
20145319 第六周学习总结
20145319 《Java程序设计》第六周学习总结
教材学习内容总结
本周学习教材的第十、十一章,主要讲述了串流,字符处理和线程以及并行API
1. 输入输出
-
串流:1Java中的数据有来源(source)和目的地(destination),衔接两者的就是串流对象2串流设计:在不知道限定数据来源和目的地时,也可以依赖抽象的InputStream和Outstream来编写一个dump()方法,方便以后使用3InputStream和OutputStream:在java中,输入串流代表对象为java.io.InputStream实例,输出串流代表对象为java.io.OutputStream
-
串流的继承结构:
- 标准输入和输出:System.in和System.out就是InputStream和OutStream的实例,然而System.in通常很少直接操作InputStream相关方法,可以转而使用setIn()来指定InputStream实例,如System.setIn(new FileInputStream(args [0]))
- FileInputStream和FileOutputStream:FileInputStream是InputStream的子类,一旦创建文档就开启,就可以用来读取数据,FileOutputStream是outStream实例,一旦创建就可以写出数据,且不使用时都需要用close()来关闭
- ByteArrayInputStream与ByteArrayOutputStream可以指定byte数组创建实例,创建后将byte数组当作数据源进行读取
- 以上各关键词其实都是操作了InputStream和OutStream中的read()和write()抽象方法
3. 串流处理装饰器:
- 定义:InputStream和OutputStream都只提供串流的基本操作,而想对数据进行加工处理时,就要使用打包器类,如Scanner,装饰器就是这些对数据进行了一些加工处理,例如缓冲、串行化、数据装换等
- BufferInputStream与BufferOutputStream:将数据尽量地读取足够数据至内存的缓冲区,减少从来源直接读取数据的次数,从而提高效率(访问内存的速度较快)
- DataInputStream与DataOutputStream:提供读取写入java基本类型的方法,这些方法会自动在指定的类型和字节中转换
2. 线程
之前学习的各种实例都是单线程的,即程序从main()进入后只有一个流程,但是在设计时候可以根据需要拥有多个流程,就是多线程(Multi-thread)程序
- Thread和Runable:
- JVM即一台虚拟机,只有主线程的CPU,如果想增加CPU就得创建thread实例,CPU执行的进入点,定义在Runnable的run()方法中
- 撰写多线程程序可以操作Runnable接口,也可以继承Thread类,重新定义run()方法,但操作Runnable接口会使得程序更富弹性
2. 线程生命周期
- Daemon线程:在所有的非Daemon线程结束时,JVM就会自动终止
- 基本状态图:start—>runnable—>(blocked)—>running—>dead , Thread.sleep()、wait()阻断、输入输出完成等都会让线程进入blocked状态,当某线程进入Blocked,最好让另一线程进入running状态,避免cpu空闲下来,是改进效能的方式之一。
- join():安插线程,在A执行的时候插入B,等B完成后在进行A(可以指join()的时间,如join(1000)即为加入线程最多执行1000毫秒)
3. 等待和通知
- wait():指定等待排班时间
- notify():通知加入排班
- notifyall():锁定竞争,通知所有等待中的线程参与排班
4. 并行API
- Lock、ReadWriteLock和Condition:提供类似synchronized、wait()、notify()、notifyall()的作用以及更多高级功能
- Executor :Executor接口可以将Runnable的指定与实际如何执行分离
- Future与Callable搭配使用
教材学习中的问题和解决过程
chapter10:AC BD AC BD A BC BD BD D ABD
chapter11:A C B AB AB D B A B CD
代码调试中的问题和解决过程
最近在学习新内容的回过头打算把前几章的课后操作题写一写,本以为会比较轻松,但操作起来没有意料中那样简单。
代码(汉诺塔):
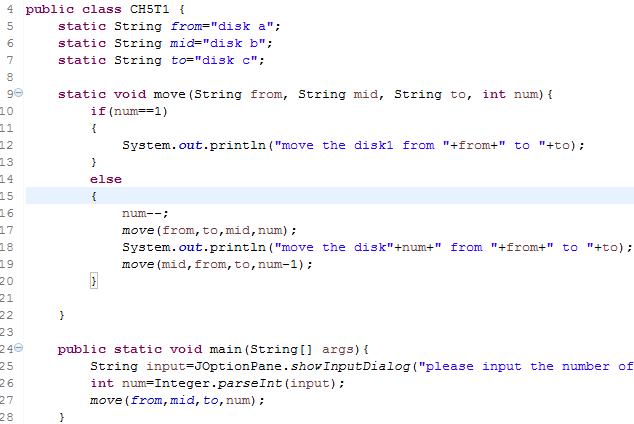
这段程序看上去没有什么问题,但是在其中有一些问题
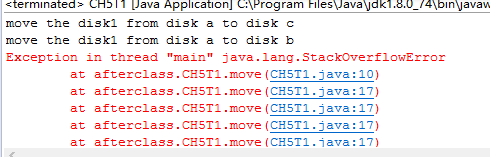
首先我们要了解程序到底出现了什么问题,java.lang.StackOverflowError其实说的就是这个程序出现了栈溢出,所以导致程序无法正常运行
那什么是栈溢出?什么又会导致栈溢出呢?
我们都知道缓冲区的数据不得大于缓冲区的大小,而栈溢出就是指这个数据足够大的时候,溢出缓冲区的范围。
而导致栈溢出一般会有两种情况,一是变量体积太大,例如在写程序时定义变量 int abc[]=new int[2*1024*1024]
第二个就是上程序出现的问题了: 函数调用层次过深,每调用一次,函数的参数、局部变量等信息就压一次栈
在move函数循环调用自身时,num--;……move(mid, from, to, num-1);这里在函数中又使用num-1就导致了函数将一直循环,将其修改成move(mid, from ,to,num)即可
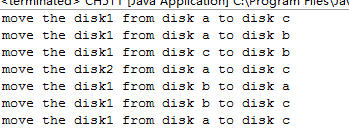
汉诺塔运行成功
其他(感悟、思考等,可选)
- 在回过头看以前的操作题时候,发现很多操作题的思路数据结构和算法教材上都有,感觉先弄懂算法再编程效果会好很多
学习进度条
|
|
代码行数(新增/累积) |
博客量(新增/累积) |
学习时间(新增/累积) |
重要成长 |
|
目标 |
3500行 |
28篇 |
300小时 |
|
|
第五周 |
200/1200 |
1/5 |
20/105 |
|
|
第六周 |
300/1500 |
2/7 |
25/130 |
|
|
第七周 |
|
|
|
|
|
第八周 |
|
|
|
|
参考资料
posted on 2016-04-10 20:10 20145319钟轲 阅读(192) 评论(3) 编辑 收藏 举报

