

python入门
Python介绍
目前Python主要应用领域:
- 云计算: 云计算最火的语言, 典型应用OpenStack
- WEB开发: 众多优秀的WEB框架,众多大型网站均为Python开发,Youtube, Dropbox, 豆瓣。。。, 典型WEB框架有Django
- 科学运算、人工智能: 典型库NumPy, SciPy, Matplotlib, Enthought librarys,pandas
- 系统运维: 运维人员必备语言
- 金融:量化交易,金融分析,在金融工程领域,Python不但在用,且用的最多,而且重要性逐年提高。原因:作为动态语言的Python,语言结构清晰简单,库丰富,成熟稳定,科学计算和统计分析都很牛逼,生产效率远远高于c,c++,java,尤其擅长策略回测
- 图形GUI: PyQT, WxPython,TkInter
Python 是一门什么样的语言?
动态解释型强类型,交互式,面向对象语言的语言
编译和解释的区别是什么?
编译器是把源程序的每一条语句都编译成机器语言,并保存成二进制文件,这样运行时计算机可以直接以机器语言来运行此程序,速度很快;
而解释器则是只在执行程序时,才一条一条的解释成机器语言给计算机来执行,所以运行速度是不如编译后的程序运行的快的.
编译型vs解释型
编译型
优点:编译器一般会有预编译的过程对代码进行优化。因为编译只做一次,运行时不需要编译,所以编译型语言的程序执行效率高。可以脱离语言环境独立运行。
缺点:编译之后如果需要修改就需要整个模块重新编译。编译的时候根据对应的运行环境生成机器码,不同的操作系统之间移植就会有问题,需要根据运行的操作系统环境编译不同的可执行文件。
解释型
优点:有良好的平台兼容性,在任何环境中都可以运行,前提是安装了解释器(虚拟机)。灵活,修改代码的时候直接修改就可以,可以快速部署,不用停机维护。
缺点:每次运行的时候都要解释一遍,性能上不如编译型语言。
Python的优缺点
优点:
Python的定位是“优雅”、“明确”、“简单”,所以Python程序看上去总是简单易懂
开发效率非常高,Python有非常强大的第三方库,基本上你想通过计算机实现任何功能
可移植性————由于它的开源本质,Python已经被移植在许多平台上
可扩展性————如果你需要你的一段关键代码运行得更快或者希望某些算法不公开,你可以把你的部分程序用C或C++编写,然后在你的Python程序中使用它们。
可嵌入性————你可以把Python嵌入你的C/C++程序,从而向你的程序用户提供脚本功能
缺点:
速度慢,Python 的运行速度相比C语言确实慢很多,跟JAVA相比也要慢一些,是边编译边解释的语言
代码不能加密,因为PYTHON是解释性语言,它的源码都是以名文形式存放的
线程不能利用多CPU问题,这是Python被人诟病最多的一个缺点,GIL即全局解释器锁
Python解释器
CPython:这个解释器是用C语言开发的,所以叫CPython。在命令行下运行python就是启动CPython解释器。
IPython: IPython是基于CPython之上的一个交互式解释器,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的。
CPython用>>>作为提示符,而IPython用In [序号]:作为提示符
PyPy: PyPy是另一个Python解释器,它的目标是执行速度。PyPy采用JIT技术,对Python代码进行动态编译(注意不是解释),所以可以显著提高Python代码的执行速度。
Jython: Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行
IronPython: IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码
小结
Python的解释器很多,但使用最广泛的还是CPython。如果要和Java或.Net平台交互,最好的办法不是用Jython或IronPython,而是通过网络调用来交互,确保各程序之间的独立性。
Hello World程序
在linux下直接执行: ./hello.py 需要明确的指出 hello.py 脚本由 python 解释器来执行,那么就需要在 hello.py 文件的头部指定解释器
#!/usr/bin/env python print "hello,world"
如此一来,执行: ./hello.py 即可
ps:执行前需给予 hello.py 执行权限,chmod 755 hello.py
在交互器中执行
windows和linux下相同,输入命令 : python

- 第一个字符必须是字母表中字母或下划线'_'。
- 变量的其他的部分有字母、数字和下划线组成。
- 变量对大小写敏感。
- 不能是关键字
- 变量名尽量专业
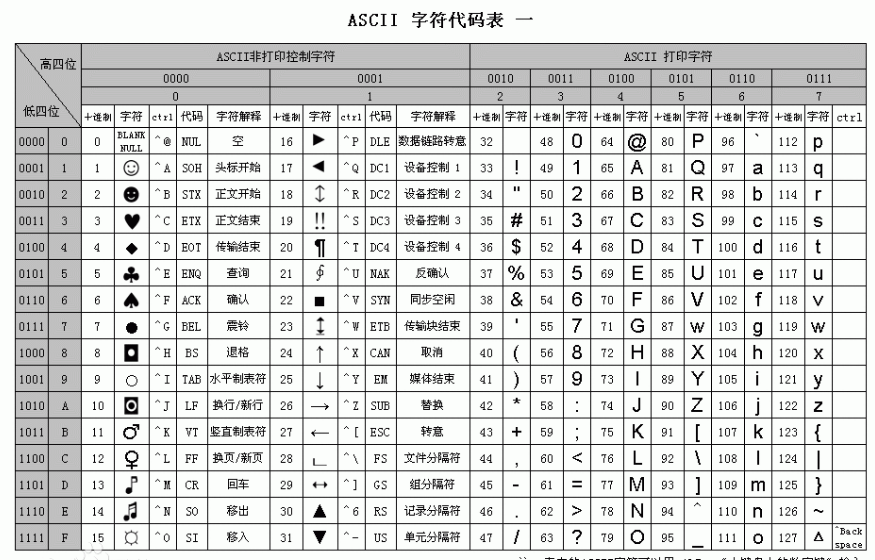
关于中文
为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 2个字节表示,即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
应该显示的告诉python解释器,用什么编码来执行源代码 #!/usr/bin/env python # -*- coding: utf-8 -*- print( "你好")
多行注释:""" 被注释内容 """
模块初识
Python的强大之处在于他有非常丰富和强大的标准库和第三方库,几乎你想实现的任何功能都有相应的Python库支持,以后的课程中会深入讲解常用到的各种库
sys #!/usr/bin/env python # -*- coding: utf-8 -*- import sys print(sys.argv) #输出
$ python test.py helo world
['test.py', 'helo', 'world'] #把执行脚本时传递的参数获取到了
os #!/usr/bin/env python # -*- coding: utf-8 -*- import os os.system("df -h") #调用系统命令
完全结合一下 import os,sys os.system(''.join(sys.argv[1:])) #把用户的输入的参数当作一条命令交给os.system来执行
自己写个模块
python tab补全模块


#!/usr/bin/env python # python startup file import sys import readline import rlcompleter import atexit import os # tab completion readline.parse_and_bind('tab: complete') # history file histfile = os.path.join(os.environ['HOME'], '.pythonhistory') try: readline.read_history_file(histfile) except IOError: pass atexit.register(readline.write_history_file, histfile) del os, histfile, readline, rlcompleter for Linux
你会发现,上面自己写的tab.py模块只能在当前目录下导入,如果想在系统的何何一个地方都使用怎么办呢? 此时你就要把这个tab.py放到python全局环境变量目录里啦,基本一般都放在一个叫 Python/3.5/site-packages 目录下,这个目录在不同的OS里放的位置不一样,用 print(sys.path) 可以查看python环境变量列表。
.pyc是个什么鬼?
1. Python是一门解释型语言?
我初学Python时,听到的关于Python的第一句话就是,Python是一门解释性语言,我就这样一直相信下去,直到发现了*.pyc文件的存在。如果是解释型语言,那么生成的*.pyc文件是什么呢?c应该是compiled的缩写才对啊!
2. 解释型语言和编译型语言
计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,第一种是编译,第二种是解释。
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby
简述Python的运行过程
在说这个问题之前,我们先来说两个概念,PyCodeObject和pyc文件。
我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。
数据类型
2 是一个整数的例子。
长整数 不过是大一些的整数。
3.23和52.3E-4是浮点数的例子
(-5+4j)和(2.3-4.6j)是复数的例子,其中-5,4为实数,j为虚数
int(整型)
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
float(浮点型)
complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
- 移除空白
- 分割
- 长度
- 索引
- 切片
name_list = ['zyp', 'seven', '111'] 或 name_list = list(['zyp', 'seven', '111'])
基本操作:
- 索引
- 切片
- 追加
- 删除
- 长度
- 切片
- 循环
- 包含
ages = (11, 22, 33, 44, 55)
或
ages = tuple((11, 22, 33, 44, 55))
person = {"name": "z", 'age': 18}
或
person = dict({"name": "z", 'age': 18})
常用操作:
- 索引
- 新增
- 删除
- 键、值、键值对
- 循环
- 长度
数据运算
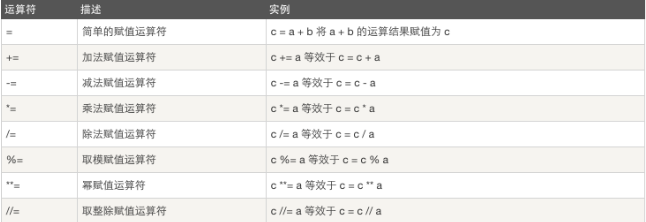
算术运算:
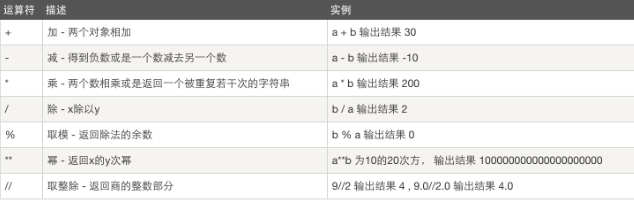
比较运算:
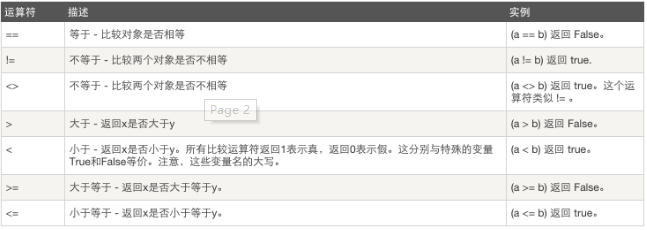
赋值运算:
逻辑运算:

成员运算:

身份运算:

位运算:

#!/usr/bin/python a = 60 # 60 = 0011 1100 b = 13 # 13 = 0000 1101 c = 0 c = a & b; # 12 = 0000 1100 print "Line 1 - Value of c is ", c c = a | b; # 61 = 0011 1101 print "Line 2 - Value of c is ", c c = a ^ b; # 49 = 0011 0001 #相同为0,不同为1 print "Line 3 - Value of c is ", c c = ~a; # -61 = 1100 0011 print "Line 4 - Value of c is ", c c = a << 2; # 240 = 1111 0000 print "Line 5 - Value of c is ", c c = a >> 2; # 15 = 0000 1111 print "Line 6 - Value of c is ", c
按位取反运算规则(按位取反再加1) 详解http://blog.csdn.net/wenxinwukui234/article/details/42119265
运算符优先级:

使用%格式化输出使用 format表达式if ... else
# 提示输入用户名和密码 # 验证用户名和密码 # 如果错误,则输出用户名或密码错误 # 如果成功,则输出 欢迎,XXX! #!/usr/bin/env python # -*- coding: encoding -*- import getpass name = raw_input('请输入用户名:') pwd = getpass.getpass('请输入密码:') if name == "alex" and pwd == "cmd": print("欢迎,alex!") else: print("用户名和密码错误")
场景二、猜年龄游戏
在程序里设定好你的年龄,然后启动程序让用户猜测,用户输入后,根据他的输入提示用户输入的是否正确,如果错误,提示是猜大了还是小了
#!/usr/bin/env python # -*- coding: utf-8 -*- my_age = 28 user_input = int(input("input your guess num:")) if user_input == my_age: print("Congratulations, you got it !") elif user_input < my_age: print("Oops,think bigger!") else: print("think smaller!")
表达式for loop
for i in range(10): print("loop:", i )
#输出 1-10
for循环简单示例-猜年龄流程控制描述
for 和while的说法回到上面for 循环的例子,如何实现让用户不断的猜年龄,但只给最多3次机会,再猜不对就退出程序。
#!/usr/bin/env python # -*- coding: utf-8 -*- my_age = 28 count = 0 while count < 3: user_input = int(input("input your guess num:")) if user_input == my_age: print("Congratulations, you got it !") break elif user_input < my_age: print("Oops,think bigger!") else: print("think smaller!") count += 1 #每次loop 计数器+1 else: print("错太多了.")
1 # !usr/bin/env python 2 # _*_ coding: utf-8 _*_ 3 f=open('user_file',"r+",encoding='utf-8') #创建存用户名和密码的文件 4 f1=open('lock_file','r+',encoding='utf-8') #创建存锁定用户的文件 5 user_pwd=f.readlines() #将文件转为列表 6 lock_user=f1.readlines() 7 #print(user_pwd) 8 user_list=[] #创建存用户名的空列表 9 pwd_list=[] #创建存密码的空列表 10 lock_list=lock_user[:] #创建存锁定用户名的空列表 11 count=0 #初始化一个循环变量 12 for i in user_pwd[0::2]: #通过遍历去掉列表中的换行,并取出列表中所有的用户名 13 user_list.append(i.strip()) # 去掉换行后追加到用户名列表 14 #print(user_list) 15 for j in user_pwd[1::2]: #通过遍历去掉列表中的换行,并取出列表中所有的密码 16 pwd_list.append(j.strip()) # 去掉换行后追加到密码列表 17 #print(pwd_list) 18 for k in lock_user: #通过遍历去掉列表中的换行,并取出列表中所有的被锁定用户 19 lock_list.append(k.strip()) 20 while True: 21 if count<3: #判断小于3次继续循环,大于三次锁定用户并跳出 22 username=input(' Please input user name:') #从屏幕获取用户名 23 if username in lock_list: #判断用户名是否在锁定列表中 24 25 print('%s have been locked'%username) #存在锁定用户 26 break 27 else: 28 if username in user_list: #判断输入的用户名是否存在用户名列表中 29 password=input('Please enter your password:') #从屏幕获取密码 30 if (password in pwd_list) and pwd_list.index(password)==user_list.index(username): #判断密码是否匹配 31 print('Welcome to {0}'.format(username)) 32 break 33 else: 34 print('please input again!') 35 count +=1 #循环体自加1 36 else: 37 print('The {_user} name entiered does not exist'.format(_user=username)) 38 autonomously=input('Continue typing! Enter \'n\', exit!') 39 if autonomously != 'n': 40 continue 41 else: 42 break 43 else: 44 print('You\'ve lost three times and the account has been locked') 45 f1.write(username+'\n') #将要锁定的用户名写入lock_file中 46 break 47 48 f.close() #关闭文件 49 f1.close()
三级菜单
1 info={ #定义一个三级菜单的字典 2 '广东省': 3 {'广州市': 4 { '越秀区':['高氏兄弟','施耐德','阿托菲纳'], 5 '海珠区':['安美特','宝洁','百事'], 6 '天河区':['美赞臣','高露洁','金佰利'] 7 }, 8 '深圳市': 9 {'福田区':['天经大厦','天济大厦','天吉大厦','天祥大厦'], 10 '南山区':['腾讯','创维','中兴'], 11 '罗湖区':['京基一百','老街',] 12 } 13 }, 14 '湖北省': 15 {'武汉市': 16 {'武昌区':['黄鹤楼','宏基','傅家坡'], 17 '汉口区':['新荣','洪山'] 18 }, 19 '黄冈市': 20 {'红安':['a','b'], 21 '浠水':['清泉','洗马'] 22 } 23 }, 24 } 25 while True: 26 for i in info: #获取字典的中的省份,并打印 27 print(i) 28 a=input("请输入要进入的省份:") #从屏幕获取值 29 # print(info[a]) 30 while a in info: #判断输入值是否存在 31 for j in info[a] : #存在,获取字典的中的市,并打印 32 print(j) 33 b=input('请输入要进入市:') #从屏幕获取值 34 while b in info[a]: #判断输入值是否存在 35 for k in info[a][b]: #存在,获取字典的中的区或者县,并打印 36 print(k) 37 c=input('请输入要进入的区') #从屏幕获取值 38 while c in info[a][b]: #判断输入值是否存在 39 for m in info[a][b][c]: #存在,获取字典中区或者县的元素,并打印 40 print(m) 41 jixu=input('是否返回区,县,按任意键继续,按n退出') #让用户选择是否继续查看 42 if jixu != 'n': #继续,就返回上一级 43 break 44 else: #退出 45 exit() 46 else : 47 jixu=input('是否重新输入市,按任意键继续,按n退出') #输入值不存在,继续判断用户是否要继续查找 48 if jixu!='n': 49 break 50 else: 51 exit() 52 else: 53 jixu=input('是否重新输入省,按任意键继续,按n退出') 54 if jixu!='n': 55 break 56 else: 57 exit() 58 else : 59 jixu=input('输入错误,是否继续输入,按任意键继续,按n退出') 60 if jixu!='n': 61 continue 62 else: 63 exit() 64 exit()
