【Python之路】第四篇--Python基础之函数
三元运算
三元运算(三目运算),是对简单的条件语句的缩写
# 书写格式
result = 值1 if 条件 else 值2
# 如果条件成立,那么将 “值1” 赋值给result变量,否则,将“值2”赋值给result变量
基本数据类型补充
set
set集合,是一个无序且不重复的元素集合,它的主要作用如下:
-
去重,把一个列表变成集合,就自动去重了
-
关系测试,测试两组数据之前的交集、差集、并集等关系
集合对象是一组无序排列的可哈希的值:集合成员可以做字典的键
集合分类:可变集合、不可变集合
可变集合(set):可添加和删除元素,非可哈希的,不能用作字典的键,也不能做其他集合的元素
不可变集合(frozenset):与上面恰恰相反


class set(object): """ set() -> new empty set object set(iterable) -> new set object Build an unordered collection of unique elements. """ def add(self, *args, **kwargs): # real signature unknown """ Add an element to a set,添加元素 This has no effect if the element is already present. """ pass def clear(self, *args, **kwargs): # real signature unknown """ Remove all elements from this set. 清除内容""" pass def copy(self, *args, **kwargs): # real signature unknown """ Return a shallow copy of a set. 浅拷贝 """ pass def difference(self, *args, **kwargs): # real signature unknown """ Return the difference of two or more sets as a new set. A中存在,B中不存在 ( in A not in B ) (i.e. all elements that are in this set but not the others.) """ pass def difference_update(self, *args, **kwargs): # real signature unknown """ Remove all elements of another set from this set. 从当前集合中删除和B中相同的元素""" pass def discard(self, *args, **kwargs): # real signature unknown """ Remove an element from a set if it is a member. If the element is not a member, do nothing. 移除指定元素,不存在不保错 """ pass def intersection(self, *args, **kwargs): # real signature unknown """ Return the intersection of two sets as a new set. 交集 (i.e. all elements that are in both sets.) """ pass def intersection_update(self, *args, **kwargs): # real signature unknown """ Update a set with the intersection of itself and another. 取交集并更更新到A中 """ pass def isdisjoint(self, *args, **kwargs): # real signature unknown """ Return True if two sets have a null intersection. 如果没有交集,返回True,否则返回False""" pass def issubset(self, *args, **kwargs): # real signature unknown """ Report whether another set contains this set. 是否是子序列""" pass def issuperset(self, *args, **kwargs): # real signature unknown """ Report whether this set contains another set. 是否是父序列""" pass def pop(self, *args, **kwargs): # real signature unknown """ Remove and return an arbitrary set element. Raises KeyError if the set is empty. 移除元素 """ pass def remove(self, *args, **kwargs): # real signature unknown """ Remove an element from a set; it must be a member. If the element is not a member, raise a KeyError. 移除指定元素,不存在保错 """ pass def symmetric_difference(self, *args, **kwargs): # real signature unknown """ Return the symmetric difference of two sets as a new set. 对称差集 (not in a and b ) (i.e. all elements that are in exactly one of the sets.) """ pass def symmetric_difference_update(self, *args, **kwargs): # real signature unknown """ Update a set with the symmetric difference of itself and another. 对称差集,并更新到a中 """ pass def union(self, *args, **kwargs): # real signature unknown """ Return the union of sets as a new set. 并集 (i.e. all elements that are in either set.) """ pass def update(self, *args, **kwargs): # real signature unknown """ Update a set with the union of itself and others. 更新 """ pass
练习:寻找差异
old_dict = {
"#1":11,
"#2":22,
"#3":100,
}
new_dict = {
"#1":33,
"#4":22,
"#7":100,
}
old_set = set(old_dict.keys())
new_set = set(new_dict.keys())
same_set = old_set.intersection(new_set)
up_set = new_set.difference(old_set)
ret_dict = {}
for k in same_set:
ret_dict[k]=new_dict[k]
for i in up_set:
ret_dict[i]=new_dict[i]
print(ret_dict)
# print(old_set)
# print(new_set)
深浅拷贝
一、数字和字符串
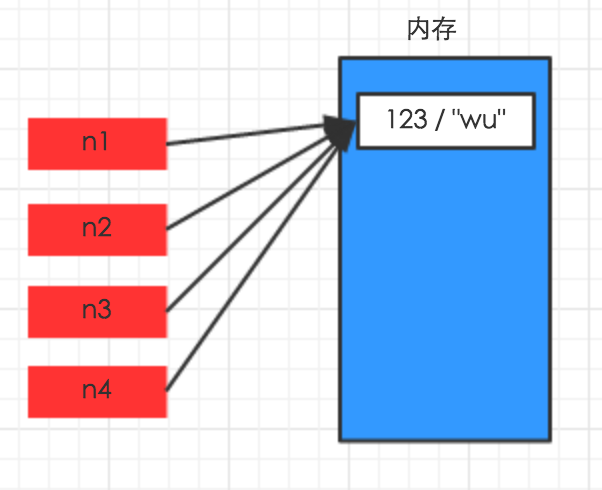
对于 数字 和 字符串 而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址。
import copy a = 132 b = 'Ales' # ## 浅拷贝 ## aa = copy.copy(a) bb = copy.copy(b) # ## 深拷贝 ## aaa = copy.deepcopy(a) bbb = copy.deepcopy(b) print(id(a),id(aa),id(aaa)) print(id(b),id(bb),id(bbb)) # ## 1691783456 1691783456 1691783456 # ## 47227376 47227376 47227376
二、其他基本数据类型
对于字典、元祖、列表 而言,进行赋值、浅拷贝和深拷贝时,其内存地址的变化是不同的。
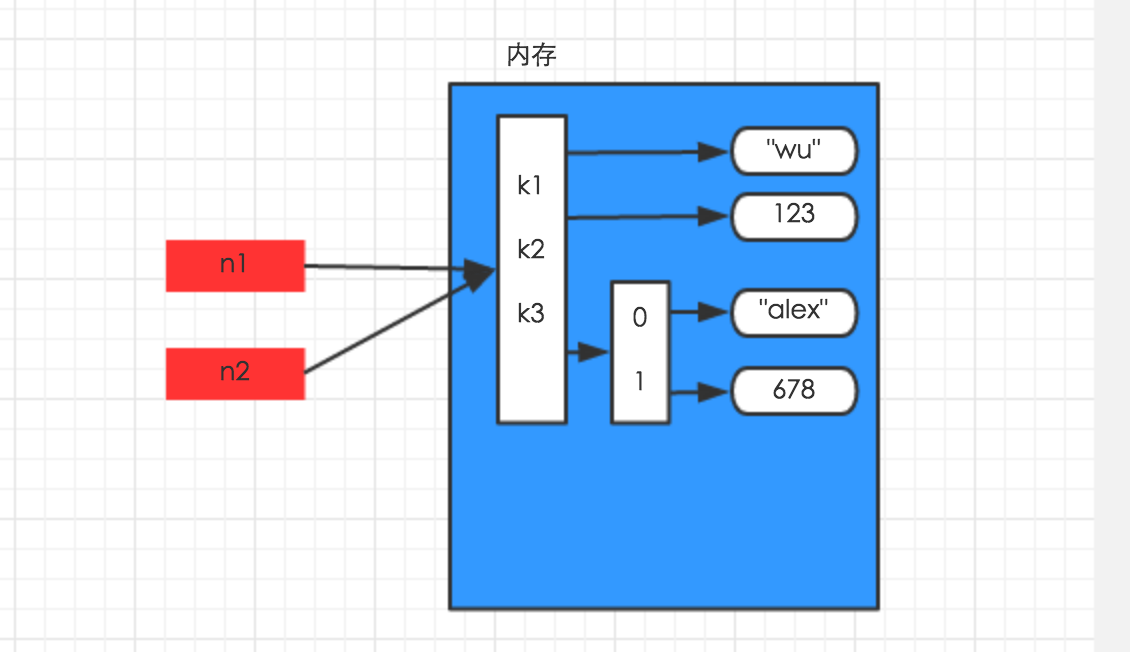
1、赋值
赋值,只是创建一个变量,该变量指向原来内存地址,如:
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
n2 = n1
2、浅拷贝
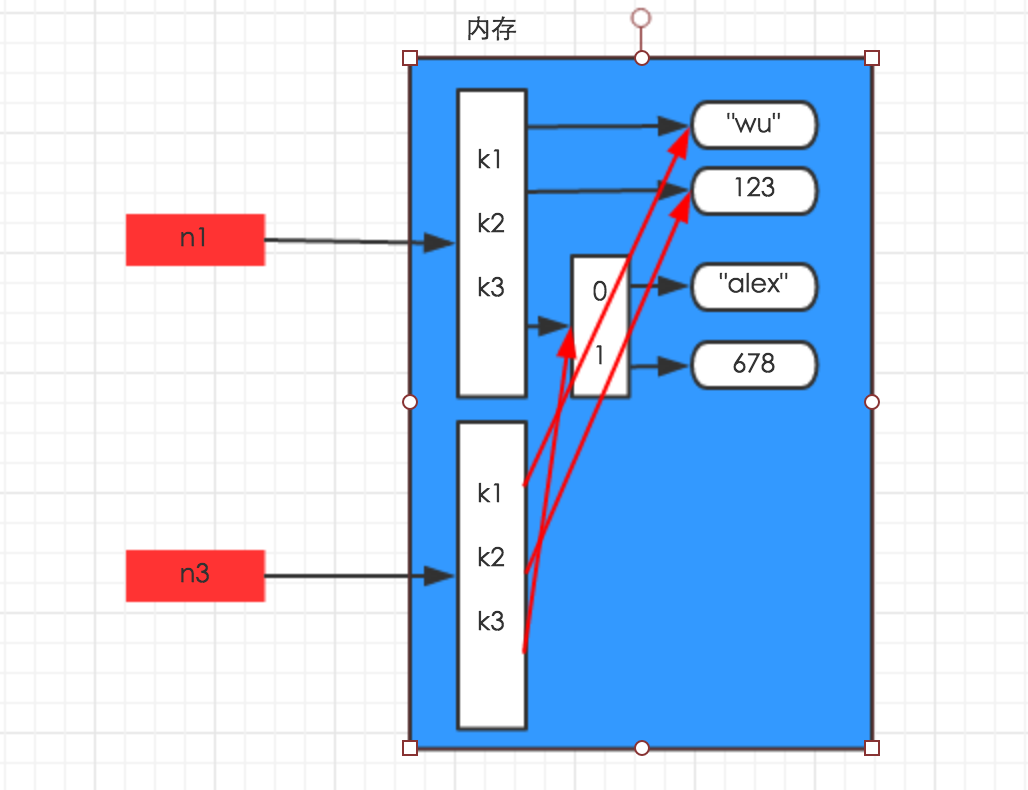
浅拷贝,在内存中只额外创建第一层数据
import copy
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
n3 = copy.copy(n1)
print(id(n1),id(n3))
print(id(n1["k1"]),id(n3["k1"]))
# 44947080 45383304
# 45327056 45327056
3、深拷贝
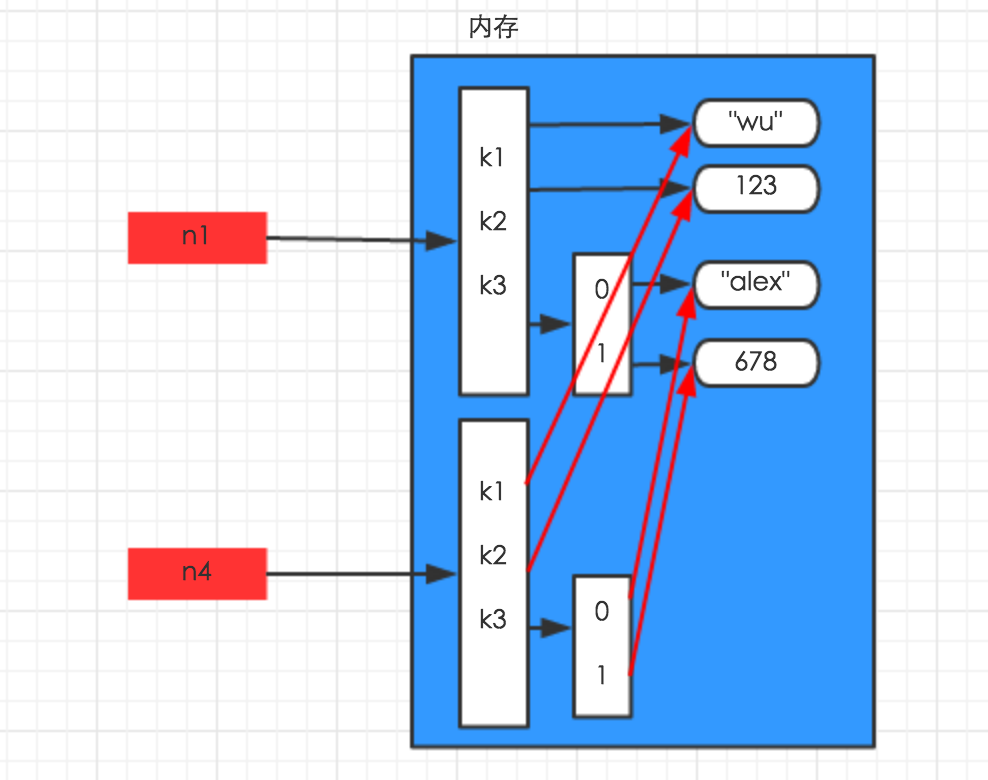
深拷贝,在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化)
import copy
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
n4 = copy.deepcopy(n1)
print(id(n1),id(n4))
print(id(n1["k3"]),id(n4["k3"]))
print(id(n1["k3"][0]),id(n4["k3"][0]))
# 56088200 56460680
# 58962760 58930696
# 56506216 56506216
函数
一、背景
在学习函数之前,一直遵循:面向过程编程,
即:根据业务逻辑从上到下实现功能,其往往用一长段代码来实现指定功能,开发过程中最常见的操作就是粘贴复制,也就是将之前实现的代码块复制到现需功能处,如下:
while True:
if cpu利用率 > 90%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
if 硬盘使用空间 > 90%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
if 内存占用 > 80%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
腚眼一看上述代码,if条件语句下的内容可以被提取出来公用,如下:
def 发送邮件(内容)
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
while True:
if cpu利用率 > 90%:
发送邮件('CPU报警')
if 硬盘使用空间 > 90%:
发送邮件('硬盘报警')
if 内存占用 > 80%:
对于上述的两种实现方式,第二次必然比第一次的重用性和可读性要好,其实这就是函数式编程和面向过程编程的区别:
-
函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可
-
面向对象:对函数进行分类和封装,让开发“更快更好更强...”
简单的例子:求一个长方形的周长和面积。
面向过程的程序设计方式:
1、确定长方形周长和面积的算法。
2、编写两个方法(函数)分别计算长方形的周长和面积。
3、求周长的方法(函数)和求面积的方法(函数)需要两个参数,分别是长方形的长和宽。
面向对象的程序设计方式:
1、一个长方形可以看成一个长方形对象。
2、一个长方形对象有两个状态(长和宽)和两个行为(求周长和求面积)。
3、将所有长方形的共性抽取出来,设计一个长方形类。
4、通过长方形对象的行为,就可以求出某个具体的长方形对象的周长和面积。
二、函数定义和使用
def 函数名(参数):
...
函数体
...
返回值
函数的定义主要有如下要点:
- def:表示函数的关键字
- 函数名:函数的名称,日后根据函数名调用函数
- 函数体:函数中进行一系列的逻辑计算,如:发送邮件、计算出 [11,22,38,888,2]中的最大数等...
- 参数:为函数体提供数据
- 返回值:当函数执行完毕后,可以给调用者返回数据。
1、返回值
函数是一个功能块,该功能到底执行成功与否,需要通过返回值来告知调用者。
返回多个对象时,封装成一个元组返回!
以上要点中,比较重要有参数和返回值:
def 发送短信():
发送短信的代码...
if 发送成功:
return True
else:
return False
while True:
# 每次执行发送短信函数,都会将返回值自动赋值给result
# 之后,可以根据result来写日志,或重发等操作
result = 发送短信()
if result == False:
记录日志,短信发送失败...
2、参数
函数有三种不同的参数:
- 普通参数
- 默认参数
- 动态参数
# ######### 定义函数 ######### # name 叫做函数func的形式参数,简称:形参 def func(name): print name # ######### 执行函数 ######### # 'alex' 叫做函数func的实际参数,简称:实参 func('alex')
def func(name, age = 18): print "%s:%s" %(name,age) # 指定参数 func('wupeiqi', 19) # 使用默认参数 func('alex') 注:默认参数需要放在参数列表最后
def func(*args): print(args,type(args)) # 执行方式一 func(11,33,4,4454,5,['11','22']) # (11, 33, 4, 4454, 5, ['11', '22']) <class 'tuple'> # 执行方式二 li = [11,2,2,3,3,4,54] func(li) # ([11, 2, 2, 3, 3, 4, 54],) <class 'tuple'> 注意此处!元组第一个元素为列表 func(*li) # (11, 2, 2, 3, 3, 4, 54) <class 'tuple'>
def func(**kwargs): print(kwargs) # 执行方式一 func(name='wupeiqi',age=18) # 执行方式二 li = {'name':'wupeiqi', 'age':18, 'gender':'male'} func(**li) # {'name': 'wupeiqi', 'age': 18} # {'name': 'wupeiqi', 'age': 18, 'gender': 'male'}
def f1(*a,**aa): print(a,type(a)) print(aa,type(aa)) f1(11,22,33,k1=123,k2=456) # (11, 22, 33) <class 'tuple'> # {'k1': 123, 'k2': 456} <class 'dict'>
3.函数名可以做参数传递
函数名() => 执行函数
函数名 => 代指函数内容
def f1():
print("F1")
return "F1"
def f2(arg):
arg()
print("F2")
return "F2"
f2(f1)
# F1
# F2
函数式编程、面向过程编程、面向对象编程
函数式编程 :主要思想是把运算过程尽量写成一系列嵌套的函数调用。增强代码的重用性和可读性
传统的编程模式:
var a = 1 + 2;
var b = a * 3;
var c = b - 4;
函数式编程要求使用函数,我们可以把运算过程定义为不同的函数,然后写成下面这样:
var result = subtract(multiply(add(1,2), 3), 4);
函数式编程具有五个鲜明的特点。
(1)函数是"第一等公民",与其他数据类型一样,处于平等地位,可以赋值给其他变量,也可以作为参数,传入另一个函数,或者作为别的函数的返回值。
(2)申明式(Declarative)的编程方式,相对于命令式而言,命令式程序设计大量使用可变对象和指令。习惯于创建对象或者变量,并且修改它们的状态或者值,或者喜欢提供一系列指令,要求程序执行。
对于申明式编程范式,不需要提供明确的指令操作,所有的细节指令将会更好的被程序库所封装,只需要提出要求,申明用意即可。
(3)无"副作用"(side effect),指的是函数内部与外部互动(最典型的情况,就是修改全局变量的值),产生运算以外的其他结果。
显式函数指函数与外界交换数据的唯一渠道就是参数和返回值,显式函数不会去读取或者修改函数的外部状态,
隐式函数除了参数和返回值外,还会读取外部信息,或者可能修改外部信息。
(4)不修改状态,函数式编程只是返回新的值,不修改系统变量。因此,不修改变量,也是它的一个重要特点。
在其他类型的语言中,变量往往用来保存"状态"(state)。不修改变量,意味着状态不能保存在变量中。函数式编程使用参数保存状态,最好的例子就是递归。
(5)尾递归优化,尾递归操作处于函数的最后一步。这种情况下,函数的工作其实已经完成(剩余工作就是再次调用它自身)。
编译器可以进行优化,用新函数的帧栈覆盖掉老函数的帧栈,避免递归操作不断申请栈空间。
函数式编程好处:
(1)代码简洁,开发快速。函数式编程大量使用函数,减少了代码的重复,因此程序比较短,开发速度较快。
(2)接近自然语言,易于理解。
(3)易于并发编程(concurrency)。函数式编程不需要考虑"死锁"(deadlock),因为它不修改变量,所以根本不存在"锁"线程的问题。不必担心一个线程的数据,被另一个线程修改,所以可以很放心地把工作分摊到多个线程,部署"并发编程"。
面向过程是一种以事件为中心的编程思想,以功能(行为)为导向,面向过程类型的编码是需求的直译过程。按模块化的设计,就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,实现的时候一个一个依次调用。
面向对象是一种以事物为中心的编程思想,以数据(属性)为导向,将具有相同一个或者多个属性的物体抽象为“类”,将他们包装起来;而有了这些数据(属性)之后,我们再考虑他们的行为(对这些属性进行怎样的操作),是把构成问题的事物分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描述某个事物在整个解决问题的步骤中的行为。
内置函数

注:查看详细猛击这里
open()函数 => 详情点击
lambda表达式
学习条件运算时,对于简单的 if else 语句,可以使用三元运算来表示,即:
# 普通条件语句
if 1 == 1:
name = 'eric'
else:
name = 'alex'
# 三元运算
name = 'eric' if 1 == 1 else 'alex'
对于简单的函数,也存在一种简便的表示方式,即:lambda表达式
func = lambda x,y : x+1
- 参数 x,y
- 函数体
- 隐含 return
- func 函数名
# ###################### 普通函数 ######################
def f1(x):
return x+100
result = f1(10)
print(result)
# ###################### lambda ######################
my_lambda = lambda x : x+100
result = my_lambda(10)
print(result)
注意 :
def makelist(): L = [] for i in range(5): L.append(lambda x: i**x) return L mylist = makelist() >>> mylist[0](0) 1 >>> mylist[0](1) 4 >>> mylist[0](2) 16
i 为enclosing variables,直到lambda函数调用时,i 的最终值为4
具体参考python作用域
for 循环中的 lambda 表达式
第一种:
f = [ lambda x: x*i for i in range(4) ]
调用结果为:
>>> f = [lambda x:x*i for i in range(4)] >>> f[0](1) 3 # 1*3 >>> f[1](1) 3 # 1*3 >>> f[2](1) 3 # 1*3 >>> f[0](3) 9 # 3*3 >>> f[1](3) 9 # 3*3 >>> f[2](3) 9 # 3*3
表达式展开为函数代码:
def func(): fs = [] for i in range(4): def lam(x): return x*i fs.append(lam) return fs >>> f = func() >>> f[0](3) 9 >>> f[2](3) 9 >>> f[1](3) 9
当调用func()时,每次循环都将lam()函数的地址放入到fs列表中。
循环中的lam()函数,都未绑定i的值,直到循环结束,i的值为3,并将lam()函数中所用到的 i 值定为3。
到调用时,i 的值 一直保持为3。
另一种:
f = [ lambda :i*i for i in range(4) ] (没有传入x值)
>>> f = [lambda :i*i for i in range(4)] >>> f[0]() 9 >>> f[1]() 9 >>> f[2]() 9 >>> f[3]() 9
第二种:
f = [ lambda i=i: i*i for i in range(4) ]
表达式调用结果为:
>>> f1 = [lambda i=i: i*i for i in range(4)] >>> f1[0]() 0 >>> f1[1]() 1 >>> f1[2]() 4 >>> f1[3]() 9
展开为函数为:
def func(): fs = [] for i in range(4) def lam(x=i): # 即 i=i return x*x # 即 i*i fs.append(lam) return fs
当调用func()函数时,每次循环都将lam()函数的地址放入到fs列表中。
但是在每次循环中,都将 i 的值绑定到了 x 上,所以直到循环结束,每次的 x 的值都不一样。
到调用时,x 的值为当时绑定的值。
当有给 lam()函数 进行参数传递时,参数就绑定到 x 的值上。
>>> f1 = [lambda i=i: i*i for i in range(4)] >>> f1[0](8) 64 >>> f1[1](8) 64 >>> f1[2](8) 64 >>> f1[3](8) 64
第三种:
f = [ lambda x=i:i*i for i in range(4) ]
表达式调用结果为:
>>> f2 = [lambda x=i: i*i for i in range(4)] >>> f2[0]() 9 >>> f2[1]() 9 >>> f2[2]() 9 >>> f2[0](1) 9 >>> f2[1](2) 9
传不传参数都不影响结果。展开后:
def func(): fs = [] for i in range(4) def lam(x=i): return i*i fs.append(lam) return fs
虽然 lam()函数 将 i 的值绑定到 x上,但是函数体中并没有使用到 x 的值,
直到循环结束,i 的值变为3,才会在调用时使用。
递归
利用函数编写如下数列:
斐波那契数列指的是这样一个数列 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233,377,610,987,1597,2584,4181,6765,10946,17711,28657,46368...
斐波纳契数列以如下被以递归的方法定义:F(0)=0,F(1)=1,F(2)=1, F(n)=F(n-1)+F(n-2)(n>=2,n∈N*)
def f1(a1,a2):
if a1 == 0:
print(a1,a2)
a3 = a1 + a2
print(a3)
f1(a2,a3)
f1(0,1)
第一种(递归法):
写法最简洁,但是效率最低,会出现大量的重复计算,时间复杂度O(1.618^n),而且最深度1000
def fi(n): if n <= 1: return n return fi(n-2) + fi(n-1) for i in range(6): print(fi(i),end=' ')
第二种(递推法):
递推法,就是递增法,时间复杂度是 O(n),呈线性增长,如果数据量巨大,速度会越拖越慢
def fi(n): if n <= 1: return n a, b = 0, 1 for i in range(n-1): a, b = b, a + b return b
第三种(生成器):
def fi(n): a, b = 0, 1 while n >= 1 : a, b = b, a+b yield a n -= 1 for i in fi(6): print(i, end=' ')
第四种(类):
class Fabinacci(object): def __init__(self, count): self.current = 0 self.a = 0 self.b = 1 self.max = count def __next__(self): if self.current < self.max: self.a,self.b = self.b, self.a + self.b self.current += 1 return self.a else: raise StopIteration def __iter__(self): return self for i in Fabinacci(6): print(i, end=' ')
第五种(矩阵):
因为幂运算可以使用二分加速,所以矩阵法的时间复杂度为 O(log n)
用科学计算包numpy来实现矩阵法 O(log n)

### 1 import numpy def fib_matrix(n): res = pow((numpy.matrix([[1, 1], [1, 0]])), n) * numpy.matrix([[1], [0]]) return res[0][0] for i in range(10): print(int(fib_matrix(i)), end=' ') ### 2 # 使用矩阵计算斐波那契数列 def Fibonacci_Matrix_tool(n): Matrix = npmpy.matrix("1 1;1 0") # 返回是matrix类型 return pow(Matrix, n) # pow函数速度快于 使用双星好 ** def Fibonacci_Matrix(n): result_list = [] for i in range(0, n): result_list.append(numpy.array(Fibonacci_Matrix_tool(i))[0][0]) return result_list # 调用 Fibonacci_Matrix(10)
练习题
1、简述普通参数、指定参数、默认参数、动态参数的区别
# 普通参数:按照形式参数的指定位置 传入参数。 # 指定参数:可以在实际参数里指定任意位置,传入参数。 # 默认参数:如果实际参数没有给形式参数传入值 那么默认使用的参数就是默认参数 默认参数需要放到尾部 # 动态参数:可以无限传入任意参数,如果是*代表传入参数的形式将会是元组 **表示将会是字典
2、写函数,计算传入字符串中【数字】、【字母】、【空格] 以及 【其他】的个数
#!/usr/bin/env python # -*-coding:utf-8 -*- def counts(str): num_counts=0 al_counts=0 space_num=0 other=0 for i in str: if i.isdigit(): num_counts += 1 elif i.isalpha(): al_counts += 1 elif i.isspace(): space_num +=1 else: other += 1 print(num_counts,al_counts,space_num,other) counts('123 456abc def g_*-/')
3、写函数,判断用户传入的对象(字符串、列表、元组)长度是否大于5。
#!/usr/bin/env python # -*-coding:utf-8 -*- def length(input): if isinstance(input,str) or isinstance(input,list) or isinstance(input,tuple): if len(input) > 5: print("大于5") return True else: print("小于5") return False else: print("类型错误!") return None length("abc544") li = ['123','3242','2342','asd',45,22,] length(li) tu=(11,22,33,44,) length(tu) a =123 length(a)
4、写函数,检查用户传入的对象(字符串、列表、元组)的每一个元素是否含有空内容。
#!/usr/bin/env python # -*-coding:utf-8 -*- def has_space(str): ret = False for i in str: if i.isspace(): ret = True break return ret ret = has_space('22 123') print(ret)
5、写函数,检查传入列表的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。
#!/usr/bin/env python # -*-coding:utf-8 -*- def check(li): if len(li)>2: del li[2:] li = [11,22,33,44,55] check(li) print(li)
6、写函数,检查获取传入列表或元组对象的所有奇数位索引对应的元素,并将其作为新列表返回给调用者。
#!/usr/bin/env python # -*-coding:utf-8 -*- def check(li): return li[0:len(li):2] li = [11,22,33,44,55,66,77,88,99] ll = check(li) print(ll)
7、写函数,检查传入字典的每一个value的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。
dic = {"k1": "v1v1", "k2": [11,22,33,44]}
PS:字典中的value只能是字符串或列表
#!/usr/bin/env python # -*-coding:utf-8 -*- dic = {"k1": "v1v1", "k2": [11,22,33,44],"k3":'1'} def check(dic): for k,v in dic.items(): if len(v)>2: dic[k]=v[0:2] return dic check(dic) print(dic)
8、写函数,利用递归获取斐波那契数列中的第 10 个数,并将该值返回给调用者。
#!/usr/bin/env python # -*-coding:utf-8 -*- def f1(a1,a2,depth): if depth == 10: return a1 a3 = a1 + a2 a1 = f1(a2,a3,depth+1) return a1 a = f1(0,1,1) print(a)

