第二次作业
-
(1) 码云代码仓库地址
-
(2) PSP表格记录估计将在程序的各个模块的开发上耗费的时间
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 1 | 40 |
| · Estimate | · 估计这个任务需要多少时间 | 1 | 40 |
| Development | 开发 | 3500 | 1400 |
| · Analysis | · 需求分析 (包括学习新技术) | 1800 | 250 |
| · Design Spec | · 生成设计文档 | 2 | 80 |
| · Design Review | · 设计复审 | 2 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 2 | 20 |
| · Design | · 具体设计 | 850 | 30 |
| · Coding | · 具体编码 | 850 | 740 |
| · Code Review | · 代码复审 | 2 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 90 | 200 |
| Reporting | 报告 | 9 | 100 |
| · Test Repor | · 测试报告 | 3 | 15 |
| · Size Measurement | · 计算工作量 | 3 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 3 | 70 |
| 合计 | 3600 | 1540 |
我以前没有做过相关的软件工程项目,所以预估耗时是通过我学习代码的时间来估计,我参考的python教程总时间大约为3600分钟,其中大约有一半时间是自己在练习敲代码,以此为标准预估 了我的耗时。具体耗时是通过我的每日学习记录统计而来,除了具体敲代码花了不少时间,其余的项目花的时间都较少,原因为很多技术性问题参考了网上的解法以及相关资料及时得到了解决。
-
(3) 计算模块接口的设计与实现过程
我的代码包括了两个函数,分别为统计字符数目的函数,分离单词存入列表的函数。在统计单词数目时,在单词列表中筛选出不符合的单词,然后统计数目。在排序时,会先将列表转为字典键 值,统计的频率录入为值,并按值倒序排序。然后再转为列表,再按字典序排序,最后将前十位输出。
-
(4) 性能改进
我在统计字符的函数中将所有的字符统一转化为小写,这样方便统计单词频率。通过尽可能少的循环来改进函数,这是我的改进方式。

-
(5) 单元测试
手工进行单元测试,将测试用例和结果列示如下:
1.输出单词排序时单词均为小写。
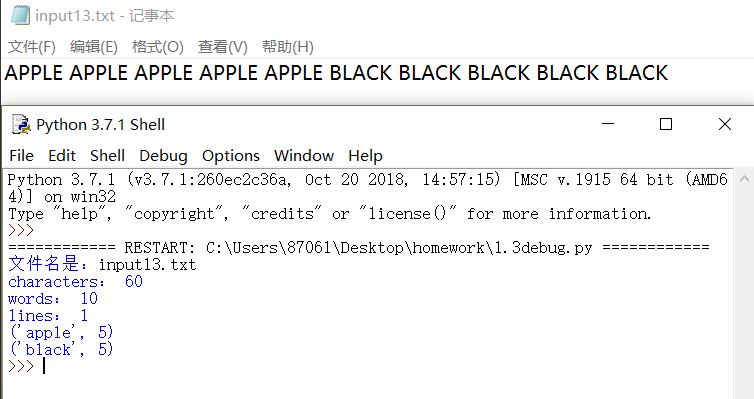
2.输出单词排序时单词最多十个
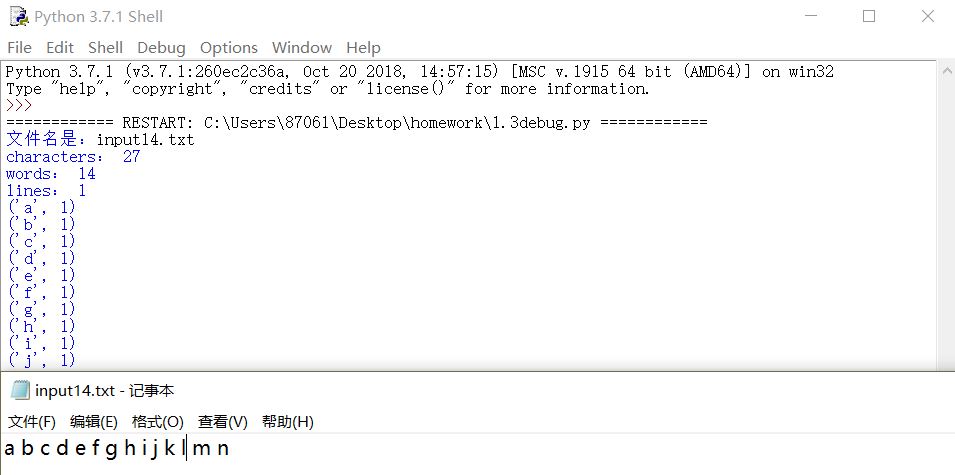
3.输出单词按字典序输出
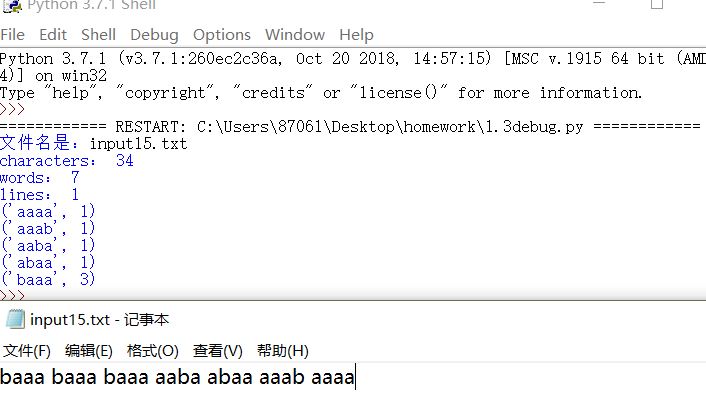
4.文本含空行
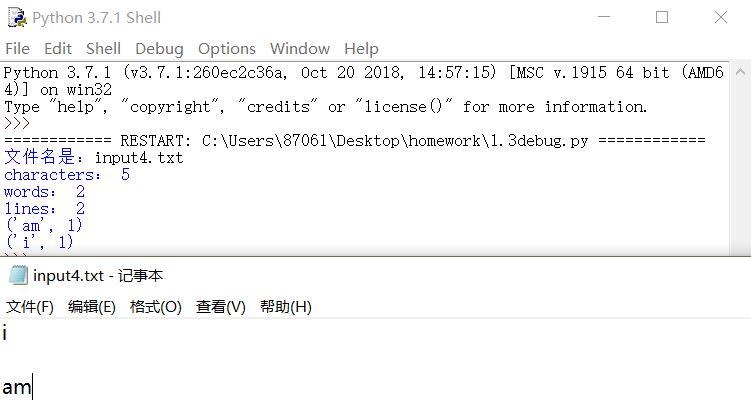
5.相同含义大小写单词按同一种统计
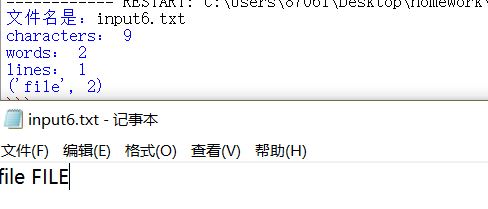
6.输入的文本含特殊字符
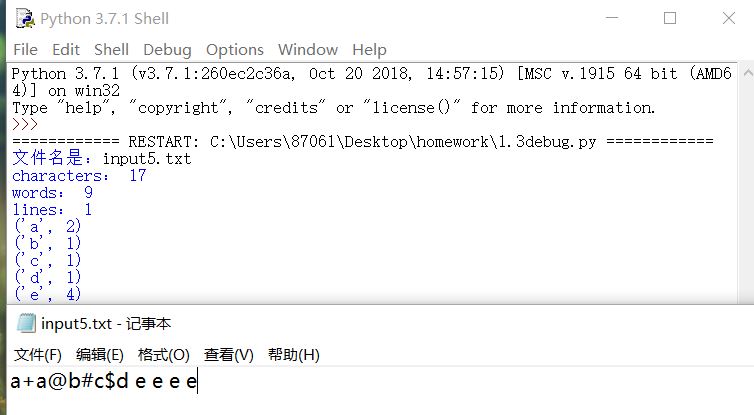
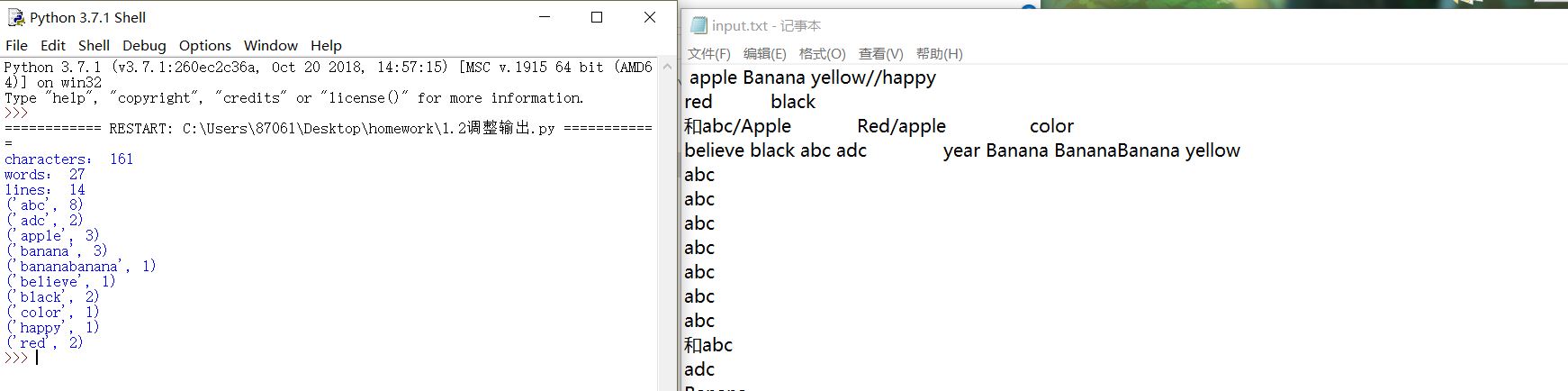
7.文本为空
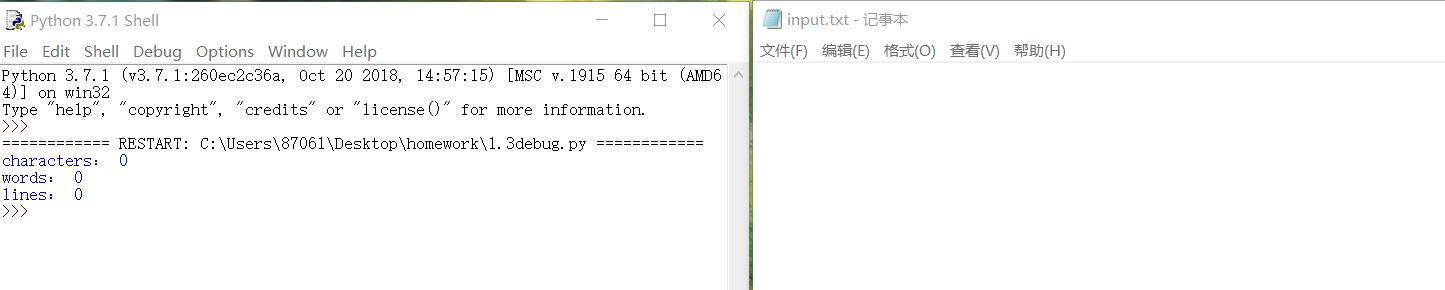
8.单个数字不算单词
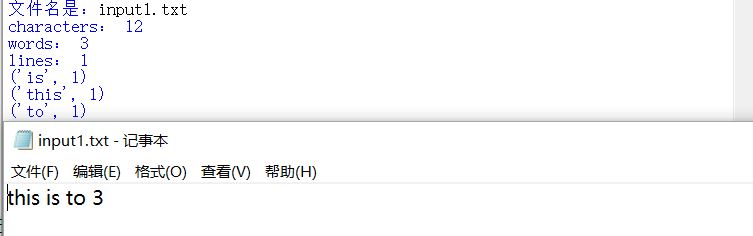
9.只含有特殊字符
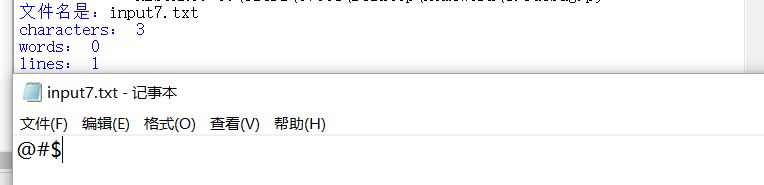
10.不统计有汉字的单词,汉字也不统计在字符数中
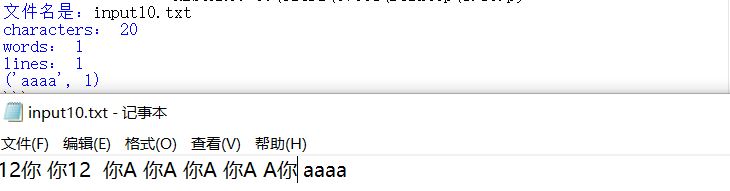
11.行首有空格
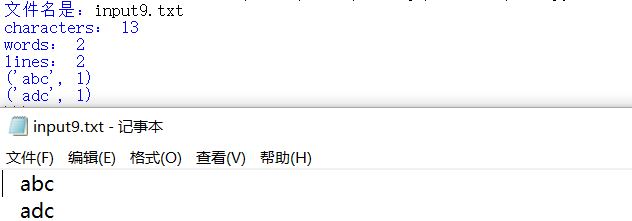
12.数字开头不算单词,字母开头含数字算单词

-
(6) 解题思路
1、考虑先把文档内容全部读进一个列表里,我运用了列表的append添加方法,用readlines命令达成了分行录入,并筛选出空行,用len语句就可以算出行数。
2、同样,利用spilt()语句,将文档内容按分隔符分开,每一个部分视作一个小块,分别求这些小块的长度,就能得到字符数。
3、先算出2中小块数,再减去不符合规则的小块,得到单词数。
4、由于统计的字符数中不包括汉字,所以考虑利用ascii码筛选。
5、统计频率时通过字典计数按值逆序排序转为列表,在列表内正序排序输出
附:学习日志
学习时段
12月27日下午2点至6点半
学习内容
1、安装git。
2、仔细阅读题目要求,开始解决第一个功能,统计字符和行数。
收获体会
1、到目前为止git依旧提交错误,原因未知,决定手工上传。
2、长达4个小时的摸索,终于实现了这个功能。
自我效率评价
低,python语言不熟悉。
学习时段
12月28日下午9点半至10点半
学习内容
1、调试昨天的代码,尝试优化精简。
2、解决统计文件的单词总数的问题。
收获体会
1、参考了https://blog.csdn.net/tangwg5/article/details/77405850与https://blog.csdn.net/w417950004/article/details/78424366的方法,优化了代码。
2、在社区里py大神的帮助下,实现了统计单词个数的功能,关键是学会了split语句的循环,找出了消除各种分隔符的方法。
3、不合格单词的筛选方法还需进一步摸索。
自我效率评价
高,社区大神就是牛。
学习时段
12月29日下午6点至7点半
学习内容
1、突然发现没有分离中英文,导致程序不符合要求。
2、解决分离中英文的问题。
收获体会
1、参考了https://blog.csdn.net/sinat_36972314/article/details/79746291的方法,找到了应用ascii码筛选中英文的方法。
2、尝试多次终于发现ord()语句有奇效。
自我效率评价
低,搞了一个小时才仅仅修了一个bug。
学习时段
12月30日下午10点30至11点
学习内容
1、完成课堂作业
收获体会
1、尝试了多种日期组合
自我效率评价
高,比较简单,但是教员用的二维数组方法没有成功实现。
学习时段
12月31日下午5点至6点
学习内容
1、筛选不合规单词
2、英文大小写视作同一个单词
收获体会
1、通过转换为列表取首字母来筛选ascii码成功实现了功能1
2、通过在初次导入时全部转换为小写来实现功能2
自我效率评价
高,与列表有关的各种代码开始上手了
学习时段
1月1日下午8点至9点半
学习内容
1、英文大小写视作同一个单词
2、统计单词数量
收获体会
1、 参考https://zhidao.baidu.com/question/2142973902937612788.html的代码,学到了全部单词改小写的lower语句,尝试后完成了改小写的功能,这样就可以方便精确统计单词个数。
2、统计单词数量一直没想到好方法,参考https://www.cnblogs.com/cuihengyue/p/8847310.html的代码突然茅塞顿开,用dic字典储存就能自动去重复,并且单词由列表导入字典时也方便统计个数。
3、完成字典序输出前十个单词,一开始是通过转换成列表排序,后来发现可以直接用sort语句直接对字典中的值来排序,减少了代码量。
4、字典序是顺序,数量前十个是倒序,一开始没注意要用两次排序出了bug。
自我效率评价
高,换一种思路果然能节省不少时间。
学习时段:1月2日上午10点至11点
学习内容:1、调整输出格式
收获体会:1、打印换行通过\n或for语句实现
自我效率评价:高。
学习时段:1月3日上午8点至9点30
学习内容:1、debug
收获体会:1、发现了输入空白文档会报错的bug,改进程序后修复。
自我效率评价:高。
学习时段:1月10日下午4点至6点
学习内容:1、debug
收获体会:1、进行单元测试时发现很多种特殊情况都没有考虑到,debug的过程中对代码进行了大量修正。
自我效率评价:高,结对编程能使许多自己发现不了的问题显露出来。
