

20135327郭皓——期中复习总结
|
学习计时:共3小时 读书: 代码: 作业: 博客: |
|
一、学习目标 |
|
复习前面Linux 命令,Linux 编程基础,教材前七章内容
|
Linux命令
- Linux Bash中,Ctrl+a快捷键的作用是将光标移至输入行头,相当于Home键。
- Linux Bash中, man printf和man 1 printf 功能等价。
- 在 Linux 里面可以使用使用groups命令知道自己属于哪些用户组。
- 在 Linux 里面可以使用使用chmod命令修改文件的权限。
- Linux中没有C盘,D盘,其文件系统的目录是由FHS标准规定好的。
- Linux Bash中,cd ~ 命令可以切换到'home'目录,cd -切换到上一个目录。
- Linux Bash中,强制删除test文件的命令是rm -f test 。
- Linux Bash中,cat -n 和 nl 命令功能等价。
- Linux Bash中,source 和 . 命令功能等价。
- Linux Bash中,查找home目录中x天创建的文件的命令是find ~ -ctime x。
- Linux Bash中,使用tar命令把home目录打包成home.tar的命令是 tar -cf home.tar ~
- Linux Bash中,zip命令使用-e参数可以创建加密压缩包。
- Linux Bash中,df和 du 命令功能不等价
- Linux Bash中,ls . | sort 命令的功能是显示当前目录内容并排序
- Linux Bash中,使用grep查找当前目录下*.c中main函数在那个文件中的命令是grep main *.c
- Linux Bash中,使用wc统计hello.c共有几行代码的的命令是wc -l hello.c
- Linux Bash中,把ls命令显示当前目录的结果存入ls.txt的命令输出重定向命令是ls > ls.txt
- Linux Bash中,tee命令可以同时重定向到多个文件。
- vi中查看函数qsort的帮助文档的快捷键为K。
- Linux中显示文件file属性status的命令stat。
- 使用du命令对当前目录下的目录或文件按大小排序 的命令是du -sk *| sort -rn
- grep ~/test 文件夹下有很多c源文件,查找main函数在哪个文件中的命令grep main *.c
- gdb中next和step都可以单步跟踪,根据自顶向下原则应该优先选用next.
- 数据结构中有线性查找算法,C标准库中没有这个功能的函数,但Linux中有,这个函数是(lfind或lsearch)
- To list the content of /path/to/foo.tgz archive using tar ( tar -jtvf /path/to/foo.tgz )
- 查找当前目录下所有目录的find命令是(find . -type d)
- 查找宏 STDIN_FILENO 的值的命令是(grep -nr XXX /usr/include)
vi, gcc, gdb,make的使用
Vi的使用
一、Vim的六种基本模式
1.普通模式
Vim的普通模式用的编辑器命令,比如移动光标,删除文本等等。这也是Vim启动后的默认模式,而不是大多数编辑器的插入模式。
普通模式命令往往需要一个操作符结尾。
普通模式进入插入模式的方法:a键(append/追加)键或者i(insert/插入)键。
2.插入模式
在这个模式中,大多数按键都会向文本缓冲中插入文本。大多数新用户希望文本编辑器编辑过程中一直保持这个模式。
插入模式中回到普通模式:ESC键。
3.可视模式
与普通模式类似,但移动命令会扩大高亮的文本区域。高亮区域可以是字符、行或者是一块文本。当执行一个非移动命令时,命令会被执行到这块高亮的区域上。
4.选择模式
这个模式中,可以用鼠标或者光标键高亮选择文本。
如果输入任何字符,Vim会用这个字符替换选择的高亮文本块,并且自动进入插入模式。
5.命令行模式
在命令行模式中可以输入会被解释成并执行的文本。例如执行命令(:键),搜索(/和?键)或者过滤命令(!键)。
在命令执行之后,Vim返回到命令行模式之前的模式,通常是普通模式。
6.Ex模式(Ex mode)
这和命令行模式比较相似,在使用:visual命令离开Ex模式前,可以一次执行多条命令。
※三种常用模式的切换:
常用模式:普通模式、插入模式和命令行模式。
普通→插入: i 或 a
插入→普通: Esc 或 Ctrl + [
普通→命令行: :
命令行→普通:Esc 或 Ctrl + [命令行模式下输入wq ,回车后保存并退出。
二、进入Vim
1.使用vim命令进入vim界面
(1)vim后面加上你要打开的已存在的文件名,或者不存在的文件名作为新建文件。
$ vim practice_1.txt(2)直接使用vim也可以打开vim编辑器,但是不会打开任何文件。
$ vim(3)进入命令行模式后输入:e 文件路径 同样可以打开相应文件。
2.游标移动
在进入vim后,按下i键进入插入模式,在该模式下可以输入文本信息;按Esc进入普通模式,在该模式下使用方向键或者h,j,k,l键可以移动游标。
具体按键如下:
h 左
l 右(小写L)
j 下
k 上
w 移动到下一个单词
b 移动到上一个单词三、进入插入模式
在普通模式下使用下面的键将进入插入模式,并可以从相应的位置开始输入。具体按键对应如下:
i 在当前光标处进行编辑
I 在行首插入
A 在行末插入
a 在光标后插入编辑
o 在当前行后插入一个新行
O 在当前行前插入一个新行
cw 替换从光标所在位置后到一个单词结尾的字符※每次要先回到普通模式才能切换成以不同的方式进入插入模式
四、保存文档
命令行模式下保存文档
(1)从普通模式输入:进入命令行模式,输入w回车,保存文档。
(2)输入:w 文件名可以将文档另存为其他文件名或存到其它路径下.
五、退出vim
1.命令行模式下退出vim
从普通模式输入:进入命令行模式,输入wq回车,保存并退出编辑
以下为其它几种退出方式:
:q! 强制退出,不保存
:q 退出
:wq! 强制保存并退出
:w <文件路径> 另存为
:saveas 文件路径 另存为
:x 保存并退出
:wq 保存并退出2.普通模式下退出vim
普通模式下输入Shift+zz即可保存退出vim
六、删除文本
1.普通模式下删除vim文本信息
进入普通模式,使用下列命令可以进行文本快速删除:
x 删除游标所在的字符
X 删除游标所在前一个字符
Delete 同x
dd 删除整行
dw 删除一个单词(不适用中文)
d$或D 删除至行尾
d^ 删除至行首
dG 删除到文档结尾处
d1G 删至文档首部
gcc gdb的使用
一、编译器GCC
GCC选项列表
(1)常用选项
-c 只编译不链接,生成目标文件.o
-S 只编译不汇编,生成汇编代码
-E 只进行预编译,不做其他处理
-g 在可执行程序中包含标准调试信息
-o file 将file文件指定为输出文件
-v 打印出编译器内部编译各过程的命令行信息和编译器的版本
-I dir 在头文件的搜索路径列表中添加dir目录(2)库选项
-static 进行静态编译,即链接静态库,禁止使用动态库
-shared 1.可以生成动态库文件
2.进行动态编译,尽可能的链接动态库,没有动态库时才会链接同名静态库
-L dir 在库文件的搜索路径列表中添加dir目录
-lname 链接称为libname.a或者libname.so的库文件。
如果两个库文件都存在,根据编译方式是static还是shared进行链接
-fPIC 生成使用相对地址的位置无关的目标代码,
(-fpic) 然后通常使用gcc的-static选项从该pic目标文件生成动态库文件。编译过程
预处理:gcc –E hello.c –o hello.i; gcc –E调用cpp 生成中间文件
编 译:gcc –S hello.i –o hello.s; gcc –S调用ccl 翻译成汇编文件
汇 编:gcc –c hello.s –o hello.o; gcc -c 调用as 翻译成可重定位目标文件
链 接:gcc hello.o –o hello ; gcc -o 调用ld** 创建可执行目标文件-o后面是接的你给生成的文件指定的名字,如果不指定,则默认为a.out
二、调试工具gdb
使用GCC编译时要加“-g”参数
GDB最基本的命令有:
gdb programm(启动GDB)
l 查看所载入的文件
b 设断点
info b 查看断点情况
run 开始运行程序
bt 打印函数调用堆栈
p 查看变量值
c 从当前断点继续运行到下一个断点
n 单步运行(不进入)
s 单步运行(进入)
quit 退出GDB四种断点:
1.行断点
b [行数或函数名] <条件表达式>2.函数断点
b [函数名] <条件表达式>3.条件断点
b [行数或函数名] <if表达式>4.临时断点
tbreak [行数或函数名] <条件表达式>
Make和Makefile
make工具最主要也是最基本的功能就是根据makefile文件中描述的源程序至今的相互关系来完成自动编译、维护多个源文件工程。
而makefile文件需要按某种语法进行编写,文件中需要说明如何编译各个源文件并链接生成可执行文件,要求定义源文件之间的依赖关系。
最终实现——自动化编译
进入Makefile?
$ vim Makefile1.Makefile 基本规则
Makefile的一般写法:
一个Makefile文件主要含有一系列的规则,每条规则包含以下内容:
-
需要由make工具创建的目标体,通常是可执行文件和目标文件,也可以是要执行的动作,如‘clean’;
-
要创建的目标体所依赖的文件,通常是编译目标文件所需要的其他文件。
-
创建每个目标体时需要运行的命令,这一行必须以制表符TAB开头
格式为:
test(目标文件): prog.o code.o(依赖文件列表)
tab(至少一个tab的位置) gcc prog.o code.o -o test(命令)
.......
即:
target: dependency_files
command2.使用带宏的 Makefile
Makefile中的宏,也称作变量。
变量是在makefile中定义的名字,用来代替一个文本字符串,该文本字符串称为该变量的值。
定义变量的两种方式:
(1)递归展开方式
VAR=var
(2)简单方式
VAR:=var使用变量的格式为:
$(VAR)变量的分类
- 用户自定义变量
- 预定义变量
- 自动变量
-
环境变量
教材前七章内容
一、第一章 计算机系统漫游
重要概念:
信息= 位 + 上下文
二、第二章 信息的表示和处理
三种重要的数字表现形式:1、 无符号数:编码基于传统的二进制表示法,表示大于或等于零的数字。整数表示
1.整型数据类型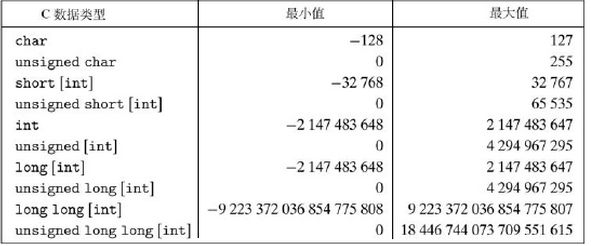
最高位有效位也称符号位,权重为-2^w-1。符号位为1是负为0是正。补码的范围不对称,是因为:一半的数的整数一半是负数,而0是非负数。最大的无符号数值刚好比补码的最大值的两倍大一点。
有符号数还有两种标准的表示方法:反码:除了最高有效位的权是-(2w-1-1)而不是-2w-1,它和补码是一样的。原码:最高有效位是符号位,用来确定剩下的位应该取负权还是正权。 C语言转换的原则是底层的位保持不变。无到有:U2TW。有到无:T2UW
6 扩展一个数字的位表示在不同字长的整数之间转换,同时又保持数值不变。零扩展:开头添07.截断数字:减少表示一个数字的位数。浮点数
1.二进制小数:辗转相除法,2的负幂。,权重是2 的E次幂。情况1:规格化的值。当exp的为模不全为1或0。阶码字段被解释为以偏置形式表示有符号整数。情况2:非规格化的值:当阶码域为全0时,所表示的数就是非规格化形式。在这种情况下,阶码值是E = 1 - Bias,而尾数的值是M = f,也就是小数字段的值,不包含隐含的开头的1情况3:特殊值:阶码域全为1。小数域全为0,得到的值表示无穷。在表示未初始化的数据时也很有用。
三、第三章 程序的机器级表示
机器级代码
机器及编程的两个重要抽象
·集体系结构:机器级程序的格式和行为
·机器级程序使用的储存器地址是虚拟地址
一些通常对c语言程序员隐藏的处理器状态是可见的:
·程序计数器:要执行的下一条指令在存储器中的地址
·整数寄存器:存储地址或者整数数据
·条件码寄存器:保存最近执行的算术或逻辑指令的状态信息
·浮点寄存器:放浮点数据
程序存储器:
·程序的可执行机器代码
·操作系统需要的一些信息
·用来管理过程调用和返回的运行时栈
·用户分配的存储器块
过程
·一个过程调用包括将数据(以过程参数和返回值的形式)和控制从代码的一部分传递到另一部分
3.7.1 栈帧结构
·栈帧:为单个过程分配的那部分栈
·寄存器%ebp为帧指针
·寄存器%esp为栈指针 可移动
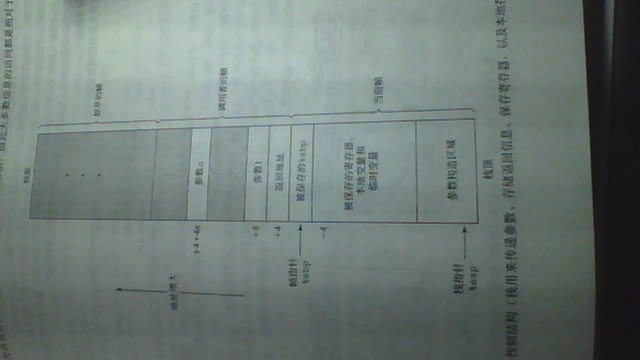
3.7.2 转移控制
·支持调用和返回的指令

3.7.3 寄存器使用管理
·程序寄存器组是唯一能被所有过程共享的资源
·根据惯例:
1.寄存器%eax %edx %ecx被划分为调用者保存寄存器
2.寄存器%ebx %esi %edi被划分为被调用者保存寄存器
3.8.2 指针运算
具体看书p159
·
四、第四章 处理器体系结构
程序员可见的状态
Y86的处理器状态类似IA32,有8个程序寄存器:%eax %ecx %edx %ebx %esi %edi %esp %ebp
·处理器的每个程序寄存器存储一个字。寄存器%esp被入栈,出栈,调用和返回指令作为栈指针。
·3个一位条件码:ZF SF OF
·Y86程序用虚拟地址来引用存储器位置。
·硬件和操作系统软件联合起来将虚拟地址翻译成实际或物理地址。
Y86指令
·Y86 ISA中各指令

·IA32的movl指令分为4个不同的指令:irmovl,rrmovl,mrmovl和rmmovl
·有4个整数操作指令:addl,subl,andl和xorl
·7个跳转码:jmp,jle,ji,je,jne,jge和jg
·6个条件传送码:cmovle,cmovl,cmove,cmovne,cmovge和cmovg
·call:将返回地址入栈,然后跳到目的地址。 ret:从这样的过程调用中返回。
·pushl和popl:入栈和出栈
·halt:停止指令的执行
4.1.3 指令编码
·字节分为两个部分,每部分4位,高4位是代码部分,低部分是功能部分
4.1.4
·状态码Stat:
值1 AOK 正常操作
值2 HLT 处理器执行halt指令
值3 ADR 遇到非法地址
值4 INS 遇到非法指令
Y86的顺序实现
·取指(fetch):从存储器读取指令字节
·译码(decode):从寄存器文件读入最多两个操作数
·执行(execute)
·访存(memory):将数据写入存储器或者从存储器读出数据
·写回(write back):最多可以写两个结果到寄存器文件
·更新PC(PC update):将PC设置成下一条指令地址
五、第六章 存储器层次结构
存储器层次结构中的缓存
·高速缓存:一个小而快速的存储设备,它作为存储在更大、也更慢的设备中的数据对象的缓冲区域
·存储器层次结构的中心思想:对于每个K,位于k层的更快更小的存储设备作为位于k+1层的更大更慢的存储设备的缓存。
1.缓存命中
·当程序需要第k+1层的某个数据对象d时,它首先在当前存储在第k层的一个块中查找d,如果d刚好在第k层,则就是缓存命中
2.缓存不命中
·如果第k层中没有没有缓存数据对象,就是缓存不命中。
3.缓存不命中的种类
·一个空的缓存有时称为冷缓存
高速缓存存储器
CPU和主存之间差距太大,插入一个SRAM高速缓存存储器
L1高速缓存:2~4个时钟周期
L2高速缓存:10个时钟周期
L3高速缓存:30~40个时钟周期
6.4.1 通用的高速缓存存储器结构
S=2^s个高速缓存组
每组E个高速缓存行
每行B=2^b字节的数据块
每行一个有效位
每行 t=m-(b+s)个标记位
高速缓存大小C=S*E*B,不包括标记位和有效位
物理地址m被分为三个字段:
t位标记
s位组索引
b位块偏移
6.4.2 直接映射高速缓存
每个组只有一行的高速缓存称为直接映射高速缓存。高速缓存确定一个请求是否命中,然后抽取出被请求的字1 组选择
2 行匹配
3 字抽取
1、直接映射高速缓存中的组选择
从地址中抽取s个组索引位,解释成一个对应于一个组号的无符号整数,选择相应组。
2、直接映射高速缓存中的行匹配
直接映射高速缓存每个组只有一行,当设置了有效位并且行中的标记与地址中的标记相匹配时,我们得到缓存命中。
3、直接映射高速缓存中的字选择
块偏移位b提供了所需要的字的第一个字节的偏移。
4、直接映射高速缓存中不命中时的行替换
缓存不命中时,需要从下一层取出被请求的块存储在组索引位指示的组中的高速缓存行中。
若组中都是有效行时。需要替换,直接映射高速缓存每组只有一行,就可直接替换。
6、直接映射高速缓存中的冲突不命中
当程序访问大小为2的幂的数组时,直接映射高速缓存中通常会发生冲突不命中。书上的示例中高速缓存反复地加载和驱逐相同的高速缓存块的组(抖动)。改进的办法很简单:在每个数组的结尾放B字节的填充,改变数组元素的组索引。收获
这半个学期以来,我觉得我最大的收获是对自主学习有了更深的理解。说实话,淡出看见这本书是被吓了一跳的,除了字典和小说还从没用过这么厚的书,更何况这是一本要求自学的书,起初内心是十分拒绝的,而且书中内容让我毫无头绪。渐渐地经过一两周的适应期,发现自己并不是想象中的排斥这本书,而且也从中学到不少的知识,每次写博客之前我会看一遍章节内容和要求,记录要写在博客里的内容,写博客时也看一遍,做习题看一遍,考试前看一遍,做作业看一遍,每一次都有新的收获。我认为这半个学期我最大的收获就是在一遍又一遍的学习中理解了真正的自我学习,通过一遍一遍的阅读来发现新的问题和解决前面的问题。
不足
感觉自己不够努力,往往只有三分钟的热情,学习动力不足,正在努力调整自己的状态,同时觉得自己学的很肤浅,我觉得应该是复习不足的原因同时学的有点死板,缺乏求知欲,囫囵吐枣。接下来的学习中希望能调整心态,脚踏实地,认认真真的学习知识。
参考资料:
《深入理解计算机系统》、往期博客;
