
学习笔记:Hashtable和HashMap
学了这么些天的基础知识发现自己还是个门外汗,难怪自己一直混的不怎么样。但这样的恶补不知道有没有用,是不是过段时间这些知识又忘了呢?这些知识平时的工作好像都是随拿随用的,也并不是平时一点没有关注过这些基础知识,只是用完了也就忘了。所以写笔记也是个好习惯,光看一个概念不容易记住,整理写成文那就好许多,以后查起来也方便一些。
为什么要用Hash Table?
这就想到了以前工作中遇到的一个事情。多年前我还在写delphi,软件功能中有许多的批量数据运算,由于数据要拉取到内存中,然后多个数据集合间进行遍历查找对比,这样的话数据量一多就会非常的慢,而且经常会遇到内存错误,一直也找不出原因。后来有一位经验丰富的老程序员加入,他就提出了使用hashtable来解决这个问题。
经过测试果然大幅度的提高了性能,以下就来简单分析下:
我们的数据对象是通过对比主键字段进行定位的,而这个字段是string类型,长度为40,要在一个数据集合中找一条数据就要去遍历,然后对比主键是否相同,这就有两个问题:
1、字符串与字符串进行比较如果量少问题不大,如果数据量大的话就是个很大的问题,毕竟每次都是40个字节与40字节长度对比呀
2、由于数据是存在内存链表中的,想要定位一个数据就要搜索查找,更何况是大量的循环查找
要解决这两个问题分别要做什么:
1、减少主键字段对比时的时间,比如采用整形类型,这样就只有4个字节
2、优化算法,提高数据查找效率,或者提高数据定位的效率
我们采用的hashtable很符合这些要求,Hashtable的存储结构使用的是:数组+链表的方式。
首先,将数据存在数组中,利用数组的寻址能力不就很快吗
其次,对Key进行hash运算,这样就可以使用Int类型,这又解决了字符串比较的问题
看到了好处就有了继续学习下去的动力了,一步步来吧。
什么是Hash Table
对于Hash table名字应该不陌生,先看看定义吧
散列表(Hash table,也叫哈希表),是根据关键字(Key value)而直接访问在内存存储位置的数据结构。也就是说,它通过把键值通过一个函数的计算,映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
要理解的具体一点,就要将散列这个概念多了解一些,还是继续看维基百科吧,一点点来理解:
- 若关键字为
,则其值存放在
的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系
为散列函数,按这个思想建立的表为散列表。
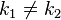 ,而
,而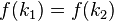 ,这种现象称为碰撞(
,这种现象称为碰撞(这里说了几个比较重要的概念:关键字、散列函数、碰撞。应该说已经说的很明白了,没啥好难理解的。
散列函数有许多种实现方法,下面也列一下吧:
散列函数能使对一个数据序列的访问过程更加迅速有效,通过散列函数,数据元素将被更快定位。
- 直接定址法:取关键字或关键字的某个线性函数值为散列地址。即
或
,其中
为常数(这种散列函数叫做自身函数)
- 数字分析法:假设关键字是以r为基的数,并且哈希表中可能出现的关键字都是事先知道的,则可取关键字的若干数位组成哈希地址。
- 平方取中法:取关键字平方后的中间几位为哈希地址。通常在选定哈希函数时不一定能知道关键字的全部情况,取其中的哪几位也不一定合适,而一个数平方后的中间几位数和数的每一位都相关,由此使随机分布的关键字得到的哈希地址也是随机的。取的位数由表长决定。
- 折叠法:将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址。
- 随机数法:将关键字分割成位数相同的几部分,最后一部分位数可以不同,然后取这几部分的叠加和(去除进位)作为散列地址。数位叠加可以有移位叠加和间界叠加两种方法。移位叠加是将分割后的每一部分的最低位对齐,然后相加;间界叠加是从一端向另一端沿分割界来回折叠,然后对齐相加。
- 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即
,
。不仅可以对关键字直接取模,也可在折叠法、平方取中法等运算之后取模。对p的选择很重要,一般取素数或m,若p选择不好,容易产生碰撞。
有点悬乎,无非就是直接用某个数字或者通过计算得到一个数字作为数组的下标,就是存储的位置地址,这样存与取都可以直接定位了,简单高效。不管是哪一种方法都有一个共同的问题,就是hash计算结果可能相同,也就是碰撞问题。那么就得有办法去解决这问题,看了看资料有几种方法:
- 开放定址法:如果发生冲突就继续找下一个空的散列地址
- 单独链表法:即在发生冲突的位置直接使用链表保存冲突的数据
- 再散列:即在上次散列计算发生碰撞时,用另一个散列函数计算新的散列函数地址,直到碰撞不再发生
- 建立公共溢出区:建立基本表和溢出表,冲突的就放到溢出区
参考文章:
http://zh.wikipedia.org/zh/%E5%93%88%E5%B8%8C%E8%A1%A8
http://c.biancheng.net/cpp/html/1031.html
简单学习下Hash Table的机制
到这好像也差不多了解了HashTable的作用与好处,接下来就有了继续学习HashTable的动力。前面提到的那个Delphi的Hash Table类使用的存储结构是数组+链表的形式,源代码也找不到了,下面就以Java的Hash Table类作为对象来学习吧。
-
存储结构
对于Java SDK中默认实现的HashTable类使用的存储结构是数组+单链表,有了前面的概念就明白了,数组即是用于存储数据的连续的地址空间,而链表是用来解决碰撞问题的。这样就利用了数组高效的寻址能力,又通过链表解决了碰撞的存储问题。
先看数组:
/** * The hash table data. */ private transient Entry[] table;
再看数据链表

/** * Hashtable collision list. */ private static class Entry<K,V> implements Map.Entry<K,V> { int hash; K key; V value; Entry<K,V> next; protected Entry(int hash, K key, V value, Entry<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } protected Object clone() { return new Entry<K,V>(hash, key, value, (next==null ? null : (Entry<K,V>) next.clone())); } // Map.Entry Ops public K getKey() { return key; } public V getValue() { return value; } public V setValue(V value) { if (value == null) throw new NullPointerException(); V oldValue = this.value; this.value = value; return oldValue; } public boolean equals(Object o) { if (!(o instanceof Map.Entry)) return false; Map.Entry e = (Map.Entry)o; return (key==null ? e.getKey()==null : key.equals(e.getKey())) && (value==null ? e.getValue()==null : value.equals(e.getValue())); } public int hashCode() { return hash ^ (value==null ? 0 : value.hashCode()); } public String toString() { return key.toString()+"="+value.toString(); } }
其实还是挺简单的,就是一个Entry数组,而Entry就是一个键值关系表,同时提供了链表的功能。
-
数据存取
写了这么多代码,打开Hashtable的代码发现也就这那些东西吧,关键的是就是存与取。
先看存一个数据的方法put:
public synchronized V put(K key, V value) { // Make sure the value is not null if (value == null) { throw new NullPointerException(); } // Makes sure the key is not already in the hashtable. Entry tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { V old = e.value; e.value = value; return old; } } modCount++; if (count >= threshold) { // Rehash the table if the threshold is exceeded rehash(); tab = table; index = (hash & 0x7FFFFFFF) % tab.length; } // Creates the new entry. Entry<K,V> e = tab[index]; tab[index] = new Entry<K,V>(hash, key, value, e); count++; return null; }
- 这里看到了线程同步关键字,因为整个hashtable都是线程同步的,所以在线程里用也是木有问题的
- 注意valua是不能为null的会抛异常
- 将要存的数据以key-value的方式放进去,先通过key计算Hash值,就是数组位置
看看关键代码:
int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length;
先得到key的hashcode,再通过除留余数法得到数组索引,简单高效就得到了存储位置。
- 然后后面的代码看看有没有相同的项目,有则替换之。最后创建一个Entry对象保存数据,如果存在碰撞Entry会自动写入链表中解决冲突。
获得数据的方法就是get:
public synchronized V get(Object key) { Entry tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { return e.value; } } return null; }
计算数组下标的方法是一样的,这样的定位方式特别高效,只要计算一次就可以了,当然如果有冲突的话还要遍历链表对比hash和key再确定最终的数据项。
再看看HashMap
在haspMap中实现的思想其实和hashtable大体相同,存储结构也类似,只是一些小区别:
- key和value支持null,这种情况下总是存在数组中的第一个元素中,感觉是种特殊公共溢出区的应用
- 不是线程安全的,需要自己做线程同步
- 计算存储位置时采用了在hashcode上再次hash+indexFor的方法,使得得到的散列值更均匀
注:此文章为原创,欢迎转载,请在文章页面明显位置给出此文链接!
若您觉得这篇文章还不错请点击下右下角的推荐,非常感谢!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人