
[翻译]:SQL死锁-为什么会出现死锁
下面这篇对理解死锁非常重要,首先死锁是如何产生的我们要清楚。
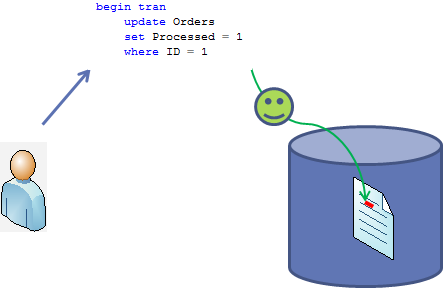
We already know why blocking occurs in the system and how to detect and troubleshoot the blocking issues. Today I’d like us to focus on the deadlocks.First, what is the deadlock? Classic deadlock occurs when 2 processes compete for the resources and waiting on each other. Let’s take a look on that. Click on each picture below to open them in the different window. Let’s assume that Orders table has the clustered index on ID column.Let we have the session 1 that starts transaction and updates the row from the Order table. We already know that Session 1 acquires X lock on this row (ID=1) and hold it till end of transaction
我们已经知道为什么系统中会出现阻塞,也知道如何去探测这些引起阻塞的本质原因。今天我们将重点关注在死锁上。首先,什么是死锁呢?最经典的死锁出现在两个线程为了抢夺同一资源而相互竞争以至于出现你依赖我你依赖我的死循环情况。请看下图的图,我们假定在订单表Id列上有一个聚集索引,会话1开起一个事务去更新订单表的数据。此时会话1会在行数据(ID=1)上申请排它锁至于更新的事务结束。
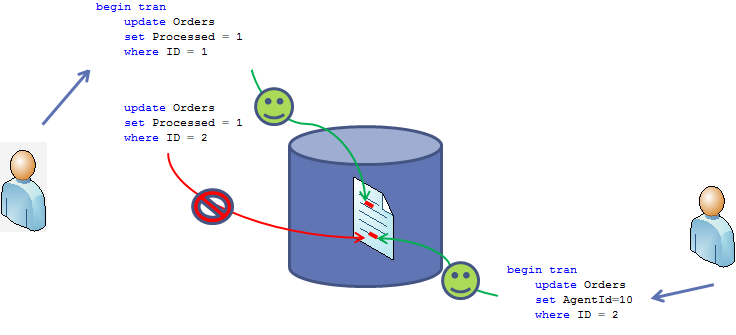
Now let’s start session 2 and have it update another row in the Orders table. Same situation – session acquires and holds X lock on the row with (ID = 2).
现在,我们开启会话2也更新订单表,不同的是更新的数据行为Id=2,同样的在数据行Id=2上也会申请排它锁至到更新事务的结束。

Now if session 1 tries to acquire X lock on the row with ID = 2 , it cannot do that because Session 2 already held X lock there. So, Session 1 is going to be blocked till Session 2 rollback or commit the transaction
现在,如果会话1尝试在数据行Id=2上申请排它锁,将会受到阻塞,因为会话2已经申请了排它锁。只有当会话2回滚或者提交事务后才能够重新尝试获取排它锁。
It worth to mention that it would happen in any transaction isolation level except SNAPSHOT that handles such conditions differently. So read uncommitted does not help with the deadlocks at all.
这里值得提醒的时,上面的场景需要排除镜像这种特殊优化过的隔离模式。所以从上面的例子来看,read uncommitted隔离模式是不能帮忙我们解决死锁问题的。

Simple enough. Unfortunately it rarely happens in the real life. Let’s see it in the small example using the same dbo.Data table like before. Let’s start 2 sessions and update 2 separate rows in the table (acquire X locks).
足够简单,但上面的场景并不常出现。下面我们采用之前使用数据表,我们打开两个会话去更新不同的数据行。
Session 1:
会话1,更新ID=0的数据行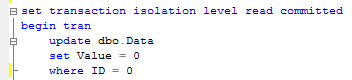
Session 2:
会话2,更新ID为40000的数据行
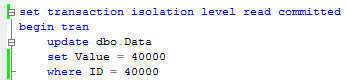
Now let’s run 2 selects.
现在我们再运行两个查询语句
Session 1:
会话1,查询Value=1的数据

Session 2:
会话2,查询Value=40001的数据

Well, as you can see, it introduces deadlock.
如下图所示,我们看到了死锁的相关提示

To understand why it happens, let’s take a look at the execution plan of the select statement:
为了理解到底发生了什么,我们看一相查询所产生的实际执行计划
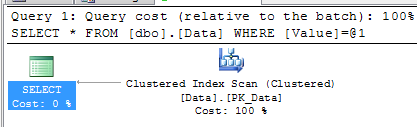
As you can see – there is the table scan. So let’s think what happened
如上图所示,这是一个表扫描,我们来想一下发生了什么:
- First of all, we have 2 X locks on the different rows acquired by both sessions.
首先,我们有两个排它锁在不同的数据行上,每个会话占用一个。
- When session 1 ran select, it introduced table scan. In read committed, repeatable read or serializable isolation levels, readers issue shared S locks, so when session 1 tried to read the row with ID = 40000 (X lock held by session 2) – it was blocked.
当会话1执行查询时,它会引发表扫描,在三种悲观事务隔离级别事务中(除read uncommitted),读会产生共享锁,所有当会话1尝试去读取Id=40000的数据行时就会出现阻塞,因为会话2更新数据行的事务并未结束。
- Same thing happens with session 2 – it’s blocked on the row with ID = 1 (X lock held by session 1).
同样的情况出现在会话2中,当它尝试去读取ID=1的数据行时,此时由于会话1更新的事务并未结束,所以此次查询也会被阻塞。
So this is the classic deadlock even if there are no data updates involved. It worth to mention that read uncommitted transaction isolation level would not introduce deadlock – readers in this isolation level do not acquire S locks. Although you’ll have deadlock in the case if you change select to update even in read uncommitted level. Otimistic isolation levels also behave differently and we will talk about it later.So as you can see, in the real life as other blocking issues deadlocks happen due non-optimized queries.
这是经典的死锁场景即使此时没有任何相关的数据被更新。这里值得再次提醒的是,在read uncommitted事务隔离级别下是不能减少死锁的,尽管在此模式时并不需要申请共享锁。
注:本篇文章中一直来讲read uncommitted模式不能解决死锁,在本篇没有举例子,但之前的系列文章中已经有了,可以详细参考。
Next week we will talk how to detect and deal with deadlocks.
下一次我将讲如何探测死锁以及如何处理死锁问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号