
DAY 1(概念整理)
一.协同过滤
1.简介
利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息,个人通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选信息,回应不一定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。
分为评比(rating)或者群体过滤(social filtering)。
协同过滤推荐(Collaborative Filtering recommendation)是在信息过滤和信息系统中正迅速成为一项很受欢迎的技术。与传统的基于内容过滤直接分析内容进行推荐不同,协同过滤分析用户兴趣,在用户群中找到指定用户的相似(兴趣)用户,综合这些相似用户对某一信息的评价,形成系统对该指定用户对此信息的喜好程度预测。
(2)能够基于一些复杂的,难以表达的概念(信息质量、品位)进行过滤;
二.网络正则化
网络正则是指往对神经网络参数添加正则项,是一种控制过拟合手段,正则项可以看作是对网络参数的约束或惩罚,它能引导网络的参数朝某个规定的方向进行优化。添加了正则项后,网络的优化目标由原来的最小化损失函数𝐿(𝑥)变为最小化损失函数与正则项的和𝐿(𝑥)+𝑅(𝑊)。正则项在优化过程中层的参数或层的激活值添加惩罚项,这些惩罚项将与损失函数一起作为网络的最终优化目标。
常见的正则项有𝐿1范数、𝐿2范数、𝐿1+ 𝐿2约束,𝐿1范数对应于参数的拉普拉斯分布假设,𝐿2约束对应于参数的高斯分布假设
作用:例如,当为网络施加𝐿2约束时,具有较大值的参数经过平方后会产生一个很大的数值,不利于目标函数的最小化。因此在网络优化的过程中,参数将避免出现极大或极小的值。参数的值趋向于正态分布时,接近0值的参数较多,模型的复杂度趋于简单,因此能够达到控制过拟合的目的
过拟合:机器学习的基本问题是利用模型对数据进行拟合,学习的目的并非是对有限训练集进行正确预测,而是对未曾在训练集合中的样本能够正确预测。模型对训练集数据的误差称为经验误差,对测试集数据的误差称为泛化误差。模型对训练集以外样本的预测能力就称为模型的泛化能力,追求这种泛化能力始终是机器学习的目标。
“过拟合”常常在模型学习能力过强的情况出现,此时的模型学习能力太强,以至于将训练集单个样本自身的特点都能捕捉到,并将其认为是“一般规律”,同样这种情况也会导致模型泛化能力下降
欠拟合:欠拟合”常常在模型学习能力较弱,而数据复杂度较高的情况出现,此时模型由于学习能力不足,无法学习到数据集中的“一般规律”,因而导致泛化能力弱
区别:欠拟合在训练集和测试集上的性能都较差,而过拟合往往能学习训练集数据的性质,而在测试集上的性能较差
解决方案:
 数或代价函数后面加上一个正则项,一般有L1正则与L2正则等。
数或代价函数后面加上一个正则项,一般有L1正则与L2正则等。 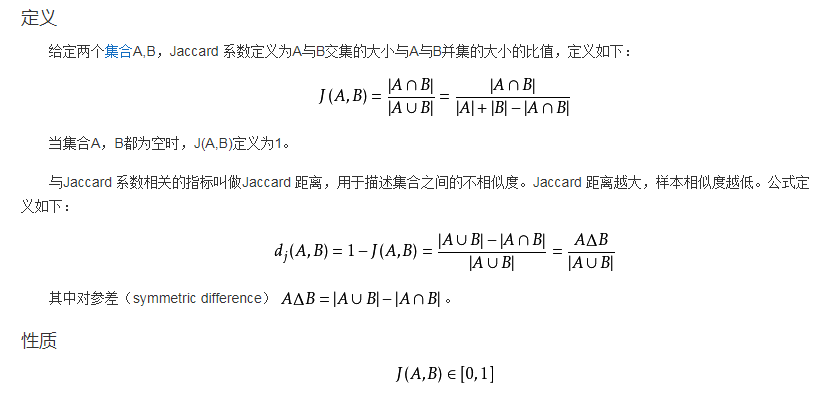
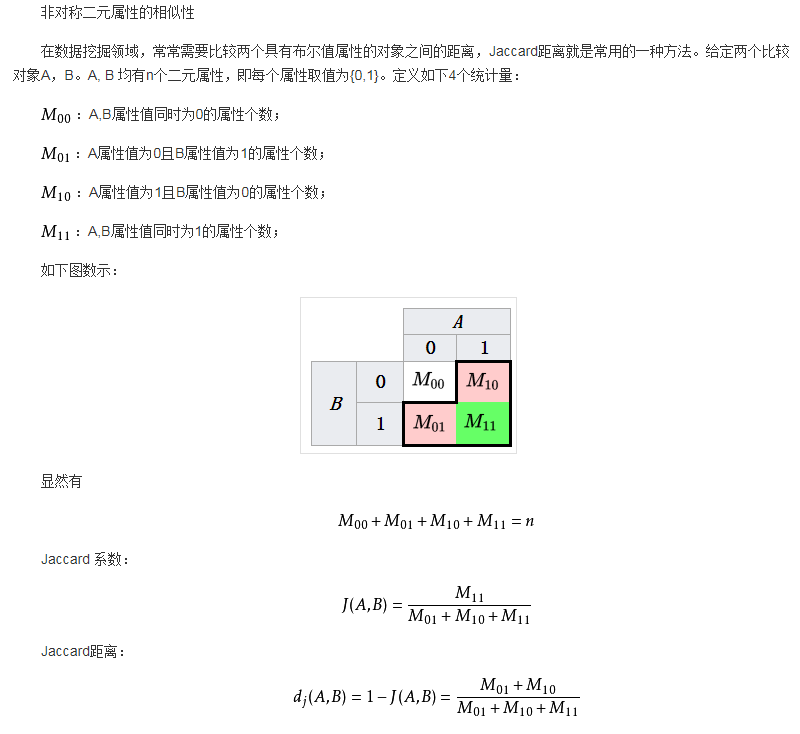
应用:项目相似性度量是协同过滤系统的核心。 相关研究中,基于物品协同过滤系统的相似性度量方法普遍使用余弦相似性。 然而,在许多实际应用中,评价数据稀疏度过高,物品之间通过余弦相似度计算会产生误导性结果。 将杰卡德相似性度量应用到基于物品的协同过滤系统中,并建立起相应的评价分析方法。
非局域性:以BP神经网络为例,BP要达到在全局范围内找到能使误差最小的权值,这就是非局域性。
非定常性:定常就是一个系统的结构参数是固定的常数,而神经网络是可以通过训练修改权值的,当然具有非定常性。
非凸性:非凸性是指系统的能量函数有多个极值,即系统有多个稳定的平衡态。
