

dubbo源码分析(二):超时原理以及应用场景
本篇主要记录dubbo中关于超时的常见问题,实现原理,解决的问题以及如何在服务降级中体现作用等。
超时问题
为了检查对dubbo超时的理解,尝试回答如下几个问题,如果回答不上来或者不确定那么说明此处需要再多研究研究。
我只是针对个人的理解提问题,并不代表我理解的就是全面深入的,但我的问题如果也回答不了,那至少说明理解的确是不够细的。
- 超时是针对消费端还是服务端?
- 超时在哪设置?
- 超时设置的优先级是什么?
- 超时的实现原理是什么?
- 超时解决的是什么问题?
问题解答
RPC场景
本文所有问题均以下图做为业务场景,一个web api做为前端请求,product service是产品服务,其中调用comment service(评论服务)获取产品相关评论,comment service从持久层中加载数据。

超时是针对消费端还是服务端?
-
如果是争对消费端,那么当消费端发起一次请求后,如果在规定时间内未得到服务端的响应则直接返回超时异常,但服务端的代码依然在执行。
-
如果是争取服务端,那么当消费端发起一次请求后,一直等待服务端的响应,服务端在方法执行到指定时间后如果未执行完,此时返回一个超时异常给到消费端。
dubbo的超时是争对客户端的,由于是一种NIO模式,消费端发起请求后得到一个ResponseFuture,然后消费端一直轮询这个ResponseFuture直至超时或者收到服务端的返回结果。虽然超时了,但仅仅是消费端不再等待服务端的反馈并不代表此时服务端也停止了执行。
按上图的业务场景,看看生成的日志:
product service:报超时错误,因为comment service 加载数据需要5S,但接口只等1S 。
Caused by: com.alibaba.dubbo.remoting.TimeoutException: Waiting server-side response timeout. start time: 2017-08-05 18:14:52.751, end time: 2017-08-05 18:14:53.764, client elapsed: 6 ms, server elapsed: 1006 ms, timeout: 1000 ms, request: Request [id=0, version=2.0.0, twoway=true, event=false, broken=false, data=RpcInvocation [methodName=getCommentsByProductId, parameterTypes=[class java.lang.Long], arguments=[1], attachments={traceId=6299543007105572864, spanId=6299543007105572864, input=259, path=com.jim.framework.dubbo.core.service.CommentService, interface=com.jim.framework.dubbo.core.service.CommentService, version=0.0.0}]], channel: /192.168.10.222:53204 -> /192.168.10.222:7777
at com.alibaba.dubbo.remoting.exchange.support.DefaultFuture.get(DefaultFuture.java:107) ~[dubbo-2.5.3.jar:2.5.3]
at com.alibaba.dubbo.remoting.exchange.support.DefaultFuture.get(DefaultFuture.java:84) ~[dubbo-2.5.3.jar:2.5.3]
at com.alibaba.dubbo.rpc.protocol.dubbo.DubboInvoker.doInvoke(DubboInvoker.java:96) ~[dubbo-2.5.3.jar:2.5.3]
... 42 common frames omittedcomment service : 并没有异常,而是慢慢悠悠的执行自己的逻辑:
2017-08-05 18:14:52.760 INFO 846 --- [2:7777-thread-5] c.j.f.d.p.service.CommentServiceImpl : getComments start:Sat Aug 05 18:14:52 CST 2017
2017-08-05 18:14:57.760 INFO 846 --- [2:7777-thread-5] c.j.f.d.p.service.CommentServiceImpl : getComments end:Sat Aug 05 18:14:57 CST 2017从日志来看,超时影响的是消费端,与服务端没有直接关系。
超时在哪设置?
消费端
- 全局控制
<dubbo:consumer timeout="1000"></dubbo:consumer>- 接口控制
- 方法控制
服务端
- 全局控制
<dubbo:provider timeout="1000"></dubbo:provider>- 接口控制
- 方法控制
可以看到dubbo针对超时做了比较精细化的支持,无论是消费端还是服务端,无论是接口级别还是方法级别都有支持。
超时设置的优先级是什么?
上面有提到dubbo支持多种场景下设置超时时间,也说过超时是针对消费端的。那么既然超时是针对消费端,为什么服务端也可以设置超时呢?
这其实是一种策略,其实服务端的超时配置是消费端的缺省配置,即如果服务端设置了超时,任务消费端可以不设置超时时间,简化了配置。
另外针对控制的粒度,dubbo支持了接口级别也支持方法级别,可以根据不同的实际情况精确控制每个方法的超时时间。所以最终的优先顺序为:客户端方法级>客户端接口级>客户端全局>服务端方法级>服务端接口级>服务端全局。
超时的实现原理是什么?
之前有简单提到过, dubbo默认采用了netty做为网络组件,它属于一种NIO的模式。消费端发起远程请求后,线程不会阻塞等待服务端的返回,而是马上得到一个ResponseFuture,消费端通过不断的轮询机制判断结果是否有返回。因为是通过轮询,轮询有个需要特别注要的就是避免死循环,所以为了解决这个问题就引入了超时机制,只在一定时间范围内做轮询,如果超时时间就返回超时异常。
源码
ResponseFuture接口定义
public interface ResponseFuture {
/**
* get result.
*
* @return result.
*/
Object get() throws RemotingException;
/**
* get result with the specified timeout.
*
* @param timeoutInMillis timeout.
* @return result.
*/
Object get(int timeoutInMillis) throws RemotingException;
/**
* set callback.
*
* @param callback
*/
void setCallback(ResponseCallback callback);
/**
* check is done.
*
* @return done or not.
*/
boolean isDone();
}ReponseFuture的实现类:DefaultFuture
只看它的get方法,可以清楚看到轮询的机制。
public Object get(int timeout) throws RemotingException {
if (timeout <= 0) {
timeout = Constants.DEFAULT_TIMEOUT;
}
if (! isDone()) {
long start = System.currentTimeMillis();
lock.lock();
try {
while (! isDone()) {
done.await(timeout, TimeUnit.MILLISECONDS);
if (isDone() || System.currentTimeMillis() - start > timeout) {
break;
}
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
if (! isDone()) {
throw new TimeoutException(sent > 0, channel, getTimeoutMessage(false));
}
}
return returnFromResponse();
}
超时解决的是什么问题?
设置超时主要是解决什么问题?如果没有超时机制会怎么样?
回答上面的问题,首先要了解dubbo这类rpc产品的线程模型。下图是我之前个人RPC学习产品的示例图,与dubbo的线程模型大致是相同的,有兴趣的可参考我的笔记:简单RPC框架-业务线程池
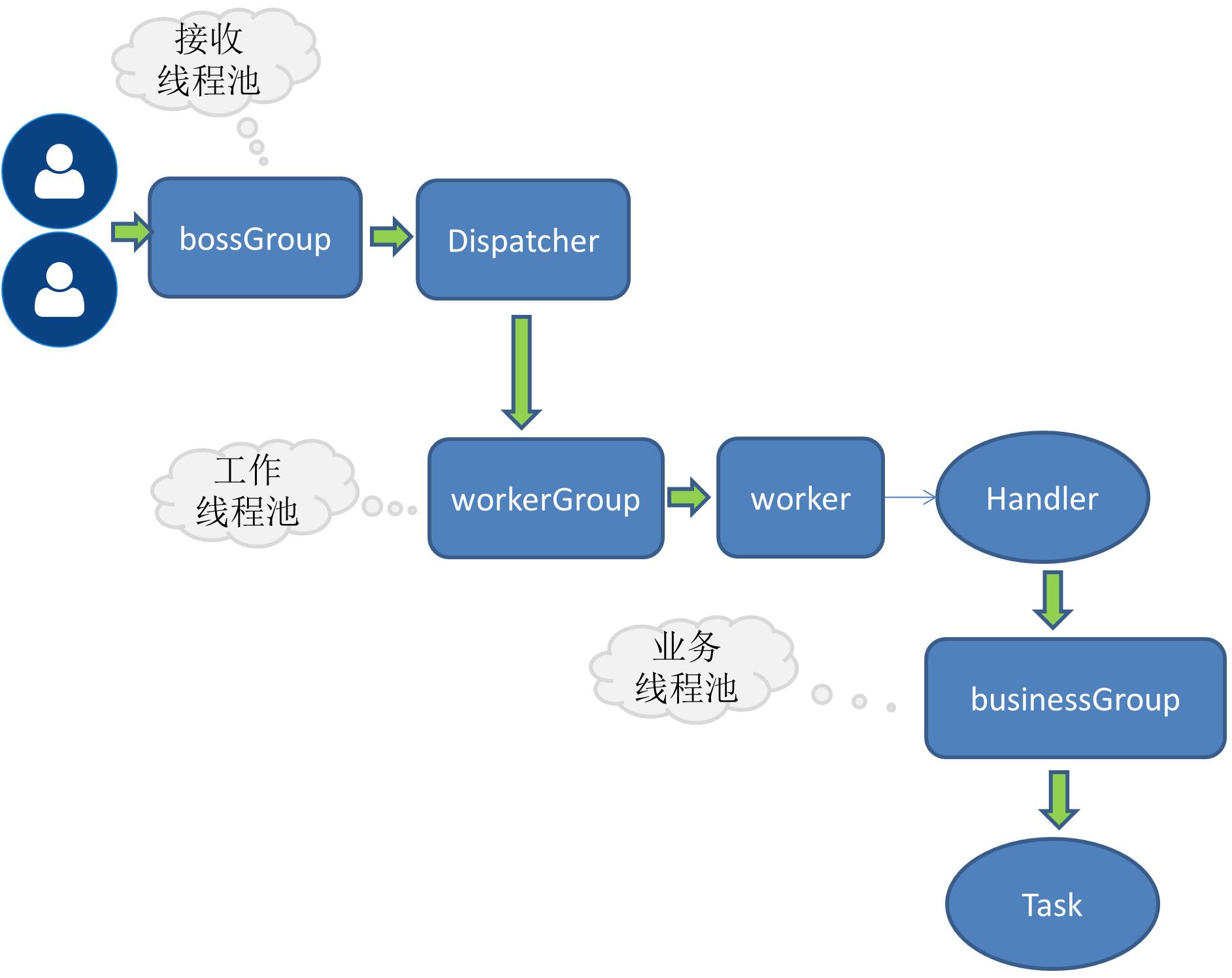
我们从dubbo的源码看下这下线程模型是怎么用的:
netty boss
主要是负责socket连接之类的工作。
netty wokers
将一个请求分给后端的某个handle去处理,比如心跳handle ,执行业务请求的 handle等。
Netty Server中可以看到上述两个线程池是如何初始化的:
首选是open方法,可以看到一个boss一个worker线程池。
protected void doOpen() throws Throwable {
NettyHelper.setNettyLoggerFactory();
ExecutorService boss = Executors.newCachedThreadPool(new NamedThreadFactory("NettyServerBoss", true));
ExecutorService worker = Executors.newCachedThreadPool(new NamedThreadFactory("NettyServerWorker", true));
ChannelFactory channelFactory = new NioServerSocketChannelFactory(boss, worker, getUrl().getPositiveParameter(Constants.IO_THREADS_KEY, Constants.DEFAULT_IO_THREADS));
bootstrap = new ServerBootstrap(channelFactory);
// ......
}
再看ChannelFactory的构造函数:
public NioServerSocketChannelFactory(Executor bossExecutor, Executor workerExecutor, int workerCount) {
this(bossExecutor, 1, workerExecutor, workerCount);
}
可以看出,boss线程池的大小为1,worker线程池的大小也是可以配置的,默认大小是当前系统的核心数+1,也称为IO线程。
busines(业务线程池)
为什么会有业务线程池,这里不多解释,可以参考我上面的文章。
缺省是采用固定大小的线程池,dubbo提供了三种不同类型的线程池供用户选择。我们看看这个类:AllChannelHandler,它是其中一种handle,处理所有请求,它的一个作用就是调用业务线程池去执行业务代码,其中有获取线程池的方法:
private ExecutorService getExecutorService() {
ExecutorService cexecutor = executor;
if (cexecutor == null || cexecutor.isShutdown()) {
cexecutor = SHARED_EXECUTOR;
}
return cexecutor;
}
上面代码中的变量executor来自于AllChannelHandler的父类WrappedChannelHandler,看下它的构造函数:
public WrappedChannelHandler(ChannelHandler handler, URL url) {
//......
executor = (ExecutorService) ExtensionLoader.getExtensionLoader(ThreadPool.class).getAdaptiveExtension().getExecutor(url);
//......
}获取线程池来自于SPI技术,从代码中可以看出线程池的缺省配置就是上面提到的固定大小线程池。
@SPI("fixed")
public interface ThreadPool {
/**
* 线程池
*
* @param url 线程参数
* @return 线程池
*/
@Adaptive({Constants.THREADPOOL_KEY})
Executor getExecutor(URL url);
}最后看下是如何将请求丢给线程池去执行的,在AllChannelHandler中有这样的方法:
public void received(Channel channel, Object message) throws RemotingException {
ExecutorService cexecutor = getExecutorService();
try {
cexecutor.execute(new ChannelEventRunnable(channel, handler, ChannelState.RECEIVED, message));
} catch (Throwable t) {
throw new ExecutionException(message, channel, getClass() + " error when process received event .", t);
}
}典型问题:拒绝服务
如果上面提到的dubbo线程池模型理解了,那么也就容易理解一个问题,当前端大量请求并发出现时,很有可以将业务线程池中的线程消费完,因为默认缺省的线程池是固定大小(我现在版本缺省线程池大小为200),此时会出现服务无法按预期响应的结果,当然由于是固定大小的线程池,当核心线程滿了后也有队列可排,但默认是不排队的,需要排队需要单独配置,我们可以从线程池的具体实现中看:
public class FixedThreadPool implements ThreadPool {
public Executor getExecutor(URL url) {
String name = url.getParameter(Constants.THREAD_NAME_KEY, Constants.DEFAULT_THREAD_NAME);
int threads = url.getParameter(Constants.THREADS_KEY, Constants.DEFAULT_THREADS);
int queues = url.getParameter(Constants.QUEUES_KEY, Constants.DEFAULT_QUEUES);
return new ThreadPoolExecutor(threads, threads, 0, TimeUnit.MILLISECONDS,
queues == 0 ? new SynchronousQueue<Runnable>() :
(queues < 0 ? new LinkedBlockingQueue<Runnable>()
: new LinkedBlockingQueue<Runnable>(queues)),
new NamedThreadFactory(name, true), new AbortPolicyWithReport(name, url));
}
}上面代码的结论是:
- 默认线程池大小为200(不同的dubbo版本可能此值不同)
- 默认线程池不排队,如果需要排队,需要指定队列的大小
当业务线程用完后,服务端会报如下的错误:
Caused by: java.util.concurrent.RejectedExecutionException: Thread pool is EXHAUSTED! Thread Name: DubboServerHandler-192.168.10.222:9999, Pool Size: 1 (active: 1, core: 1, max: 1, largest: 1), Task: 8 (completed: 7), Executor status:(isShutdown:false, isTerminated:false, isTerminating:false), in dubbo://192.168.10.222:9999!
at com.alibaba.dubbo.common.threadpool.support.AbortPolicyWithReport.rejectedExecution(AbortPolicyWithReport.java:53) ~[dubbo-2.5.3.jar:2.5.3]
at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:823) [na:1.8.0_121]
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1369) [na:1.8.0_121]
at com.alibaba.dubbo.remoting.transport.dispatcher.all.AllChannelHandler.caught(AllChannelHandler.java:65) ~[dubbo-2.5.3.jar:2.5.3]
... 17 common frames omitted
通过上面的分析,对调用的服务设置超时时间,是为了避免因为某种原因导致线程被长时间占用,最终出现线程池用完返回拒绝服务的异常。
超时与服务降级
按我们文章之前的场景,web api 请求产品明细时调用product service,为了查询产品评论product service调用comment service。如果此时由于comment service异常,响应时间增大到10S(远大于上游服务设置的超时时间),会发生超时异常,进而导致整个获取产品明细的接口异常,这也就是平常说的强依赖。这类强依赖是超时不能解决的,解决方案一般是两种:
- 调用comment service时做异常捕获,返回空值或者返回具体的错误码,消费端根据不同的错误码做不同的处理。
- 调用coment service做服务降级,比如发生异常时返回一个mock的数据,dubbo默认支持mock。
只有通过做异常捕获或者服务降级才能确保某些不重要的依赖出问题时不影响主服务的稳定性。而超时就可以与服务降级结合起来,当消费端发生超时时自动触发服务降级, 这样即使我们的评论服务一直慢,但不影响获取产品明细的主体功能,只不过会牺牲部分体验,用户看到的评论不是真实的,但评论相对是个边缘功能,相比看不到产品信息要轻的多,某种程度上是可以舍弃的。

