


20135202闫佳歆--week6 进程的描述与创建--学习笔记
此为个人学习笔记存档!
week 6 进程的描述与创建
一、进程的描述
1.进程控制块task_struct
以下内容来自视频课件,存档在此。
为了管理进程,内核必须对每个进程进行清晰的描述,进程描述符提供了内核所需了解的进程信息。
- struct task_struct数据结构很庞大
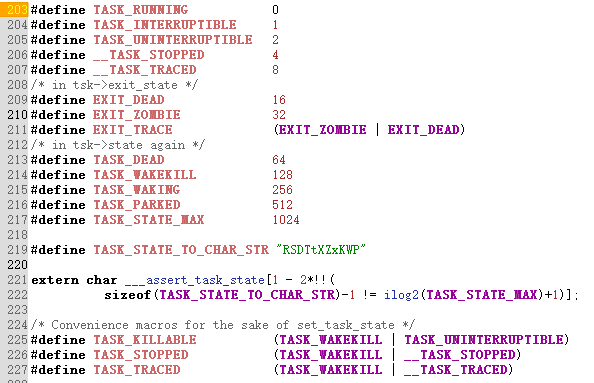
- Linux进程的状态与操作系统原理中的描述的进程状态似乎有所不同,比如就绪状态和运行状态都是TASK_RUNNING,为什么呢?
- 进程的标示pid
- 所有进程链表struct list_head tasks;
- 程序创建的进程具有父子关系,在编程时往往需要引用这样的父子关系。进程描述符中有几个域用来表示这样的关系
- Linux为每个进程分配一个8KB大小的内存区域,用于存放该进程两个不同的数据结构:Thread_info和进程的内核堆栈
- 进程处于内核态时使用,不同于用户态堆栈,即PCB中指定了内核栈,那为什么PCB中没有用户态堆栈?用户态堆栈是怎么设定的?
- 内核控制路径所用的堆栈很少,因此对栈和Thread_info来说,8KB足够了
- struct thread_struct thread; //CPU-specific state of this task
- 文件系统和文件描述符
- 内存管理——进程的地址空间
逐条分析如下节:
2.进程描述符task_struct数据结构
-
struct task_struct数据结构很庞大
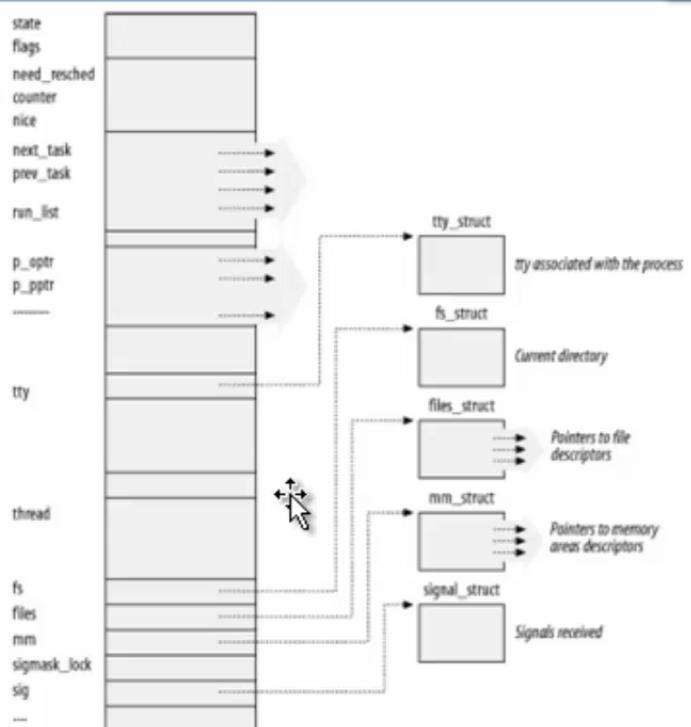
struct task_struct { volatile long state; /* 进程状态 -1 unrunnable, 0 runnable, >0 stopped */ void *stack; /* 进程的内核堆栈 */ atomic_t usage; unsigned int flags; /* 每个进程的标识符 */ unsigned int ptrace; / #ifdef CONFIG_SMP // 条件编译,SMP多处理器相关 …… int on_rq // 运行队列相关,下面几行是进程队列和调度相关。 …… struct list_head tasks // 进程链表 …… next_task prev_task // 对进程链表的管理 tty_struct // 控制台 fs_struct // 文件系统 struct files_struct *files; // 打开的文件描述符列表 file_struct // 打开的文件描述符 mm_struct // 内存管理描述 struct mm_struct *mm, *active_mm; // 地址空间,内存管理。 signal_struct // 进程间通信、信号描述 struct list_head ptraced // 调试用 utime stime // 进程时间相关
-
Linux进程的状态与操作系统原理中的描述的进程状态有所不同,比如就绪状态和运行状态都是TASK_RUNNING,为什么呢?
一般操作系统原理中描述的进程状态有就绪态,运行态,阻塞态,但是在实际内核进程管理中是不一样的。
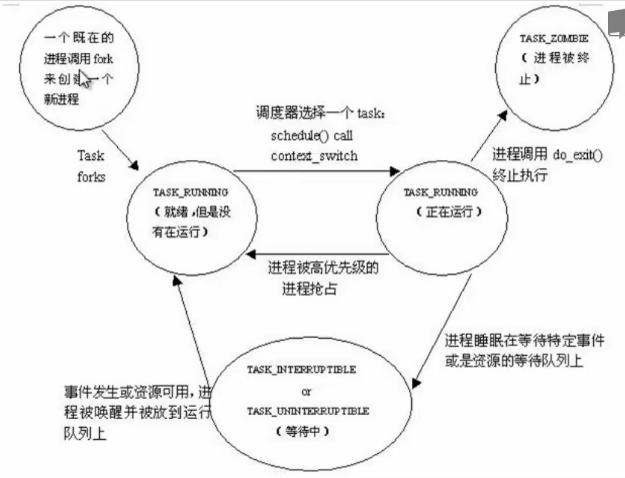
- 创建新进程后实际的状态是TASK_RUNNING,就绪但是没有运行,调度器选择一个task之后进入运行态,也叫TASK_RUNNING。
- 当进程是TASK_RUNNING时,代表这个进程是可运行的,至于它有没有真的在运行,取决于它有没有获得cpu的控制权,即有没有在cpu上实际的运行。
- 一个正在进行的进程调用do_exit(),进入TASK_ZOMBIE,进程被终止,“僵尸进程”。
- 等待特定时间或者资源的时候,进入阻塞态,如果条件满足就进入就绪态,被选择后进入运行态。
-
进程的标示pid
pid_t pid; pid_t tgid; //用来标识进程的。 -
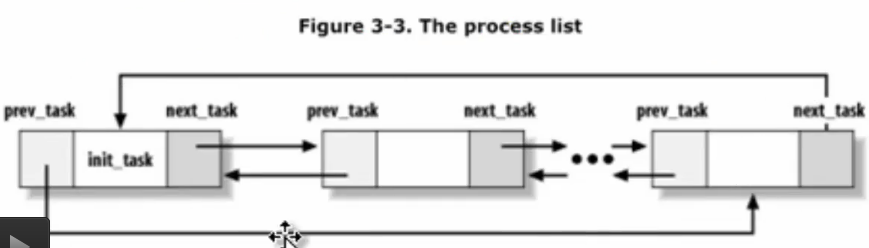
所有进程链表struct list_head tasks
为了对给定类型的进程进行有效的搜索,内核维护了几个进程链表:

二、进程的创建
1.进程的创建概览及fork一个进程的用户态代码
复习:
道生一(start_kernel....cpu_idle),一生二(kernel_init和kthreadd),二生三(即前面0、1和2三个进程),三生万物(1号进程是所有用户态进程的祖先,0号进程是所有内核线程的祖先),新内核的核心代码已经优化的相当干净,都符合中国传统文化精神了
怎样创建一个子进程?
——fork系统调用
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char * argv[])
{
int pid;
/* fork another process */
pid = fork();
if (pid < 0)
{
/* error occurred */
fprintf(stderr,"Fork Failed!");
exit(-1);
}
else if (pid == 0)
{
/* child process */
printf("This is Child Process!\n");
}
else
{
/* parent process */
printf("This is Parent Process!\n");
/* parent will wait for the child to complete*/
wait(NULL);
printf("Child Complete!\n");
}
}
fork系统调用在父进程和子进程各返回一次。
关于fork和进程创建在上学期的课程中已经学习过,在此不作赘述。
2.理解进程创建过程复杂代码的方法
复习:
系统调用,见前几周博客:
第四周学习笔记——系统调用(上)
第五周学习笔记——系统调用(下)
调用fork的过程:
父进程如下:
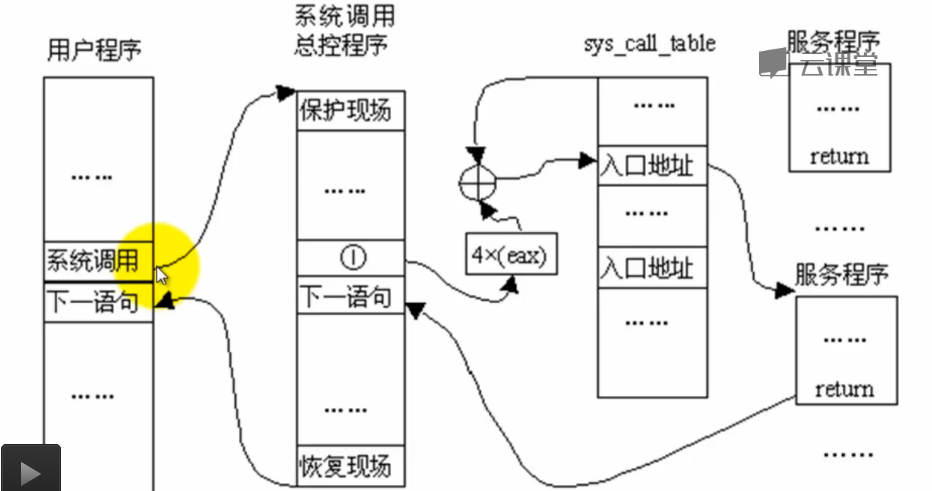
子进程呢?fork出来的子进程是从哪儿开始执行的?
用户态空间——fork的下一句
fork出的子进程在内核中返回。
内核空间?是从那一句开始执行的?
——与基于mykernel的精简内核对照起来,想象出一个框架。
以下来自课件:
创建一个新进程在内核中的执行过程
fork、vfork和clone三个系统调用都可以创建一个新进程,而且都是通过调用do_fork来实现进程的创建;
Linux通过复制父进程来创建一个新进程,那么这就给我们理解这一个过程提供一个想象的框架:
复制一个PCB——task_struct
err = arch_dup_task_struct(tsk, orig);要给新进程分配一个新的内核堆栈
ti = alloc_thread_info_node(tsk, node); tsk->stack = ti; setup_thread_stack(tsk, orig); //这里只是复制thread_info,而非复制内核堆栈要修改复制过来的进程数据,比如pid、进程链表等,见copy_process内部。
从用户态的代码看fork(): 函数返回了两次,即在父子进程中各返回一次,父进程从系统调用中返回比较容易理解,子进程从系统调用中返回,那它在系统调用处理过程中的哪里开始执行的呢?这就涉及子进程的内核堆栈数据状态和task_struct中thread记录的sp和ip的一致性问题,这是在哪里设定的?copy_thread
in copy_process*childregs = *current_pt_regs(); //复制内核堆栈 childregs->ax = 0; //为什么子进程的fork返回0,这里就是原因! p->thread.sp = (unsigned long) childregs; //调度到子进程时的内核栈顶 p->thread.ip = (unsigned long) ret_from_fork; //调度到子进程时的第一条指令地址
系统调用内核处理函数sys_fork,sys_vfrok,sys_clone,其实最终执行的都是do_fork。
do_fork里有:
copy_process
里面有:
dup_task_struct // 复制pcb
alloc_thread_info_node // 创建了一个页面,其实就是实际分配内核堆栈空间的效果。
setup_thread_stack // 把thread_info的东西复制过来
然后是大量的修改内容,将子进程初始化。
※copy_thread
copy_thread时都做了什么?
堆栈相关的一些内容
当前进程(父进程)的内核堆栈的栈底拷贝过来
赋值ip,sp……
3.创建的新进程是从哪里开始执行的
*childregs = *current_pt_regs(); //复制内核堆栈
childregs->ax = 0; //为什么子进程的fork返回0,这里就是原因!
p->thread.sp = (unsigned long) childregs; //调度到子进程时的内核栈顶
p->thread.ip = (unsigned long) ret_from_fork; //调度到子进程时的第一条指令地址
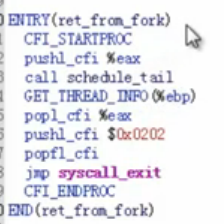
ip指向的是ret_from_fork,所以是从这里开始执行的。
复制内核堆栈的时候是复制的pt_regs,即只复制了SAVE_ALL相关的那一部分,即系统调用压栈的那一部分。
pt_regs里面内容有:

Entry(ret_from_fork):
最终会跳转到syscall_exit,这之前的内核堆栈状态和syscall_call的一致,然后返回用户态,变成子进程的用户态。
4.使用gdb跟踪创建新进程的过程
在MenuOs中新加了fork的命令。
准备工作:
rm menu -rf
git clone http://github.com/mengning/menu.git # 更新Menu
cd menu
mv test_fork.c test.c # 把test.c覆盖掉
make rootfs
执行fork,可以看到父进程子进程都输出了信息。
下面进行gdb调试:
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s -S
gdb
file linux-3.18.6/vmlinux
target remote:1234
// 设置断点
b sys_clone # 因为fork实际上是执行的clone
b do_fork
b dup_task_struct
b copy_process
b copy_thread
b ret_from_fork
c
n
……
可以看到一系列相关函数:
tsk->stack = ti; //把内核堆栈的地址赋给它
//把内核堆栈压栈的空间地址找到,初始化
sturct pt_regs *childregs = task_pg_regs(p);
//把当前进程的内核堆栈的压的寄存器赋值到子进程中来。
*childregs = *current_pt_regs();
childregs->ax = 0;
//设置子进程被调度的ip,即子进程的起点
p->thread.ip = (unsigned long) ret_from_fork;
jmp syscall_exit; //这之后就跟踪不到了。

