略~
存储过程弊端
不同数据库,语法差别很大,移植困难,换了数据库,需要重新编写;
不好管理,把过多业务逻辑写在存储过程不好维护,不利于分层管理,容易混乱,一般存储过程适用于个别对性能要求较高的业务,其它的必要性不是很大;
...
转发自:https://www.cnblogs.com/chenpi/p/5136483.html
---------------------------
同义词:
创建同义词
create synonym e for employees
删除同义词
drop synonym e
创建用户和密码:
create user atguigu01
identified atguigu01;
给用户登录数据库的权限,(create table,create sequence,create view,create procedure)
grant create session
to atguigu01 ;
创建用户表空间
alter user atguigu01 quota unlimited(或者5M)
on users
更改用户自己的密码:
alter user atguigu01
identified by atguigu;
角色:使用角色分配给用户权限会更快,角色有什么权限,用户就有什么权限
1、创建角色
create role my_role
2、为角色赋予权限
grant create session,create table,create view
to my_role
3、将角色赋予用户
grant my_role to atguigu02
对象:
1、给atguigu01分配表employees的查询、修改的权限
grant select,update
on scott.employees
to atguigu01
验证上一步的操作:
update scott.employees
set last_name = 'ABCD'
where employee_id = 206 (此时改的是scott用户中的表,atguigu只是调用它的表,并没有复制过来)
with grant option:使用户同样具有分配权限的权利
grant select
on scott.departments
to atguigu01
with grant option
public:向数据库中所有用户分配权限
grant select
on scott.locations
to public
收回对象权限:
数据字典视图 描述
ROLE_SYS_PRIVS 角色拥有的系统权限
ROLE_TAB_PRIVS 角色拥有的对象权限
USER_ROLE_PRIVS 用户拥有的角色
USER_TAB_PRIVS_MADE 用户分配的关于表对象权限
USER_TAB_PRIVS_RECD 用户拥有的关于表对象权限
USER_COL_PRIVS_MADE 用户分配的关于列的对象权限
USER_COL_PRIVS_RECD 用户拥有的关于列的对象权限
USER_SYS_PRIVS 用户拥有的系统权限
先查询本用户所拥有的关于表的权限有哪些:
select * from USER_TAB_PRIVS_RECD;
然后执行收回:
revoke select
on scott.employees
from atguigu01
总结:
语句 功能
CREATE USER 创建用户(通常由DBA完成)
GRANT 分配权限
CREATE ROLE 创建角色(通常由DBA完成)
ALTER USER 修改用户密码或者给表分配空间
REVOKE 收回权限
SET操作符(默认查询到的结果是按照第一列的顺序来排列的,要是给列起别名,默认显示的结果是按照第一张表的别名,还有查询的列的数据类型和数量要对应得上)
1、union(去重复部分)/union all:联合
2、intersect:取交集
3、minus:减去
取employees01和employees02的并集
select employee_id,department_id
from employees01
union/union all
select employee_id,department_id
from employees02
取employees01和employees02的交集
select employee_id,department_id
from employees01
intersect
select employee_id,department_id
from employees02
取employees01和employees02的差集
select employee_id,department_id
from employees01
minus
select employee_id,department_id
from employees02
若查询的列的数据类型和数量要对应不上,解决办法如下:(即给相应的列补上为空的数据类型和列的个数)
select employee_id emp_id,department_id dept_id,to_char(null)
from employees01
union
select to_number(null),department_id,department_name
from departments
练习使用union
select 'I study at' my_blogs
from dual
union
select 'www.cnblogs.com/shellway'
from dual
union
select 'happily'
from dual
得到结果:
MY_BLOGS
------------------------
I study at
happily
www.cnblogs.com/shellway
可以给它加多一列来排序:
select 'I study at' my_blogs,1
from dual
union
select 'www.cnblogs.com/shellway',2
from dual
union
select 'happily',3
from dual
order by 2 (这里的2表示的是第二列)
得到结果:
MY_BLOGS 1
------------------------ ----------
I study at 1
www.cnblogs.com/shellway 2
happily 3
如果不想打印第二列,则先:
column col_nop noprint;
然后:
select 'I study at' my_blogs,1 col_nop
from dual
union
select 'www.cnblogs.com/shellway',2
from dual
union
select 'happily',3
from dual
order by 2
得出结果:
MY_BLOGS
------------------------
I study at
www.cnblogs.com/shellway
happily
练习:
查询部门的部门号,其中不包括job_id是“ST_CLERK”的部门号
方式一(之前学的):
select department_id
from departments
where department_id not in(
select department_id
from employees
where job_id = 'ST_CLECK'
)
方式二(利用SET的方式):
select department_id
from departments
minus
select department_id
from employees
where job_id = 'ST_CLECK'
查询10、50、20号部门的job_id、department_id,并且department_id按10、50、20的顺序排列
column col_nop noprint;(用于隐藏列使用)
select job_id,department_id,1 col_nop
from employees
where department_id = 10
union
select job_id,department_id,2
from employees
where department_id = 50
union
select job_id,department_id,3
from employees
where department_id = 20
order by 3 (这里的3表示的是第三列)
查询所有员工的last_name,department_id,department_name
select last_name,department_id,to_char(null) department_name
from employees
union
select to_char(null),department_id,department_name
from departments
疑问:同样是查询所有员工的last_name,department_id,department_name,用full join和union有什么区别?
多列子查询:
查询与141号或174号员工的manager_id和department_id相同的其他员工的employee_id,department_id
方法一(传统的方法):
select employee_id,manager_id,department_id
from employees e
where manager_id in (
select manager_id
from employees
where employee_id in (141,174)
)
and department_id in (
select department_id
from employees
where employee_id in (141,174)
)
and employee_id not in (141,174)
方法二(多列子查询):
select employee_id,manager_id,department_id
from employees e
where (manager_id,department_id) in (
select manager_id,department_id
from employees
where employee_id in (141,174)
)
and employee_id not in (141,174)
在from子句中使用子查询
返回比本部门平均工资高的员工的last_name,department_id,salary以及平均工资
方法一:
select last_name,department_id,salary,( select avg(salary)
from employees e3
where e1.department_id = e3.department_id
group by department_id)
from employees e1
where salary > (
select avg(salary)
from employees e2
where e1.department_id = e2.department_id (注意,这是体现“本部门”的条件,不能少了)
group by department_id
)
方法二:
select last_name,e1.department_id,salary,e2.avg_sal
from employees e1,(select department_id,avg(salary) avg_sal from employees group by department_id) e2
where e1.department_id = e2.department_id
显示员工的employee_id,last_name,location,其中,若员工department_id与location_id为1800的department_id相同,则location为'Canada',其余为‘USA’
select employee_id,last_name,(
case department_id when (select department_id from departments where location_id = 1800) then 'Canada'
else 'USA' end
)location
from employees
若employees表中employee_id与job_history表中employee_id相同的数目不小于2,则输出这些相同id的员工的
employee_id,last_name和其job_id
查询公司管理者的employee_id,last_name,job_id,department_id信息
方法一:
select employee_id,last_name,job_id,department_id
from employees e1
where employee_id in (
select manager_id
from employees e2
where e1.employee_id = e2.manager_id
)
方法二:
select distinct e1.employee_id,e1.last_name,e1.job_id,e1.department_id
from employees e1,employees e2
where e1.employee_id = e2.manager_id
方法三:利用esists来查询符合条件的就返回true输出否则返回false不输出,即只要你是管理都就给我输出,我不管你是几号的
select employee_id,last_name,job_id,department_id
from employees e1
where exists (
select 'A'
from employees e2
where e1.employee_id = e2.manager_id
)
查询departments表中,不存在于employees表中的部门的department_id,department_name
select department_id,department_name
from departments d
where not exists (
select 'A'
from employees
where department_id = d.department_id
)
删除employees表中,其与emp_history表皆有的数据
delete from employees e
where employee_id = (
select employee_id
from emp_history
where employee_id = e.employee_id
)
with子句:
查询公司中工资比Abel高的员工的信息
方法一:
select employee_id,last_name,salary
from employees
where salary>(
select salary
from employees
where last_name = 'Abel'
)
方法二:(使用with子句)
with Abel_sal as (
select salary
from employees
where last_name = 'Abel'
)
select employee_id,last_name,salary
from employees
where salary > (
select salary
from Abel_sal
)
查询公司中各部门和总工资大于公司中各部门的平均总工资的部门信息
with dept_sumsal as (
select department_name,sum(salary) sumsal
from employees e,departments d
where e.department_id = d.department_id
group by department_name
),
dept_avg_sumsal1 as (
select sum(sumsal)/count(*) dept_avg_sumsal2
from dept_sumsal
)
select *
from dept_sumsal dd
where dd.sumsal > (
select dept_avg_sumsal2
from dept_avg_sumsal1
)
练习:
查询员工的last_name,department_id,salary,其中员工的salary,department_id
与有奖金的任何一个员工的salary,department_id相同即可。(考的是多列子查询)
select last_name,department_id,salary
from employees
where (salary,department_id) in (
select salary,department_id
from employees
where commission_pct is not null
)
选择工资大于所有job_id = 'SA_MAN'的员工的工资的员工的last_name,job_id,salary
select last_name,job_id,salary
from employees
where salary > all (
select salary
from employees
where job_id = 'SA_MAN'
)
或者
select last_name,job_id,salary
from employees
where salary > (
select max(salary)
from employees
where job_id = 'SA_MAN'
)
选择所有没有管理者的员工的last_name
select last_name
from employees
where manager_id is not null
或者
select last_name
from employees e1
where not exists (
select 'A'
from employees e2
where e1.manager_id = e2.employee_id
)
