



HDFS体系结构
1.5.1 Replica Placement: The First Baby Seteps
1.8.1 Data Disk Failure, Heartbeats and Re-Replication
1.HDFS体系结构
1.1介绍
HDFS是分布式文件系统,运行在商用的硬件环境上。和其他的分布式文件系统相似。但是也有不同,HDFS是高度容错的并且设计用来部署在低成本的硬件上。HDFS提供高吞吐量,比较适合大数据的应用。HDFS释放POSIX来启动流方式的访问文件系统数据。HDFS原来是Apache Nutch网页搜索引擎的底层服务。HDFS是Apache Hadoop Core项目的一部分。
1.2假设和目标
略
1.3 NameNode和 DataNode
HDFS有Master Slave体系结构。HDFS集群包含一个NameNode,master服务管理文件系统命名空间和控制client访问。另外有一些Datanodes,通常Cluster中一个node有一个datanode。用来管理node的空间。HDFS暴露文件系统命名空间允许用户数据保存在文件中。在内部,文件会被分为多个块并且这些块被保存在一些datanode上。Namenode执行文件系统命名空间操作,比如打开,关闭,重命名文件和目录。也决定了datanode 的块映射。Datanode为client读写请求服务。Datanode也执行block的创建,删除,根据namenode的指令复制。

Namenode和datanode是软件的一部分。HDFS使用java开发,任何支持java的设备都可以运行namenode和datanode。部署通常有一个专用的机器用来执行namenode。其他的设备运行datanode。当然也可以在一个设备上运行多个datanode,但是一般很少出现。
1.4 文件系统命名空间
HDFS支持传统的分层的文件组织,一个用户或者应用程序创建目录,文件存在这些目录中。文件系统命名空间分层和其他现有的文件系统类似。可以创建,删除文件,移动文件,重命名文件。HDFS支持用户配额和访问权限。HDFS不支持硬链接或者软连接。但是HDFS不排除这些功能的实现。
Namenode维护文件系统的命名空间。任何修改文件系统命名空间或者属性都被记录在Namenode里面。一个引用程序可以指定一个文件多个副本维护在HDFS里面。这些信息也放在namenode里面。
1.5 数据复制
HDFS设计用来保存大文件到一个大集群上。每个文件都以顺序的块存储。块被复制用来容错。块的大小和复制参数可以为每个文件配置。文件中的所有的块大小都是一样的,while users can start a new block without filling out the last block to the configured block size after the support for variable length block was added to append and hsync.
应用可以指定文件的副本个数。复制参数可以在文件创建的时候创建,之后可以修改。HDFS的文件是write-once(除了append和truncate),并且在任何时间都是严格的1个writer。
Namenode决定所有的关于复制的块。定期会接收一个心跳和一个block report。接受一个心跳表示datanode还活着,block report表示datanode的所有block。
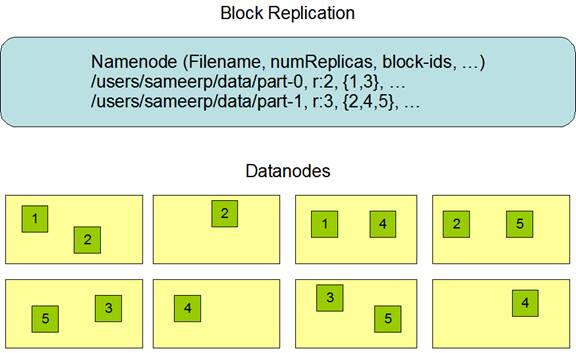
1.5.1 Replica Placement: The First Baby Seteps
副本的安置对HDFS的可靠性和性能来说是很重要的。优化副本的安置是HDFS和其他分布式文件系统的区别。这个特性需要有很多的经验和调整。目的是机架级别的安置策略,用来提高数据可靠性,可用性和网络带宽利用。
对于很大的HDFS集群来说,通常会传播到很多机架。不通机架间的node交互需要路过交换机。在很多情况下同一个机架下的网络带宽比不通机架下的设备带宽搞。
Namenode为每个datanode决定rackid,通过Hadoop Rack Awareness来识别。一个最简单的策略是把副本放到不通的机架下面。这样如果整个机架错误了允许使用其他的机架下的数据。这个策略均匀的把副本分布到集群,可以很简单的让它在出现错误的时候来均衡。但是这个策略增加了写入的开销,因为要写入到多个机架下。
对于最通常的例子,复制参数是3,HDFS放置策略是如果writer在本地,那么放在本地也就是写入的那个datanode,否则随机随机选择一个datanode,第二个放在一个不通的机架下的datanode上。第三个放在相同的机架的不通datanode下。这个策略减小了机架间的传输,提高了写入性能。机架出现故障的概率远小于一个node出现错误的概率,这个策略不影响可靠性和可用性的保证。但是减少了网络带宽的使用,因为一个block只在2个机架中,而不是3个机架。但是这个策略不能让数据均匀的分布。1/3的副本在一个node中,2/3的副本在一个机架下,其他剩下的均匀的分布在剩下的机架下。这个策略提高了写入性能并没有和可靠性和读性能冲突。
如果副本参数大于3,那么第4个副本或者之后的副本是随机存放的,但是每个机架存放副本的个数有个上限,(replicas - 1) / racks + 2。
因为namenode不允许datanode拥有同一个block的多个副本,副本的最大个数,就是datanode 的个数。
Storage Types and Storage Policies支持了之后,namenode除了Rack awareness之外,还考虑了这个策略。Namenode选择node先基于rack awareness,然后检查候选node的存储需求。如果候选node没有storage type,namenode会查看其它node。如果在第一个path的node不够,那么namenode在第二个path查找storage path。
1.5.2 副本选择
为了最小化带宽和读延迟,HDFS会尝试从最近的一个副本上读取。如果在同一个机架上面有一个可读副本,这个副本是被读取的首选。如果HDFS集群跨了多个数据中心,那么本地的数据中心会被首选。
1.5.3 安全模式
在startup的时候,namenode会进入特别的状态叫做safemode。在safemode下,数据块的复制是不会发生的。Namenode从datanode上接受到心跳和blockreport。Blockreport包含了datanode拥有的所有block。每个block有个副本的最小值。一个block如果在namenode中被检查完后,那么就认为是安全的。如果安全率到达某个值,那么namenode就退出安全模式。如果发现有一些数据块的副本不够,那么就会创建这些数据库的副本。
1.6 文件系统元数据保存
HDFS的命名空间保存在namenode上。Namenode使用事务日志叫editlog来保存记录的修改。比如创建一个新的文件,namenode就会插入一条记录到editlog。同样的修改复制参数也会在editlog上创建一条机滤。Namenode在系统的文件系统上保存editlog。整个文件系统的命名空间,包括block和文件的映射,文件系统的属性。都被保存在fsimage中。Fsimage也被保存在本地文件系统上。
Namenode在内存中,保存了整个文件系统命名空间和文件block map的快照。当namenode启动,或者出发checkpoint,就会从磁盘中把fsimage和editlog读出来,应用所有editlog上的事务,到内存中的fsimage,然后重新刷新到磁盘中的fsimage。然后可以截断,因为已经被应用到磁盘fsimage。这个过程叫checkpoint。目的是保证HDFS有一致性的文件系统元数据。尽管读取fsimage速度很快,但是增量的直接修改fsimage并不快。我们不直接修改fsimage,而是保存在editlog中。在checkpoint的时候然后应用的fsimage上。Checkpoint的周期可以通过参数dfs.namenode.checkpoint.period 指定时间间隔来触发,也可以使用dfs.namenode.checkpoint.txns指定多少个事务之后触发。如果都设置了,那么第一个触发就会checkpoint。
HDFS数据在datanode中以文件的方式被保存在本地文件系统上。Datanode不会在意HDFS文件。HDFS数据每个block一个文件保存在本地文件系统上。Datanode不会把所有的文件都放在一个目录下面。而是使用一个启发式结构来确定,每个目录的最优文件个数,并且适当的创建子目录。当datanode启动,会扫描本地文件系统,生成一个HDFS的列表,并且发送给namenode。这个report叫blockreport。
1.7 The Communication协议
所有HDFS交互协议都是基于tcp/ip的client创建一个连接到namenode机器。使用clientprotocol和namenode交互,datanode使用datanode protocol和namenode交互。Namenode并不开启任何RPC。只是对datanode 和client的反应。
1.8 Robustness
尽管存在错误,HDFS保存数据还是可靠的。一下是一些namenode错误,datanode错误和网络分区。
1.8.1 Data Disk Failure, Heartbeats and Re-Replication
每个datanode会发送心跳信息到namenode。网络分区会导致子网的datanode和namenode 的连接中断。Namenode通过心跳信息来发现。Namenode把没有收到心跳信息的node标记为死亡,并且发送新的IO请求到这个node。任何数据在死亡的datanode不在对HDFS可用。Datanode 的死亡会导致一些block的复制参数少于指定的值。Namenode会不间断的跟踪这些需要复制的block,并且在有需要的时候启动复制。需要重新复制的理由可能很多:datanode变的不可用,副本损坏,datanode所在的硬件损坏,或者复制参数增加。
1.8.2 Cluster Rebalancing
HDFS结构兼容数据再平衡框架。如果一个datanode的空闲超过了阀值,一个框架可能把数据从一个datanode移动到另外一个。如果一个特定的文件请求特别高,框架会动态的创建副本并且再平衡数据。数据再平衡目前没有实现。
1.8.3 数据完整性
一个block的数据出现损坏是很有可能的。出现损坏,可能是磁盘问题,网络问题或者有bug。HDFS客户端软件实现了checksum检查HDFS文件的内容。当一个客户端创建了HDFS文件。会为每个block计算checksum并且保存在在同一个命名空间下,独立的隐藏文件下。当client获取文件内容,需要验证每个datanode的checksum和checksum文件中的一致。如果不一致,从副本上获取。
1.8.4 元数据磁盘错误
Fsiamge和editlog是HDFS结构的核心。如果出现损坏,会导致HDFS实例无法运行。因为这个可以配置fsimage和editlog多个副本。任何更新fsimage和editlog会同步的更新副本。同步的更新fsiamge和editlog可能会导致性能问题。然而还是可以接受的,因为HDFS是数据敏感而不是元数据敏感的。当namenode重启会选择最新的fsimage和editlog使用。
另外一个选项是使用多namenode启动HA,或者使用NFS共享存储,分布式的editlog。
1.8.5 快照
快照是被支持的。快照的一个用处是修复HDFS。
1.9 数据组织
1.9.1 数据块
HDFS被设计用来支持非常大的文件。应用使用HDFS来处理这些文件。这些应用只写一次但是要读很多次。HDFS支持write-once-read-many。通常HDFS block大小是128MB。因此HDFS会被切成128MB的块。
1.9.2 复制流水
当client写数据到HDFS,并且复制参数是3,namenode会获取datanode的一个列表使用复制选择算法。这些列表包含了datanode 的副本block。Client然后写入第一个datanode。第一个datanode一部分一部分的接受数据,把每个部分写到本地的存储库中并且把这部分传输到list中的第二个datanode。第二个datanode,一样接受数据,然后存储到本地存储库,然后传输到第三个datanode。第三个datanode,接受数据保存到本地存储库。因此数据是以pipeline的方式从一个到另外一个。
1.10 可访问性
HDFS可以以不同的方式被访问。最原始的使用java 的API。也可以使用http浏览器。HDFS可以被mount到client本地文件系统。
1.10.1 FSShell
HDFS允许用户数据以目录和文件的方式组织。提供了命令行借口FSShell可以让用户和HDFS交互。语法和bash类似。
|
Action |
Command |
|
Create a directory named /foodir |
bin/hadoop dfs -mkdir /foodir |
|
Remove a directory named /foodir |
bin/hadoop fs -rm -R /foodir |
|
View the contents of a file named /foodir/myfile.txt |
bin/hadoop dfs -cat /foodir/myfile.txt |
1.10.2 DFSAdmin
DFSAdmin命令主要用来管理HDFS集群。
|
Action |
Command |
|
Put the cluster in Safemode |
bin/hdfs dfsadmin -safemode enter |
|
Generate a list of DataNodes |
bin/hdfs dfsadmin -report |
|
Recommission or decommission DataNode(s) |
bin/hdfs dfsadmin -refreshNodes |
1.10.3 浏览器接口
HDFS安装配置了web服务来暴露HDFS的命名空间。允许通过浏览器查看和定位文件。
1.11 空间回收
1.11.1文件删除和不删除
如果trash配置启用了,FSShell删除的文件并不会马上从HDFS上面删除。HDFS会把这些移动到trash目录中(/user/<username>/.Trash)。这样文件可以快速的恢复。
最近被删除的文件会被移动到当前的trash目录(/user/<username>/.Trash/Current),根据checkpoint的配置,HDFS为当前的删除创建checkpoint(/user/<username>/.Trash/<date>),到期后会删除老的checkpoint。查看 expunge command of FS shell
到期之后,namenode会删除文件的元数据。删除后会导致相关的block被回收。例子如下:
创建2个文件
$ hadoop fs -mkdir -p delete/test1
$ hadoop fs -mkdir -p delete/test2
$ hadoop fs -ls delete/
Found 2 items
drwxr-xr-x - hadoop hadoop 0 2015-05-08 12:39 delete/test1
drwxr-xr-x - hadoop hadoop 0 2015-05-08 12:40 delete/test2
删除一个文件根据提示被移动到了trash目录
$ hadoop fs -rm -r delete/test1
Moved: hdfs://localhost:9820/user/hadoop/delete/test1 to trash at: hdfs://localhost:9820/user/hadoop/.Trash/Current
删除test2,但是跳过trash
$ hadoop fs -rm -r -skipTrash delete/test2
Deleted delete/test2
最后只会看到trash中的一个文件
$ hadoop fs -ls .Trash/Current/user/hadoop/delete/
Found 1 items\
drwxr-xr-x - hadoop hadoop 0 2015-05-08 12:39 .Trash/Current/user/hadoop/delete/test1
1.11.2 减少复制数量
当复制数量减少,namenode会选择多余的副本进行删除。在下一次心跳传输给datanode,datanode然后删除响应的块,释放空间。通过setReplication API设置到真正释放空间有延迟。
1.12 Reference
Hadoop JavaDoc API.
HDFS source code: http://hadoop.apache.org/version_control.html

