一、编码
ascii:
A:00000010 8位 一个字节
unicode:
A:00000000 00000001 00000010 00000100 32位 四个字节
中:00000000 00000001 00000010 00000100 32位 四个字节
utf-8:
A:00000110 8位 一个字节
中:00000010 00000110 16位 两个字节
gbk:
A:00000110 8位 一个字节
中:00000010 00000110 16位 两个字节
1,各个编码之间的二进制,是不能互相识别的,会产生乱码。
2,文件的存储,传输,不能是unicode (只能是utf-8 utf-16 gbk gbk2312 ascii等)
py3:
str 在内存中是Unicode编码。
bytes类型
对于英文:
str:表现形式:s = 'alex'
编码方式:010101010 unicode
bytes:表现形式:s = b'alex'
编码方式:000101010 utf-8 gbk。。。。
对于中文:
str:表现形式:s = '中国'
编码方式:010101010 unicode
bytes: 表现形式:s = b' x\e91\e91\e01\e21\e31\e32'
编码方式:000101010 utf-8 gbk。。。。
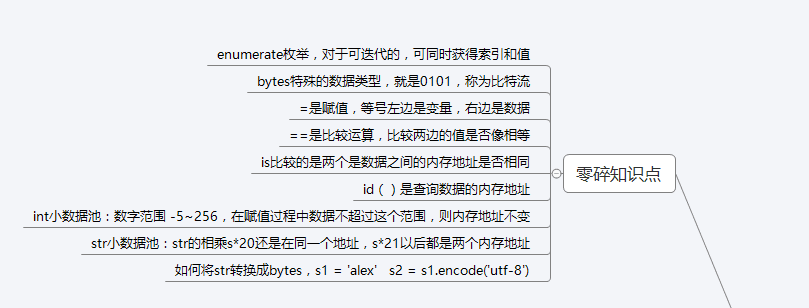
encode 编码,如何将 str ——> bytes
使用方法: str.encode('utf-8')
decode 解码,如何将 bytes——> str
使用方法: bytes.decode('utf-8')
posted @
2017-12-21 18:52
带带大师兄丶
阅读(
649)
评论()
收藏
举报
欢迎第

个访客


 浙公网安备 33010602011771号
浙公网安备 33010602011771号