

Bag of Tricks for Image Classification with Convolutional Neural Networks论文笔记
一、高效的训练
1、Large-batch training
使用大的batch size可能会减小训练过程(收敛的慢?我之前训练的时候挺喜欢用较大的batch size),即在相同的迭代次数下,
相较于使用小的batch size,使用较大的batch size会导致在验证集上精度下降。文中介绍了四种方法。
Linear scaling learning rate
梯度下降是一个随机过程,增大batch size不会改变随机梯度的期望,但是减小了方差(variance)。换句话说,增大batch size
可以减小梯度中的噪声,所以,此时应该增大学习率来进行调整:随着batch size的增加,线性增加学习率。比如,初始学习率0.1,
batch size=256,当batch size增加为b时,学习率为0.1×b/256
Learning rate warmup
开始使用一个较小的学习率,当训练稳定后,再切换回初始学习率。例如使用5个epochs来warm up,初始学习率为n,在第i个batch,
1<=i<=m,学习率lr=i*n/m
Zero γ
在残差模块中,最后一层为BN层,先对x标准化输出为x̂, 再做一个尺度变换γ x̂ + β。γ和β都为可学习参数,被初始化为1和0。Zero γ
策略是,对于残差模块最后的BN层,γ设为0,相当于网络有更少的层数,在初始阶段更容易训练。
No bias decay
weight decay一般应用在所有可学习参数上,包括weight和bias。为了防止过拟合,只在weights上做正则化,其他参数,包括bias,BN中的
γ和β都不做正则化。
2、Low-precision training
用FP16对所有的parameters和activations进行存储和梯度的计算,与此同时使用FP32对参数进行拷贝用于参数的更新。另外,在损失函数上
乘以一个标量来将梯度的范围更好的对齐到FP16也是一个实用的做法
3、实验
很奇怪的对比实验,应该再加上相同的batch size才更有说服力啊。

二、Model Tweaks
Model Tweaks是指修改模型的结构,比如某个卷基层的stride。本文以resnet为例,探讨这些tweak对精度的影响。
1、ResNet Architecture
一个典型的resnet50结构如下,其中input stem首先使用7*7卷积,stride=2,接着一个3*3的maxpool,stride=2。
input stem将特征减小至1/4,维度增加至64。从state2开始,每个stage包括down sampling和2个residual模块,如图。
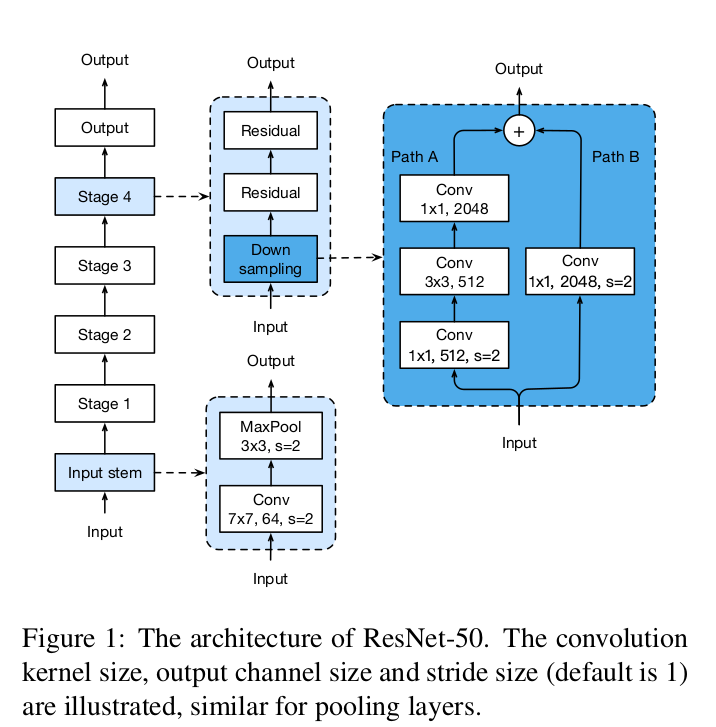
2、ResNet Tweaks
resnet-B更改了down sampling中 stride=2的位置,不让1*1的stride=2,
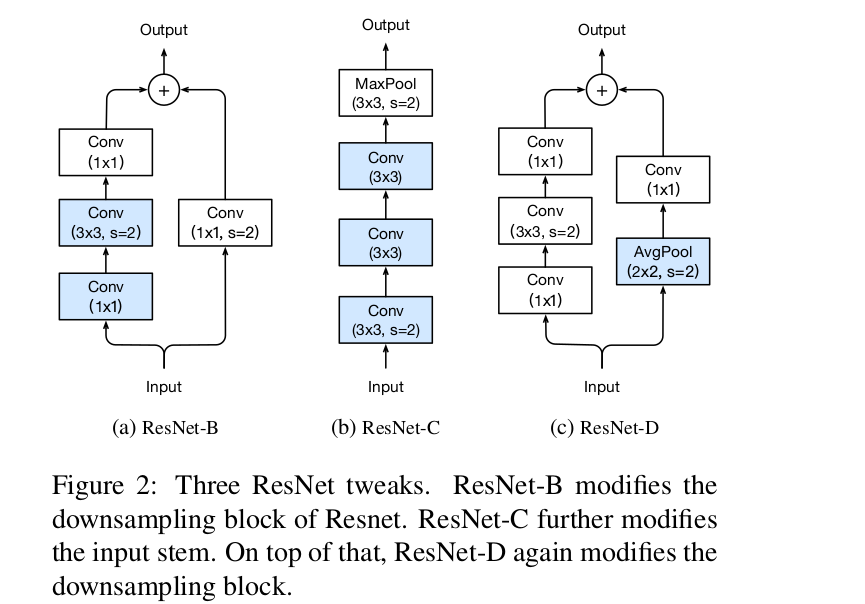
resnet-C将input stem中的7×7卷积用3个3*3代替(节省参数),前两个c=32,最后一个为64.。
为了减小stride=2,1*1卷积的损失,增加avg pool,conv stride=1(这样就不损失吗。。。)对比发现,
resnet-D效果最好。

三、Training Refinements
通过介绍训练中的策略,进一步提高模型准确率
Cosine Learning Rate Decay
其中η是学习率(不包括warm up阶段),不过看validation accur,step decay并不差于cosine decay啊

Label Smoothing
正常的交叉熵损失在预测的时候,对于给定的数据集的label,将正例设为1,负例设为0,是一个one-hot向量。这样子会有一些问题,
模型对于标签过于依赖,当数据出现噪声的时候,会导致训练结果出现偏差。增加一个变量ϵ,对类别进行平滑,此时loss变为,其中p(y)为真是标签,
p(c)为输出类别概率。
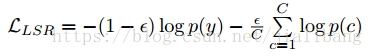
参考: https://zhuanlan.zhihu.com/p/53849733
https://www.cnblogs.com/zyrb/p/9699168.html
Knowledge Distillation
主要用于将大网络压缩为小网络,损失函数为,其中z和r分别是student model和teacher model的输出,p是真实标签的分布
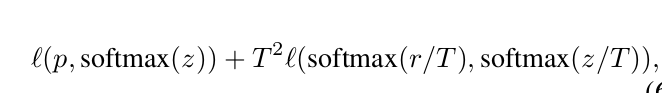
Mixup Training
使用线性插值混合两个样本,构成新的样本,并使用新样本进行训练(没用过知识蒸馏,这意思是teacher model和student model一起训练?)。
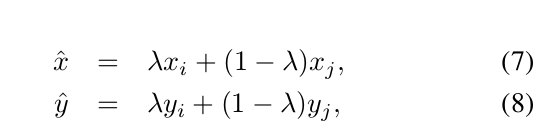
实验
知识蒸馏对mobilnet,inception-v3并没有提升,因为teacher model是resnet,与它们不同。

keras部分实现:https://github.com/Tony607/Keras_Bag_of_Tricks
