
innodb page的结构
- 一个存放记录(row)的page,由page header、page trailer、page body组成。如下图:[2]
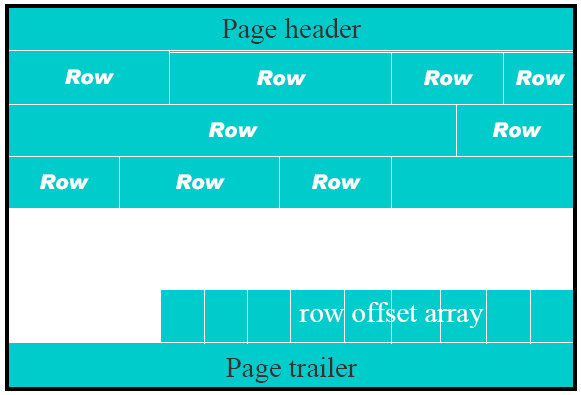
page的结构详情参看如下:
from:http://forge.mysql.com/wiki/MySQL_Internals_InnoDB#InnoDB_Page_Structure
High-Altitude Picture
The chart below shows the three parts of a physical record.
| Name | Size |
| Field Start Offsets | (F*1) or (F*2) bytes |
| Extra Bytes | 6 bytes |
| Field Contents | depends on content |
Legend: The letter 'F' stands for 'Number Of Fields'.
The meaning of the parts is as follows:
- The FIELD START OFFSETS is a list of numbers containing the information "where a field starts".
- The EXTRA BYTES is a fixed-size header.
- The FIELD CONTENTS contains the actual data.
An Important Note About The Word "Origin"
The "Origin" or "Zero Point" of a record is the first byte of the Field Contents --- not the first byte of the Field Start Offsets. If there is a pointer to a record, that pointer is pointing to the Origin. Therefore the first two parts of the record are addressed by subtracting from the pointer, and only the third part is addressed by adding to the pointer.
[edit] FIELD START OFFSETS
The Field Start Offsets is a list in which each entry is the position, relative to the Origin, of the start of the next field. The entries are in reverse order, that is, the first field's offset is at the end of the list.
An example: suppose there are three columns. The first column's length is 1, the second column's length is 2, and the third column's length is 4. In this case, the offset values are, respectively, 1, 3 (1+2), and 7 (1+2+4). Because values are reversed, a core dump of the Field Start Offsets would look like this: 07,03,01.
There are two complications for special cases:
- Complication #1: The size of each offset can be either one byte or two bytes. One-byte offsets are only usable if the total record size is less than 127. There is a flag in the "Extra Bytes" part which will tell you whether the size is one byte or two bytes.
- Complication #2: The most significant bits of an offset may contain flag values. The next two paragraphs explain what the contents are.
When The Size Of Each Offset Is One Byte
- 1 bit =
NULL, = NULL - 7 bits = the actual offset, a number between 0 and 127
When The Size Of Each Offset Is Two Bytes
- 1 bit =
NULL, = NULL - 1 bit = 0 if field is on same page as offset, = 1 if field and offset are on different pages
- 14 bits = the actual offset, a number between 0 and 16383
It is unlikely that the "field and offset are on different pages" unless the record contains a large BLOB.
[edit] EXTRA BYTES
The Extra Bytes are a fixed six-byte header.
| Name | Size | Description |
| info_bits: | ?? | ?? |
| () | 1 bit | unused or unknown |
| () | 1 bit | unused or unknown |
| deleted_flag | 1 bit | 1 if record is deleted |
| min_rec_flag | 1 bit | 1 if record is predefined minimum record |
| n_owned | 4 bits | number of records owned by this record |
| heap_no | 13 bits | record's order number in heap of index page |
| n_fields | 10 bits | number of fields in this record, 1 to 1023 |
| 1byte_offs_flag | 1 bit | 1 if each Field Start Offsets is 1 byte long (this item is also called the "short" flag) |
| next 16 bits | 16 bits | pointer to next record in page |
| TOTAL | 48 bits | ?? |
Total size is 48 bits, which is six bytes.
If you're just trying to read the record, the key bit in the Extra Bytes is 1byte_offs_flag you need to know if 1byte_offs_flag is 1 (i.e.: "short 1-byteoffsets") or 0 (i.e.: "2-byte offsets").
Given a pointer to the Origin, InnoDB finds the start of the record as follows:
- Let X = n_fields (the number of fields is by definition equal to the number of entries in the Field Start Offsets Table).
- If 1byte_offs_flag equals 0, then let X = X * 2 because there are two bytes for each entry instead of just one.
- Let X = X + 6, because the fixed size of Extra Bytes is 6.
- The start of the record is at (pointer value minus X).
[edit] FIELD CONTENTS
The Field Contents part of the record has all the data. Fields are stored in the order they were defined in.
There are no markers between fields, and there is no marker or filler at the end of a record.
Here's an example.
- I made a table with this definition:
CREATE TABLE T
(FIELD1 VARCHAR(3), FIELD2 VARCHAR(3), FIELD3 VARCHAR(3))
Type=InnoDB;
To understand what follows, you must know that table T has six columns not three because InnoDB automatically added three "system columns" at the start for its own housekeeping. It happens that these system columns are the row ID, the transaction ID, and the rollback pointer, but their values don't matter now. Regard them as three black boxes.
- I put some rows in the table. My last three
INSERTstatements were:
INSERT INTO T VALUES ('PP', 'PP', 'PP');
INSERT INTO T VALUES ('Q', 'Q', 'Q');
INSERT INTO T VALUES ('R', NULL, NULL);
- I ran Borland's TDUMP to get a hexadecimal dump of the contents of
\mysql\data\ibdata1, which (in my case) is the MySQL/InnoDBdata file (on Windows).
Here is an extract of the dump:
| Address Values in Hexadecimal | Values in ASCII |
0D4280: 00 00 2D 00 84 4F 4F 4F 4F 4F 4F 4F 4F 4F 19 17 |
..-..OOOOOOOOO.. |
0D4290: 15 13 0C 06 00 00 78 0D 02 BF 00 00 00 00 04 21 |
......x........! |
0D42A0: 00 00 00 00 09 2A 80 00 00 00 2D 00 84 50 50 50 |
.....*....-..PPP |
0D42B0: 50 50 50 16 15 14 13 0C 06 00 00 80 0D 02 E1 00 |
PPP............. |
0D42C0: 00 00 00 04 22 00 00 00 00 09 2B 80 00 00 00 2D |
....".....+....- |
0D42D0: 00 84 51 51 51 94 94 14 13 0C 06 00 00 88 0D 00 |
..QQQ........... |
0D42E0: 74 00 00 00 00 04 23 00 00 00 00 09 2C 80 00 00 |
t.....#.....,... |
0D42F0: 00 2D 00 84 52 00 00 00 00 00 00 00 00 00 00 00 |
.-..R........... |
A reformatted version of the dump, showing only the relevant bytes, looks like this (I've put a line break after each field and added labels):
Reformatted Hexadecimal Dump
19 17 15 13 0C 06 Field Start Offsets /* First Row */ 00 00 78 0D 02 BF Extra Bytes 00 00 00 00 04 21 System Column #1 00 00 00 00 09 2A System Column #2 80 00 00 00 2D 00 84 System Column #3 50 50 Field1 'PP' 50 50 Field2 'PP' 50 50 Field3 'PP' 16 15 14 13 0C 06 Field Start Offsets /* Second Row */ 00 00 80 0D 02 E1 Extra Bytes 00 00 00 00 04 22 System Column #1 00 00 00 00 09 2B 80 System Column #2 00 00 00 2D 00 84 System Column #3 51 Field1 'Q' 51 Field2 'Q' 51 Field3 'Q' 94 94 14 13 0C 06 Field Start Offsets /* Third Row */ 00 00 88 0D 00 74 Extra Bytes 00 00 00 00 04 23 System Column #1 00 00 00 00 09 2C System Column #2 80 00 00 00 2D 00 84 System Column #3 52 Field1 'R'
You won't need explanation if you followed everything I've said, but I'll add helpful notes for the three trickiest details.
- Helpful Notes About "Field Start Offsets":
Notice that the sizes of the record's fields, in forward order, are: 6, 6, 7, 2, 2, 2. Since each offset is for the start of the "next" field, the hexadecimal offsets are 06, 0c (6+6), 13 (6+6+7), 15 (6+6+7+2), 17 (6+6+7+2+2), 19 (6+6+7+2+2+2). Reversing the order, the Field Start Offsets of the first record are: 19,17,15,13,0c,06.
- Helpful Notes About "Extra Bytes":
Look at the Extra Bytes of the first record: 00 00 78 0D 02 BF. The fourth byte is 0D hexadecimal, which is 1101 binary ... the 110 is the last bits of n_fields (110 binary is 6 which is indeed the number of fields in the record) and the final 1 bit is 1byte_offs_flag. The fifth and sixth bytes, which contain 02 BF, constitute the "next" field. Looking at the original hexadecimal dump, at address 0D42BF (which is position 02BF within the page), you'll see the beginning bytes of System Column #1 of the second row. In other words, the "next" field points to the "Origin" of the following row.
- Helpful Notes About NULLs:
For the third row, I inserted NULLs in FIELD2 and FIELD3. Therefore in the Field Start Offsets the top bit is on for these fields (the values are 94 hexadecimal, 94 hexadecimal, instead of 14 hexadecimal, 14 hexadecimal). And the row is shorter because the NULLs take no space.
[edit] Where to Look For More Information
References:
The most relevant InnoDB source-code files are rem0rec.c, rem0rec.ic, and rem0rec.h in the rem ("Record Manager") directory.
[edit] InnoDB Page Structure
InnoDB stores all records inside a fixed-size unit which is commonly called a "page" (though InnoDB sometimes calls it a "block" instead). Currently all pages are the same size, 16KB.
A page contains records, but it also contains headers and trailers. I'll start this description with a high-altitude view of a page's parts, then I'll describe each part of a page. Finally, I'll show an example. This discussion deals only with the most common format, for the leaf page of a data file.
[edit] High-Altitude View
An InnoDB page has seven parts:
- Fil Header
- Page Header
- Infimum + Supremum Records
- User Records
- Free Space
- Page Directory
- Fil Trailer
As you can see, a page has two header/trailer pairs. The inner pair, "Page Header" and "Page Directory", are mostly the concern of the \page program group, while the outer pair, "Fil Header" and "Fil Trailer", are mostly the concern of the \fil program group. The "Fil" header also goes by the name of "File Page Header".
Sandwiched between the headers and trailers, are the records and the free (unused) space. A page always begins with two unchanging records called the Infimum and the Supremum. Then come the user records. Between the user records (which grow downwards) and the page directory (which grows upwards) there is space for new records.
[edit] Fil Header
The Fil Header has eight parts, as follows:
| Name | Size | Remarks |
FIL_PAGE_SPACE |
4 | 4 ID of the space the page is in |
FIL_PAGE_OFFSET |
4 | ordinal page number from start of space |
FIL_PAGE_PREV |
4 | offset of previous page in key order |
FIL_PAGE_NEXT |
4 | offset of next page in key order |
FIL_PAGE_LSN |
8 | log serial number of page's latest log record |
FIL_PAGE_TYPE |
2 | current defined types are: FIL_PAGE_INDEX, FIL_PAGE_UNDO_LOG, FIL_PAGE_INODE, FIL_PAGE_IBUF_FREE_LIST |
FIL_PAGE_FILE_FLUSH_LSN |
8 | "the file has been flushed to disk at least up to this lsn" (log serial number), valid only on the first page of the file |
FIL_PAGE_ARCH_LOG_NO |
4 | the latest archived log file number at the time that FIL_PAGE_FILE_FLUSH_LSN was written (in the log) |
FIL_PAGE_SPACEis a necessary identifier because different pages might belong to different (table) spaces within the same file. The word "space" is generic jargon for either "log" or "tablespace".FIL_PAGE_PREVandFIL_PAGE_NEXTare the page's "backward" and "forward" pointers. To show what they're about, I'll draw a two-level B-tree.
--------
- root -
--------
|
----------------------
| |
| |
-------- --------
- leaf - <--> - leaf -
-------- --------
Everyone has seen a B-tree and knows that the entries in the root page point to the leaf pages. (I indicate those pointers with vertical '|' bars in the drawing.) But sometimes people miss the detail that leaf pages can also point to each other (I indicate those pointers with a horizontal two-way pointer '<-->' in the drawing). This feature allows InnoDB to navigate from leaf to leaf without having to back up to the root level. This is a sophistication which you won't find in the classic B-tree, which is why InnoDB should perhaps be called a B+-tree instead.
- The fields
FIL_PAGE_FILE_FLUSH_LSN,FIL_PAGE_PREV, andFIL_PAGE_NEXTall have to do with logs, so I'll refer you to my article How Logs Work With MySQL And InnoDB ondevarticles.com. FIL_PAGE_FILE_FLUSH_LSNandFIL_PAGE_ARCH_LOG_NOare valid only for the first page of a data file.
[edit] Page Header
The Page Header has 14 parts, as follows:
| Name | Size | Remarks |
PAGE_N_DIR_SLOTS |
2 | number of directory slots in the Page Directory part; initial value = 2 |
PAGE_HEAP_TOP |
2 | record pointer to first record in heap |
PAGE_N_HEAP |
2 | number of heap records; initial value = 2 |
PAGE_FREE |
2 | record pointer to first free record |
PAGE_GARBAGE |
2 | "number of bytes in deleted records" |
PAGE_LAST_INSERT |
2 | record pointer to the last inserted record |
PAGE_DIRECTION |
2 | either PAGE_LEFT, PAGE_RIGHT, or PAGE_NO_DIRECTION |
PAGE_N_DIRECTION |
2 | number of consecutive inserts in the same direction, e.g. "last 5 were all to the left" |
PAGE_N_RECS |
2 | number of user records |
PAGE_MAX_TRX_ID |
8 | the highest ID of a transaction which might have changed a record on the page (only set for secondary indexes) |
PAGE_LEVEL |
2 | level within the index (0 for a leaf page) |
PAGE_INDEX_ID |
8 | identifier of the index the page belongs to |
PAGE_BTR_SEG_LEAF |
10 | "file segment header for the leaf pages in a B-tree" (this is irrelevant here) |
PAGE_BTR_SEG_TOP |
10 | "file segment header for the non-leaf pages in a B-tree" (this is irrelevant here) |
(Note: I'll clarify what a "heap" is when I discuss the User Records part of the page.)
Some of the Page Header parts require further explanation:
PAGE_FREE:
Records which have been freed (due to deletion or migration) are in a one-way linked list. The PAGE_FREE pointer in the page header points to the first record in the list. The "next" pointer in the record header (specifically, in the record's Extra Bytes) points to the next record in the list.
PAGE_DIRECTIONandPAGE_N_DIRECTION:
It's useful to know whether inserts are coming in a constantly ascending sequence. That can affect InnoDB's efficiency.
PAGE_HEAP_TOPandPAGE_FREEandPAGE_LAST_INSERT:
Warning: Like all record pointers, these point not to the beginning of the record but to its Origin (see the earlier discussion of Record Structure).
PAGE_BTR_SEG_LEAFandPAGE_BTR_SEG_TOP:
These variables contain information (space ID, page number, and byte offset) about index node file segments. InnoDB uses the information for allocating new pages. There are two different variables because InnoDB allocates separately for leaf pages and upper-level pages.
[edit] The Infimum and Supremum Records
"Infimum" and "supremum" are real English words but they are found only in arcane mathematical treatises, and in InnoDB comments. To InnoDB, an infimum is lower than the lowest possible real value (negative infinity) and a supremum is greater than the greatest possible real value (positive infinity). InnoDB sets up an infimum record and a supremum record automatically at page-create time, and never deletes them. They make a useful barrier to navigation so that "get-prev" won't pass the beginning and "get-next" won't pass the end. Also, the infimum record can be a dummy target for temporary record locks.
The InnoDB code comments distinguish between "the infimum and supremum records" and the "user records" (all other kinds).
It's sometimes unclear whether InnoDB considers the infimum and supremum to be part of the header or not. Their size is fixed and their position is fixed, so I guess so.
[edit] User Records
In the User Records part of a page, you'll find all the records that the user inserted.
There are two ways to navigate through the user records, depending whether you want to think of their organization as an unordered or an ordered list.
An unordered list is often called a "heap". If you make a pile of stones by saying "whichever one I happen to pick up next will go on top" rather than organizing them according to size and colour then you end up with a heap. Similarly, InnoDB does not want to insert new rows according to the B-tree's key order (that would involve expensive shifting of large amounts of data), so it inserts new rows right after the end of the existing rows (at the top of the Free Space part) or wherever there's space left by a deleted row.
But by definition the records of a B-tree must be accessible in order by key value, so there is a record pointer in each record (the "next" field in the Extra Bytes) which points to the next record in key order. In other words, the records are a one-way linked list. So InnoDB can access rows in key order when searching.
[edit] Free Space
I think it's clear what the Free Space part of a page is, from the discussion of other parts.
[edit] Page Directory
The Page Directory part of a page has a variable number of record pointers. Sometimes the record pointers are called "slots" or "directory slots". Unlike other DBMSs, InnoDB does not have a slot for every record in the page. Instead it keeps a sparse directory. In a fullish page, there will be one slot for every six records.
The slots track the records' logical order (the order by key rather than the order by placement on the heap). Therefore, if the records are 'A' 'B' 'F' 'D' the slots will be (pointer to 'A') (pointer to 'B') (pointer to 'D') (pointer to 'F'). Because the slots are in key order, and each slot has a fixed size, it's easy to do a binary search of the records on the page via the slots.
(Since the Page Directory does not have a slot for every record, binary search can only give a rough position and then InnoDB must follow the "next" record pointers. InnoDB's "sparse slots" policy also accounts for the n_owned field in the Extra Bytes part of a record: n_owned indicates how many more records must be gone through because they don't have their own slots.)
[edit] Fil Trailer
The Fil Trailer has one part, as follows:
| Name | Size | Remarks |
FIL_PAGE_END_LSN |
8 | low 4 bytes = checksum of page, last 4 bytes = same as FIL_PAGE_LSN |
The final part of a page, the fil trailer (or File Page Trailer), exists because InnoDB's architect worried about integrity. It's impossible for a page to be only half-written, or corrupted by crashes, because the log-recovery mechanism restores to a consistent state. But if something goes really wrong, then it's nice to have a checksum, and to have a value at the very end of the page which must be the same as a value at the very beginning of the page.
[edit] Example
For this example, I used Borland's TDUMP again, as I did for the earlier chapter on Record Format. This is what a page looked like:
| Address Values in Hexadecimal | Values in ASCII |
0D4000: 00 00 00 00 00 00 00 35 FF FF FF FF FF FF FF FF |
.......5........ |
0D4010: 00 00 00 00 00 00 E2 64 45 BF 00 00 00 00 00 00 |
.......dE....... |
0D4020: 00 00 00 00 00 00 00 05 02 F5 00 12 00 00 00 00 |
................ |
0D4030: 02 E1 00 02 00 0F 00 10 00 00 00 00 00 00 00 00 |
................ |
0D4040: 00 00 00 00 00 00 00 00 00 14 00 00 00 00 00 00 |
................ |
0D4050: 00 02 16 B2 00 00 00 00 00 00 00 02 15 F2 08 01 |
................ |
0D4060: 00 00 03 00 89 69 6E 66 69 6D 75 6D 00 09 05 00 |
.....infimum.... |
0D4070: 08 03 00 00 73 75 70 72 65 6D 75 6D 00 22 1D 18 |
....supremum.".. |
0D4080: 13 0C 06 00 00 10 0D 00 B7 00 00 00 00 04 14 00 |
................ |
0D4090: 00 00 00 09 1D 80 00 00 00 2D 00 84 41 41 41 41 |
.........-..AAAA |
0D40A0: 41 41 41 41 41 41 41 41 41 41 41 1F 1B 17 13 0C |
AAAAAAAAAAA..... |
... |
?? |
... |
?? |
0D7FE0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 74 |
...............t |
0D7FF0: 02 47 01 AA 01 0A 00 65 3A E0 AA 71 00 00 E2 64 |
.G.....e:..q...d |
Let's skip past the first 38 bytes, which are Fil Header. The bytes of the Page Header start at location 0d4026 hexadecimal:
| Location | Name | Description |
00 05 |
PAGE_N_DIR_SLOTS |
There are 5 directory slots. |
02 F5 |
PAGE_HEAP_TOP |
At location 0402F5, not shown, is the beginning of free space. Maybe a better name would have been PAGE_HEAP_END. |
00 12 |
PAGE_N_HEAP |
There are 18 (hexadecimal 12) records in the page. |
00 00 |
PAGE_FREE |
There are zero free (deleted) records. |
00 00 |
PAGE_GARBAGE |
There are zero bytes in deleted records. |
02 E1 |
PAGE_LAST_INSERT |
The last record was inserted at location 02E1, not shown, within the page. |
00 02 |
PAGE_DIRECTION |
A glance at page0page.h will tell you that 2 is the #defined value for PAGE_RIGHT. |
00 0F |
PAGE_N_DIRECTION |
The last 15 (hexadecimal 0F) inserts were all done "to the right" because I was inserting in ascending order. |
00 10 |
PAGE_N_RECS |
There are 16 (hexadecimal 10) user records. Notice that PAGE_N_RECS is smaller than the earlier field, PAGE_N_HEAP. |
00 00 00 00 00 00 00 |
PAGE_MAX_TRX_ID |
?? |
00 00 |
PAGE_LEVEL |
Zero because this is a leaf page. |
00 00 00 00 00 00 00 14 |
PAGE_INDEX_ID |
This is index number 20. |
00 00 00 00 00 00 00 02 16 B2 |
PAGE_BTR_SEG_LEAF |
?? |
00 00 00 00 00 00 00 02 15 F2 |
PAGE_BTR_SEG_TOP |
?? |
Immediately after the page header are the infimum and supremum records. Looking at the "Values In ASCII" column in the hexadecimal dump, you will see that the contents are in fact the words "infimum" and "supremum" respectively.
Skipping past the User Records and the Free Space, many bytes later, is the end of the 16KB page. The values shown there are the two trailers.
- The first trailer (
00 74, 02 47, 01 AA, 01 0A, 00 65) is the page directory. It has 5 entries, because the header fieldPAGE_N_DIR_SLOTSsays there are 5. - The next trailer (
3A E0 AA 71, 00 00 E2 64) is the fil trailer. Notice that the last four bytes,00 00 E2 64, appeared before in the fil header.
[edit] Where to Look For More Information
References:
The most relevant InnoDB source-code files are page0page.c, page0page.ic, and page0page.h in the page directory.


