
Linux内核分析第六周学习笔记——分析Linux内核创建一个新进程的过程
Linux内核分析第六周学习笔记——分析Linux内核创建一个新进程的过程
zl + 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
进程的两种虚拟机制:虚拟处理器,虚拟内存
任务队列:链表每一项都是进程描述符结构。
进程描述符描述内容:打开的文件,进程地址空间,挂起信号,进程状态
Linux通过slab分配器分配task_struct结构,达到对象复用和缓存着色。
进程标识值:内核通过唯一的PID来标识每个进程。
进程状态:进程描述符中state域描述了进程的当前状态。
TASK_RUNNING(可执行)
TASK_INTERRUPTIBLE(正被阻塞)
TASK_UNINTERRUPTIBLE(不可中断)
_TASK_TRACED(被其他进程跟踪)
_TASK_STOPPED(进程停止执行)
进程家族
所有进程都是PID为1的init进程的后代,内核在系统启动的最后阶段启动init进程
进程创建
1 fork()通过拷贝当前进程创建一个子进程
2 exec()函数读取可执行文件并将其载入地址空间
线程实现
在linux中,线程仅仅被视作一个与其他进程共享某些资源的进程,它只是一种进程间共享资源的手段
内核线程:独立运行在内核空间中的标准进程
它与普通进程的区别在于,内科线程没有独立的地址空间,只在内核空间运行。可以被调度或者抢占。
fork、vfork和clone三个系统调用都可以创建一个新进程,而且都是通过调用do_fork来实现进程的创建
Linux通过复制父进程来创建一个新进程的过程:
复制一个PCB——task_struct
err = arch_dup_task_struct(tsk, orig);
要给新进程分配一个新的内核堆栈
ti = alloc_thread_info_node(tsk, node);
tsk->stack = ti;
setup_thread_stack(tsk, orig); //这里只是复制thread_info,而非复制内核堆栈
要修改复制过来的进程数据,比如pid、进程链表等等都要改改吧,见copy_process内部。
子进程从系统调用中返回,它在系统调用处理过程中开始执行的位置:
子进程的内核堆栈数据状态和task_struct中thread记录的sp和ip的一致性问题在copy_thread in copy_process进行设定
*childregs = *current_pt_regs(); //复制内核堆栈
childregs->ax = 0; //为什么子进程的fork返回0,这里就是原因!
p->thread.sp = (unsigned long) childregs; //调度到子进程时的内核栈顶
p->thread.ip = (unsigned long) ret_from_fork; //调度到子进程时的第一条指令地址
gdb跟踪分析一个fork系统调用内核处理函数sys_clone
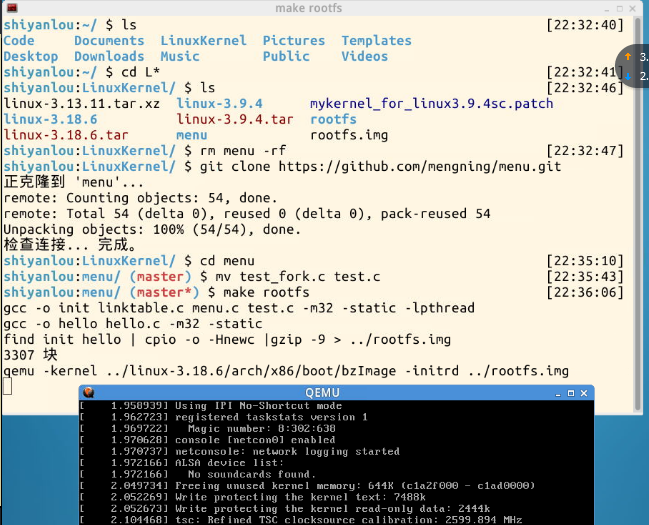


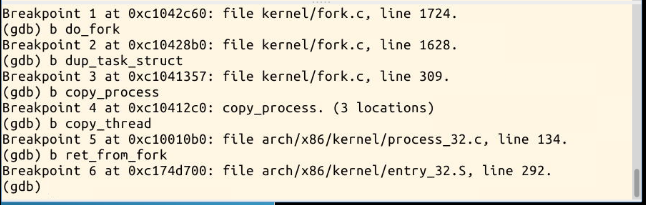


总结:关于linux系统创建一个新进程的过程,我认为它主要是通过fork()和exec()共同完成的,其中会涉及task_struct数据结构的很多信息复制移植。Linux的进程实现的优势在于对于线程的设计非常简洁,逻辑上易于处理。


