


@@@直播课
@
jupyter notebook
@解决matplotlib中文显示方框问题
1.打开matplotlib字体list路径,默认为C:\Users\你的用户名\.matplotlib,打开fontList.json,查找是否包含simHei字体。
2.找文件路径:
import matplotlib print(matplotlib.matplotlib_fname())
3.用文本编辑器打开matplotlibrc配置文件,查找#font.family:和#font.sans-serif:开头的这两行。
去掉这两行的注释,并在font.sans-serif:后添加SimHei
@初试numpy和pandas查看CSV文件
import numpy as np import pandas as pd data_path=r'C:\Users\sunlu\Desktop\地市级党委书记数据库(2000-10).csv' f=open(data_path) data=pd.read_csv(f)#如果直接读,可能因为文件名称为中文而报错 print(data.head(10))#前10行 print('==================') print(data[4:10])#第5行到第10行 print('==================') print(data[['年份','教育']]) print('==================') field=data.columns.tolist() print(field) print('==================') print(data.describe(include=[np.object]))#加include=[np.object]参数可使统计包含字符串 print('==================')
分析性别
data_gender=data['性别'] # print(data_gender) data_gender_re=data_gender[data_gender.notnull()]#忽略缺失值 print(data_gender_re) print('======') print(data_gender_re.describe()) print('======') print(len(data_gender))#describe会自动忽略缺失值 print('======') print(data_gender_re.head())#前五个 count_m=len(data_gender_re[data_gender_re=="男"]) print(count_m) print('======') data_gender2 = data[['省级政区名称','性别']] data_gender2_re = data_gender2[data_gender2['性别'].notnull()] print(data_gender2_re.head()) print('----------') pt = pd.crosstab(data_gender2_re['省级政区名称'], data_gender2_re['性别']) print(pt.head()) print('----------')
# 新建变量data_gender2,字段包括省份、性别
# 去除缺失值
pt = pd.crosstab(data_gender2_re['省级政区名称'], data_gender2_re['性别'])
print(pt.head())
print('----------')
# 按照省份统计出男女人数
# crosstab(行,列)用于针对字符串数据的透视(类似excel的数据透视)
pt['女性占比'] = pt['女'] / (pt['女'] + pt['男'])
pt2 = pt.sort_values(by = ['女性占比'], ascending = False)
print(pt2.head(10))
print('----------')
# 计算出女性占比
# 这里直接在pt数据中添加了一个新的字段“女性占比”
# sort_values()排序,ascending = False表示降序
性别构成分析
# 绘制图表1:不同省份女性市委书记占比 fig_q1_1 = plt.figure(figsize = (8,4)) # 创建一个图表,大小为8*4 index = pt2.index[:10] plt.bar(range(10), # 横坐标 pt2['女性占比'][:10], # 纵坐标 tick_label=index, # 横轴标签 color = 'gray' ) # 颜色 plt.title('不同省份女性市委书记占比') plt.xlabel('省份') plt.ylabel('女性占比') plt.show()
#python重点在数据分析,分析出数据后再用excel等进行可视化,包括python的matplotlib包,链接为:
https://matplotlib.org/gallery/index.html
箱图
# 绘制图表2:女性市委书记占比结构 fig_q1_2 = plt.figure(figsize = (4,4)) # 创建一个图表,大小为4*4 plt.boxplot(pt2['女性占比'], # 值 vert=True, # true:纵向,false:横向 showmeans = True) # 显示均值 plt.title('女性市委书记占比结构') plt.xticks([]) plt.ylabel('女性占比') plt.show() # 创建箱形图:四分位数,上下边缘值(非最大最小值),异常值 # 参数添加 # plt.show():显示图表
年龄情况
data_age = data[['出生年份','党委书记姓名','年份']] data_age_re = data_age[data_age['出生年份'].notnull()] print(data_age_re.head())
df1 = 2017 - data_age_re['出生年份'] print(df1.head()) print('======') # 计算出整体年份数据 df_yearmin = data_age_re[['党委书记姓名','年份']].groupby(data_age_re['党委书记姓名']).min() #一个人好几个年份,要找上任的年份,所以用min() print(df_yearmin.head(5)) print(data_age_re[['党委书记姓名','年份']].groupby(data_age_re['党委书记姓名']).max().head()) print('----------') df2 = df_yearmin['年份'].groupby(df_yearmin['年份']).count() print(df2) print('======') # 计算出入职年份数据 df_yearmax = data_age_re[['党委书记姓名','年份']].groupby(data_age_re['党委书记姓名']).max() df3 = df_yearmax['年份'].groupby(df_yearmax['年份']).count() print(df3) print('----------') # 计算出卸任年份数据
# 专业情况:专业结构 / 专业整体情况 / 专业大类分布
data_major = data[['党委书记姓名','年份','专业:人文','专业:社科','专业:理工','专业:农科','专业:医科']] data_major_re = data_major[data_major['专业:人文'].notnull()] print(data_major_re.head()) print(data_major_re.describe()) print('----------') # 新建变量data_major,赋值包括年份、专业等字段内容,其中1代表是,0代表否 # 清除缺失值 data_major_re['专业'] = data_major_re[['专业:人文', '专业:社科', '专业:理工', '专业:农科', '专业:医科']].idxmax(axis=1) print(data_major_re.head()) print('----------') # 统计每个人的专业,idxmax(axis=1)表示找到每行的值为1时的单元格所在列的名称 data_major_st = data_major_re[['专业','党委书记姓名']].drop_duplicates() print(data_major_st.head()) print('----------') # 去重 df4 = data_major_st['专业'].groupby(data_major_st['专业']).count() print(df4) print('----------') # 计算出学历结构数据 df5 = pd.crosstab(data_major_re['年份'], data_major_re['专业']) print(df5) print('----------') # 计算每年专业整体情况数据 df5['社科比例'] = df5['专业:社科'] / (df5['专业:理工'] + df5['专业:医科'] + df5['专业:社科'] + df5['专业:农科'] + df5['专业:人文']) df5['人文比例'] = df5['专业:人文'] / (df5['专业:理工'] + df5['专业:医科'] + df5['专业:社科'] + df5['专业:农科'] + df5['专业:人文']) df5['理工农医比例'] = (df5['专业:理工'] + df5['专业:医科'] + df5['专业:农科'])/ (df5['专业:理工'] + df5['专业:医科'] + df5['专业:社科'] + df5['专业:农科'] + df5['专业:人文']) print(df5[['社科比例','人文比例','理工农医比例']]) print('----------') # 计算每年专业大类分布数据
# 专业情况:专业结构 / 专业整体情况 / 专业大类分布
data_path=r'C:\Users\sunlu\Desktop\地市级党委书记数据库(2000-10).csv' f=open(data_path) data=pd.read_csv(f)#如果直接读,可能因为文件名称为中文而报错 data_major_re['专业'] = data_major_re[['专业:人文', '专业:社科', '专业:理工', '专业:农科', '专业:医科']].idxmax(axis=1) #idxmax(axis=1) print(data_major_re.head()) print('----------') # 统计每个人的专业 data_major_st = data_major_re[['专业','党委书记姓名']].drop_duplicates() print(data_major_st.head()) print('----------') # 去重 df4 = data_major_st['专业'].groupby(data_major_st['专业']).count() print(df4) print('----------') # 计算出学历结构数据 df5 = pd.crosstab(data_major_re['年份'], data_major_re['专业']) print(df5) print('----------') # 计算每年专业整体情况数据 df5['社科比例'] = df5['专业:社科'] / (df5['专业:理工'] + df5['专业:医科'] + df5['专业:社科'] + df5['专业:农科'] + df5['专业:人文']) df5['人文比例'] = df5['专业:人文'] / (df5['专业:理工'] + df5['专业:医科'] + df5['专业:社科'] + df5['专业:农科'] + df5['专业:人文']) df5['理工农医比例'] = (df5['专业:理工'] + df5['专业:医科'] + df5['专业:农科'])/ (df5['专业:理工'] + df5['专业:医科'] + df5['专业:社科'] + df5['专业:农科'] + df5['专业:人文']) print(df5[['社科比例','人文比例','理工农医比例']]) print('----------') # 计算每年专业大类分布数据
@@@以下是云课堂之前教学
@数据分析的成长经验。
@数据工作范围
@以前测算人数:统计局静态数据
现在测算人数:手机位置定位动态可视化
@三个案例(腾讯离职员工去向,婚恋匹配,财富分配模型)
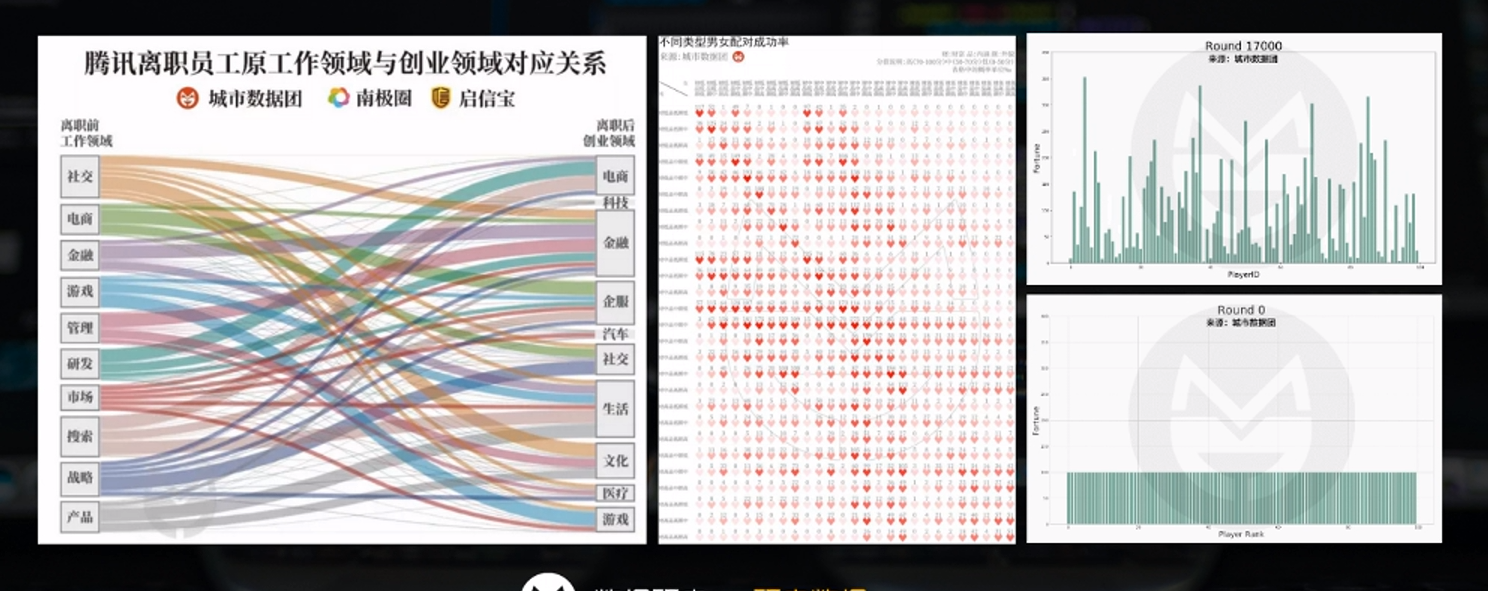
@数据分析门槛相对低,可以在后续进行方向延展。
@英文报错要看懂;先选行业再选企业性质;金融领域需要学算法;
@《python科学数据手册》
@数据分析基本框架
分类:描述性分析;规范性分析(A/Btesting);预测性分析
步骤:
1.构建问题

2.解决问题

3.传达结果并采取行动

@场景:
1.犯罪现场分析——《分析复购率不足的原因》
2.疯狂科学家——《流失用户召回A/Btesting》
3.预测故事——《大促GMV预测》
@模型:
LR
GDBT
@评估指标:
ROC
reach/ctr
@电商用户基础分析RFM
@电商分析框架

@
