
python - re模块(正则表达式)
元字符介绍:
. 单个字符匹配
^ 以字符开头匹配 在[]里面作为非
$ 以字符结尾匹配
A|B 匹配A或者B的字符串
注意 : |
>>> re.findall(r"\d+@(?:qq|163).com","270342229@163.comdwa1923949@qq.combfew") ['270342229@163.com', '1923949@qq.com']
* (0,无穷多)重复匹配符号前字符
+ (1,无穷多)重复匹配符号前字符
? (0,1)重复匹配符号前字符
*和+区别:
>>> re.findall("aaf*","dwaadhtfhdw") ['aa'] >>> re.findall("aaf+","dwaadhtfhdw") []
{} 重复万金油
{0,}等同于 *
{1,}等同于+
{0,1}等同于?
{3}重复3次
[] 匹配大括号内的字符
[a] 匹配大廓内的字符一次
[a-z] 匹配a-z中任意字符一次
[0-9] 匹配0-9中任意字符一次
[^a-z] 非字符a-z一次
>>> re.findall("\([^()]*\)",'2*(3+(2*4-(9+4)))') ['(9+4)'] >>> #找到最内层的括号
分组
() 将数据分组匹配
(?P<name>) 命名分组
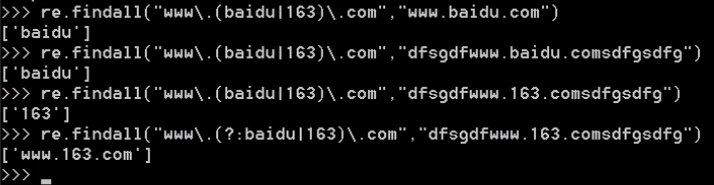
#在运行分组的时候千万要注意!!!!!!!!!!!!!
>>> re.findall("(abc)","abcabcabc") ['abc', 'abc', 'abc'] >>> re.findall("(abc)+","abcabcabc") ['abc'] >>> re.findall("(?:abc)","abcabcabc") ['abc', 'abc', 'abc'] >>> re.findall("(?:abc)+","abcabcabc") ['abcabcabc'] >>>
#应用分组后,匹配规则优先反馈分组内的数据.
应用:
re.search().group(name)
>>> re.search(r"(?P<zjm>主机名)(?P<id>\w{2}\d+)","主机名PC201808110908n7旗舰版").group("zjm") '主机名' >>> re.search(r"(?P<zjm>主机名)(?P<id>\w{2}\d+)","主机名PC201808110908n7旗舰版").group("id") 'PC201808110908' >>>
特殊符号:
\d 匹配数字,[0-9]
\D 匹配任何非数据[^0-9]
\s 匹配任何空白字符,[\t\n\r\f\v]
\S 匹配任何非空白字符,[^\t\n\r\f\v]
\w 匹配任何字母数字,[a-zA-Z0-9]
\W 匹配任何非字符数字[^a-zA-Z0-9]
\b 匹配一个reshuffle字符边界,空格,&,#等
re 方法:
import re #导入模块
re.findall() 找到匹配数据,返回一个 列表类型
re.match() 找到匹配数据,返回一个对象(包含匹配字符位置以及字符) 可以group取出数据
re.split() 找到匹配数据,已找到数据分割
re.sub() 参数:re.sub("匹配规则","替换规则",字符串,替换次数)
compile方法
obj = re.compile
obj.re方法(字符串)
>>> obj = re.compile("\d") >>> obj.findall("123dasda323432") ['1', '2', '3', '3', '2', '3', '4', '3', '2'] >>>
re.finditer() 将匹配到的数据转换成生成器. .__next__.group()获取数据.
练习题:
1.邮箱地址匹配:
import re #从中找到4条邮箱地址: #识别模式:数字+@+qq|163|135.com msg = "sdfefsefEGDFSBD234T37YCUN32JF6SC5621RKI9JSF455342229@qq.comewfjskdbfui123546165@163.comu12hjhuigyusjnef6458125646@135.comdehghsfase3267846@qq.comdhwagdshfbhagfdhsfwef" #以列表形式返回: email = re.findall("(\d+@(?:163|qq|135).com)",msg) print(email) #以单条数据返回 email2 = re.finditer("(\d+@(?:163|qq|135).com)",msg) print(next(email2).group()) print(next(email2).group()) print(next(email2).group()) print(next(email2).group())
2.利用分组匹配获取字典数据:
data4= re.finditer(r"(?P<id>\d+)*(?P<name>[a-z]+)","123,.........,,,abc") print(data4.__next__().groupdict())

3.MAC地址匹配:
#测试地址 # fe80::3c1b:a04c:f803:aea2 # fe80::814d:cf95:1882:3cf7 # fe80:814d:1882:3cf7:a04c:3cf7 b = re.search(r"(?:\w+|\S\W){12}","fe80::3c1b:a04c:f803:aea2") print(b.group())
4.匹配字符串括号内以及括号内最内层的数据
import re a = re.findall(r"\([^(]*[^)]\)","3+(4+4)+(2+3+(3*(5/3)))-4*(2+7)") print(a)
5.同一条匹配规则,不同的匹配内容(注意re方法正确使用)
import re info = "1-2*(60-30+((40/(5+(3*7))+3)+(9+22))" x= re.search(r"\([^(]([\d+\.\d|\-\d+\.\d+|\-|\*|\/]+)[^)]\)",info) print(x.group()) x= re.findall(r"\([^(]([\d+\.\d|\-\d+\.\d+|\-|\*|\/]+)[^)]\)",info) print(x)
re.search 用来查找,单个的字符串,从中提取所需的,不同域值,即不同group的值;
re.findall 一次性提前多个匹配到
- 单个完整的字符串(可以后续接着用re.search再去提取不同group的值)
- 一个tuple值,其中包括了每个group的值 -> 省却了在用re.search提起不同组的值
PS:匹配数据的四种模式应当要注意:
1.无分组无命名 匹配
2.分组无命名单组 匹配
3.分组无命名 全组匹配
4.分组命名 匹配
lP_noGroup = "http://\w+\.\w+\.\w+.+?/\w+?.jpg" # 1.无分组无命名 匹配 lP_unnamedGroup = "http://(\w+)\.(\w+)\.(\w+).+?/(\w+?).jpg" # 2.分组无命名单组 匹配(不带命名的) lP_nonCapturingGroup = "http://(?:\w+)\.(?:\w+)\.(?:\w+).+?/(?:\w+?).jpg" # 3.分组无命名 全组匹配(非捕获的组) lP_namedGroup = "http://(?P<field1>\w+)\.(?P<field2>\w+)\.(?P<field3>\w+).+?/(?P<filename>\w+?).jpg" # 4.分组命名 匹配(带命名的)
