

第4章 表
介绍了再innoDB存储引擎下数据是如何存放在硬盘上的。
主要参考了:https://mp.weixin.qq.com/s?__biz=MzIxNTQ3NDMzMw==&mid=2247483678&idx=1&sn=913780d42e7a81fd3f9b747da4fba8ec&chksm=979688eca0e101fa0913c3d2e6107dfa3a6c151a075c8d68ab3f44c7c364d9510f9e1179d94d&scene=21#wechat_redirect
4.1 索引组织表
这个名字太学术了。InnoDB存储数据的形式是B+树,B+树建立的时候就需有比较大小的操作,用来比较大小的数据就是一行记录的索引,用这种方式建立的表被称为索引组织表。每张表都有一个主键,在这里要区分一下主键和索引,主键是用来唯一区分一条记录的,索引是用来组织整张表的,这就是说主键必须得有,如果建立表的时候没有显示指定主键,就会找一个非NUll索引作为主键,如果没有合适的索引存储引擎就会自动创建一个指针当做索引。
4.3 InnoDB行记录格式
InnoDB是面向行存储的引擎,组织数据的单位是一行记录,默认使用的格式是Compact格式。
4.3.1 Compact行记录格式

- 边长字段长度列表:逆序记录列数据中边长字段的长度
- NULL标志位:NULL值不在列数据区存储,按位表示是否有NULL值,所以NULL值不占用存储空间
记录头信息最为重要,
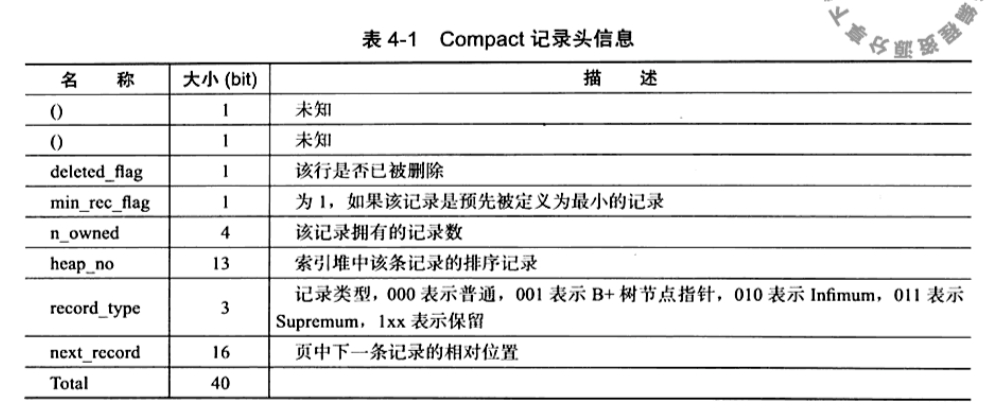
4.4 InnoDB数据页结构
页是InnoDB引擎管理数据库的最小单位,每次发生置换的时候页是置换的最小单位。
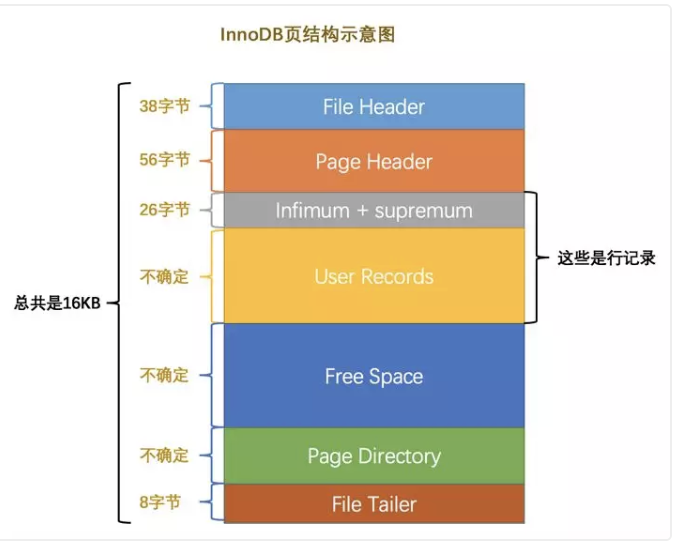
所有的数据按照主键大小顺序组织成一个链表,链表的头是预设的infimun,代表整个链表里最小的行,supremun是最大的行,也是预设的。每当需要插入新的数据的时候就从Free Space里分割出一段区域放到USer Records里。
Page Directory是用来在整个User Record空间执行二分查找的辅助的数据结构,因为整个User Record是以链表组织的,无法直接二分查找。
