



Lucene搜索引擎+HDFS+MR完成垂直搜索
介于上一篇的java实现网络爬虫基础之上,这一篇的思想是将网络收集的数据保存到HDFS和数据库(Mysql)中;然后用MR对HDFS的数据进行索引处理,处理成倒排索引;搜索时先用HDFS建立好的索引来搜索对应的数据ID,根据ID从数据库中提取数据,呈现到网页上。
这是一个完整的集合网络爬虫、数据库、HDFS、MapReduce、DAO设计模式、JSP/Servlet的项目,完成了数据收集、数据分析、数据索引并分页呈现。
完整的代码呈现,希望认真仔细阅读。
------>
目录:
1、搜索引擎阐述
2、数据库表建立
3、使用DAO设计模式进行数据库操作
【Ⅰ】数据库连接类DataBaseConnection
【Ⅱ】表单元素的封装类News
【Ⅲ】编写DAO接口INewsDAO
【Ⅳ】DAO接口的实现类NewsDAOImp类
【Ⅴ】工厂类DAOFactory类
4、网络爬虫实现★★ 【参考博客《java实现网络爬虫》和《Heritrix实现网络爬虫》】
5、MR(MapReduce)对HDFS数据进行索引处理★★
6、实现搜索引擎
【Ⅰ】创建web项目,编写测试用例,测试是否可以读取HDFS的数据内容
【Ⅱ】 编写index首页
【Ⅲ】处理HDFS查询的操作
【Ⅳ】servlet类搜索结果向页面传递
【Ⅴ】结果呈现,实现分页
7、总结
------>
1、搜索引擎阐述
搜索引擎的执行流程:
1) 通过爬虫来将数据下载到本地
2) 将数据提取出来保存到HDFS和数据库中(MySQL)
3) 通过MR来对HDFS的数据进行索引处理,处理成为倒排索引
4) 搜索时先使用HDFS建立好的索引来搜索对应的数据ID,再根据ID来从MySQL数据库中提取数据的具体信息。
5) 可以完成分页等操作。
倒排索引对应的就是正排索引,正排索引指的就是MySQL数据库中id的索引。
而倒排索引的目的是可以根据关键字查询出该关键字对应的数据id。
这里就需要用到MySQL数据库,以及通过Java EE版的Eclipse来完成网站的开发。
为了开发起来更方便,我们这里使用MyEclipse来完成。
2、数据库表建立
先安装好MySQL数据库。

安装时,注意编码选择gbk。
通过控制台的mysql -u用户名 –p密码 即可登录mysql数据库。
之后使用show databases可以看到所有的数据库。
使用create database 可以建立一个新的库。
使用 use 库名 ,可以切换到另一个库。
使用show tables可以看到一个库下的所有表。
之后就可以通过普通的sql语句来建立表和进行数据的操作了。
在进行数据库操作时,企业开发中必定要使用DAO(Data Access Object)设计模式
组成如下:
1) DataBaseConnection:建立数据库连接
2) VO:与表对应的数据对象
3) DAO接口:规范操作方法
4) DAOImpl:针对DAO接口进行方法实现。
5) Factory:用来建立DAO接口对象。
首先根据需求,将数据库表建立出来,这里只需建立一个简单的news新闻表,用于存储网络上爬取得数据。
1 CREATE TABLE news ( 2 id int primary key , 3 title varchar(200) not null, 4 description text , 5 url varchar(200) 6 );
3、使用DAO设计模式进行数据库操作
根据上述的DAO设计模式,我们需要编写相关操作类,来完成数据库的操作。
【Ⅰ】 数据库连接类DataBaseConnection,需要导入jar包 :
:
1 package org.liky.sina.dbc; 2 3 import java.sql.Connection; 4 import java.sql.DriverManager; 5 import java.sql.SQLException; 6 7 /** 8 * 连接数据库mysql的sina_news 9 * @author k04 10 * 11 */ 12 public class DataBaseConnection {
//此处可以试着两种表达加载类的方法 13 // private static final String DBORIVER="org.git.mm.mysql.Driver"; 14 private static final String DBORIVER="com.mysql.jdbc.Driver"; 15 private static final String DBURL="jdbc:mysql://localhost:3306/sina_news"; 16 private static final String DBUSER="root"; 17 private static final String DBPASSWORD="admin"; 18 19 private Connection conn; 20 /** 21 * 创建数据库连接 22 * @return 23 */ 24 public Connection getConnection(){ 25 try { 26 if(conn==null||conn.isClosed()){ 27 //建立一个新的连接 28 Class.forName(DBORIVER); 29 conn=DriverManager.getConnection(DBURL, DBUSER, DBPASSWORD); 30 //System.out.println("success to connect!"); 31 } 32 }catch (ClassNotFoundException e) { 33 // TODO Auto-generated catch block 34 e.printStackTrace(); 35 } catch (SQLException e) { 36 // TODO Auto-generated catch block 37 e.printStackTrace(); 38 } 39 return conn; 40 } 41 /* 42 * 关闭连接 43 */ 44 public void close(){ 45 if(conn!=null){ 46 try{ 47 conn.close(); 48 }catch(SQLException e){ 49 e.printStackTrace(); 50 } 51 } 52 } 53 54 }
【Ⅱ】表单元素的封装类News,根据建表时设定的四种元素id,title,description,url,将网络爬取得内容完整的导入数据库中,此处可以用shift+Alt+S在Eclipse快捷创建封装类:
1 package org.liky.sina.vo; 2 /** 3 * news封装类 4 * @author k04 5 * 6 */ 7 public class News { 8 private Integer id; 9 private String title; 10 private String description; 11 private String url; 12 13 14 public News() { 15 } 16 public News(Integer id,String title,String description,String url) { 17 this.id=id; 18 this.title=title; 19 this.description=description; 20 this.url=url; 21 } 22 23 24 public Integer getId() { 25 return id; 26 } 27 public void setId(Integer id) { 28 this.id = id; 29 } 30 public String getTitle() { 31 return title; 32 } 33 public void setTitle(String title) { 34 this.title = title; 35 } 36 public String getDescription() { 37 return description; 38 } 39 public void setDescription(String description) { 40 this.description = description; 41 } 42 public String getUrl() { 43 return url; 44 } 45 public void setUrl(String url) { 46 this.url = url; 47 } 48 }
【Ⅲ】编写DAO接口INewsDAO,存放数据库操作类的方法名:
1 package org.liky.sina.dao; 2 /** 3 * 接口,呈现三个方法 4 */ 5 import java.util.List; 6 import org.liky.sina.vo.News; 7 8 public interface INewsDAO { 9 /** 10 * 添加数据 11 * @param news 要添加的对象 12 * @throws Exception 13 */ 14 public void doCreate(News news)throws Exception; 15 /** 16 * 根据主键id查询数据 17 * 18 */ 19 public News findById(int id)throws Exception; 20 /** 21 * 根据一组id查询所有结果 22 * @param ids 所有要查询的id 23 * @return 查询到的数据 24 * 因为索引是根据热词查到一堆的id 25 */ 26 public List<News> findByIds(int[] ids)throws Exception; 27 28 }
【Ⅳ】DAO接口的实现类NewsDAOImp类:
1 package org.liky.sina.dao.impl; 2 /** 3 * 继承INewsDAO接口 4 * 实现三个方法,插入数据,查找指定id数据,查找一组id数据 5 */ 6 import java.sql.PreparedStatement; 7 import java.sql.ResultSet; 8 import java.util.ArrayList; 9 import java.util.List; 10 11 import org.liky.sina.dao.INewsDAO; 12 import org.liky.sina.dbc.DataBaseConnection; 13 import org.liky.sina.vo.News; 14 15 public class NewsDAOImpl implements INewsDAO { 16 //声明一个数据库连接类对象 17 private DataBaseConnection dbc; 18 19 20 //构造器,参数为数据库连接类对象 21 public NewsDAOImpl(DataBaseConnection dbc) { 22 this.dbc=dbc; 23 24 } 25 26 @Override 27 public void doCreate(News news) throws Exception { 28 // TODO Auto-generated method stub 29 String sql="INSERT INTO news (id,title,description,url) VALUES (?,?,?,?)"; 30 PreparedStatement pst=dbc.getConnection().prepareStatement(sql); 31 //设置参数 32 pst.setInt(1, news.getId()); 33 pst.setString(2, news.getTitle()); 34 pst.setString(3, news.getDescription()); 35 pst.setString(4, news.getUrl()); 36 37 pst.executeUpdate(); 38 System.out.println("create success."); 39 } 40 41 @Override 42 public News findById(int id) throws Exception { 43 // TODO Auto-generated method stub 44 String sql="SELECT id,title,description,url FROM news WHERE id = ?"; 45 PreparedStatement pst=dbc.getConnection().prepareStatement(sql); 46 pst.setInt(1, id); 47 ResultSet rs=pst.executeQuery(); 48 News news=null; 49 //将符合id的数据遍历写入news并返回 50 if(rs.next()){ 51 news=new News(); 52 news.setId(rs.getInt(1)); 53 news.setTitle(rs.getString(2)); 54 news.setDescription(rs.getString(3)); 55 news.setUrl(rs.getString(4)); 56 } 57 //System.out.println("find success."); 58 return news; 59 } 60 61 @Override 62 public List<News> findByIds(int[] ids) throws Exception { 63 // TODO Auto-generated method stub 64 StringBuilder sql=new StringBuilder("SELECT id,title,description,url FROM news WHERE id IN ("); 65 //将id写入ids,并用逗号隔开 66 if(ids!=null&&ids.length>0){ 67 for(int id:ids){ 68 sql.append(id); 69 sql.append(","); 70 } 71 //截取最后一个逗号,并补上括号 72 String resultSQL=sql.substring(0, sql.length()-1)+")"; 73 74 PreparedStatement pst=dbc.getConnection().prepareStatement(resultSQL); 75 ResultSet rs=pst.executeQuery(); 76 //存取一组id到链表中 77 List<News> list=new ArrayList<>(); 78 while(rs.next()){ 79 News news=new News(); 80 news.setId(rs.getInt(1)); 81 news.setTitle(rs.getString(2)); 82 news.setDescription(rs.getString(3)); 83 news.setUrl(rs.getString(4)); 84 list.add(news); 85 } 86 } 87 //System.out.println("find success."); 88 return null; 89 } 90 91 }
【Ⅴ】工厂类DAOFactory类,此类写入了数据库连接类参数,返回DAO实现类对象:
java中,我们通常有以下几种创建对象的方式:
(1) 使用new关键字直接创建对象;
(2) 通过反射机制创建对象;
(3) 通过clone()方法创建对象;
(4) 通过工厂类创建对象。
1 package org.liky.sina.factory; 2 /** 3 * 工厂类 4 * 输入一个连接数据库对象的参数,返回数据库表操作的类 5 */ 6 import org.liky.sina.dao.INewsDAO; 7 import org.liky.sina.dao.impl.NewsDAOImpl; 8 import org.liky.sina.dbc.DataBaseConnection; 9 10 public class DAOFactory { 11 public static INewsDAO getINewsDAOInstance(DataBaseConnection dbc){ 12 return new NewsDAOImpl(dbc); 13 } 14 }
4、网络爬虫实现
现在编写整个项目的重点,编写URLDemo类,在爬虫中进行数据库的操作以及HDFS的写入:
a' 关于此类,在网页解析时用了简单的Jsoup,并没有如《java网络爬虫》用正则表达式,所以需要导入jsoup的jar包  ;
;
b' 关于HDFS在eclipse的配置以及本机的连接,我后续博客会阐述,也可以网络查询方法;
c' 这个类也是执行类,我收集的是新浪新闻网的数据,爬取深度为5,设置线程数5,并且筛选了只有链接含有“sian.news.com.cn”的。
d' 网络爬虫我讲了两种方法:(1)java代码实现网络爬虫
(2)Heritrix工具实现网络爬虫
此处我还是选择了直接写代码实现,自由度高也方便读写存取。
1 package org.liky.sina.craw; 2 3 import java.util.ArrayList; 4 import java.util.HashMap; 5 import java.util.HashSet; 6 import java.util.List; 7 import java.util.Map; 8 import java.util.Set; 9 10 import org.apache.hadoop.conf.Configuration; 11 import org.apache.hadoop.fs.FSDataOutputStream; 12 import org.apache.hadoop.fs.FileSystem; 13 import org.apache.hadoop.fs.Path; 14 import org.jsoup.Jsoup; 15 import org.jsoup.nodes.Document; 16 import org.jsoup.nodes.Element; 17 import org.jsoup.select.Elements; 18 import org.liky.sina.dao.INewsDAO; 19 import org.liky.sina.dbc.DataBaseConnection; 20 import org.liky.sina.factory.DAOFactory; 21 import org.liky.sina.vo.News; 22 23 /** 24 * 爬虫开始进行数据库操作以及HDFS写入 25 * 26 * @author k04 27 * 28 */ 29 public class URLDemo { 30 // 该对象的构造方法会默认加载hadoop中的两个配置文件,hdfs-site.xml和core-site.xml 31 // 这两个文件包含访问hdfs所需的参数值 32 private static Configuration conf = new Configuration(); 33 34 private static int id = 1; 35 36 private static FileSystem fs; 37 38 private static Path path; 39 40 // 等待爬取的url 41 private static List<String> allWaitUrl = new ArrayList<>(); 42 // 已经爬取的url 43 private static Set<String> allOverUrl = new HashSet<>(); 44 // 记录所有url的深度,以便在addUrl方法内判断 45 private static Map<String, Integer> allUrlDepth = new HashMap<>(); 46 // 爬取网页的深度 47 private static int maxDepth = 5; 48 // 声明object独享帮助进行线程的等待操作 49 private static Object obj = new Object(); 50 // 设置总线程数 51 private static final int MAX_THREAD = 20; 52 // 记录空闲的线程数 53 private static int count = 0; 54 55 // 声明INewsDAO对象, 56 private static INewsDAO dao; 57 58 static { 59 dao = DAOFactory.getINewsDAOInstance(new DataBaseConnection()); 60 } 61 62 public static void main(String args[]) { 63 // 爬取的目标网址 64 String strUrl = "http://news.sina.com.cn/"; 65 66 // 爬取第一个输入的url 67 addUrl(strUrl, 0); 68 // 建立多个线程 69 for (int i = 0; i < MAX_THREAD; i++) { 70 new URLDemo().new MyThread().start(); 71 } 72 73 // DataBaseConnection dc=new DataBaseConnection(); 74 // dc.getConnection(); 75 76 } 77 78 public static void parseUrl(String strUrl, int depth) { 79 // 先判断当前url是否爬取过 80 // 判断深度是否符合要求 81 if (!(allOverUrl.contains(strUrl) || depth > maxDepth)) { 82 System.out.println("当前执行的 " + Thread.currentThread().getName() 83 + " 爬虫线程处理爬取: " + strUrl); 84 85 try { 86 // 用jsoup进行数据爬取 87 Document doc = Jsoup.connect(strUrl).get(); 88 // 通过doc接受返回的结果 89 // 提取有效的title和description 90 String title = doc.title(); 91 Element descE = doc.getElementsByAttributeValue("name", 92 "description").first(); 93 String desc = descE.attr("content"); 94 95 // System.out.println(title + " --> " + desc); 96 97 // 如果有效,则惊醒保存 98 if (title != null && desc != null && !title.trim().equals("") 99 && !desc.trim().equals("")) { 100 // 需要生成一个id,以便放入数据库中,因此id也要加入到HDFS中,便于后续索引 101 News news = new News(); 102 news.setId(id++); 103 news.setTitle(title); 104 news.setDescription(desc); 105 news.setUrl(strUrl); 106 // 添加到数据库语句 107 dao.doCreate(news); 108 // 向HDFS保存数据 109 path = new Path("hdfs://localhost:9000/sina_news_input/" 110 + System.currentTimeMillis() + ".txt"); 111 fs = path.getFileSystem(conf); 112 FSDataOutputStream os = fs.create(path); 113 // 进行内容输出,此处需要用news.getId(),不然数据库和HDFS的id会不相同,因为多线程的运行 114 os.writeUTF(news.getId() + "\r\n" + title + "\r\n" + desc); 115 os.close(); 116 117 // 解析所有超链接 118 Elements aEs = doc.getElementsByTag("a"); 119 // System.out.println(aEs); 120 if (aEs != null && aEs.size() > 0) { 121 for (Element aE : aEs) { 122 String href = aE.attr("href"); 123 System.out.println(href); 124 // 截取网址,并给出筛选条件!!! 125 if ((href.startsWith("http:") || href 126 .startsWith("https:")) 127 && href.contains("news.sina.com.cn")) { 128 // 调用addUrl()方法 129 addUrl(href, depth + 1); 130 } 131 } 132 } 133 134 } 135 136 } catch (Exception e) { 137 138 } 139 // 吧当前爬完的url放入到偶尔中 140 allOverUrl.add(strUrl); 141 System.out.println(strUrl + "爬去完成,已经爬取的内容量为:" + allOverUrl.size() 142 + "剩余爬取量为:" + allWaitUrl.size()); 143 144 // 判断是否集合中海油其他的内容需要进行爬取,如果有,则进行线程的唤醒 145 if (allWaitUrl.size() > 0) { 146 synchronized (obj) { 147 obj.notify(); 148 } 149 } else { 150 System.out.println("爬取结束..."); 151 System.exit(0); 152 } 153 154 } 155 } 156 157 /** 158 * url加入到等待队列中 并判断是否已经放过,若没有就放入allUrlDepth中 159 * 160 * @param href 161 * @param depth 162 */ 163 public static synchronized void addUrl(String href, int depth) { 164 // 将url放入队列中 165 allWaitUrl.add(href); 166 // 判断url是否已经存在 167 if (!allUrlDepth.containsKey(href)) { 168 allUrlDepth.put(href, depth + 1); 169 } 170 } 171 172 /** 173 * 获取等待队列下一个url,并从等待队列中移除 174 * 175 * @return 176 */ 177 public static synchronized String getUrl() { 178 if (allWaitUrl.size() > 0) { 179 String nextUrl = allWaitUrl.get(0); 180 allWaitUrl.remove(0); 181 return nextUrl; 182 } 183 return null; 184 } 185 186 /** 187 * 用多线程进行url爬取 188 * 189 * @author k04 190 * 191 */ 192 public class MyThread extends Thread { 193 194 @Override 195 public void run() { 196 // 编写一个死循环,以便线程可以一直存在 197 while (true) { 198 // 199 200 String url = getUrl(); 201 if (url != null) { 202 // 调用该方法爬取url的数据 203 parseUrl(url, allUrlDepth.get(url)); 204 } else { 205 System.out.println("当前线程准备就绪,等待连接爬取:" + this.getName()); 206 // 线程+1 207 count++; 208 // 建立一个对象,帮助线程进入等待状态wait() 209 synchronized (obj) { 210 try { 211 obj.wait(); 212 } catch (Exception e) { 213 e.printStackTrace(); 214 } 215 // 线程-1 216 count--; 217 } 218 } 219 } 220 } 221 222 } 223 224 }
现在执行上述类URLDemo,该类执行流程:
1‘ 读取源链接,分配线程任务;
2’ 数据根据DAO设计模式写入到数据库中;
3‘ 数据上传到HDFS的input文件夹中;
执行完可以查看HDFS和数据库的结果:

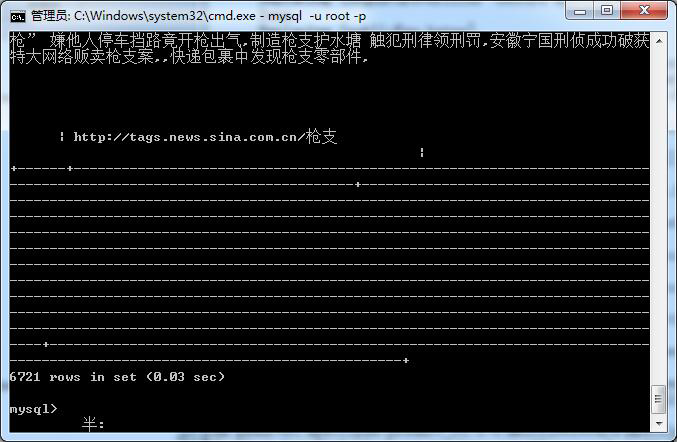
关于此处,还是有些许瑕疵,双方的数据量并不相等,主要是多线程爬取的时候,id的传输并不相同!
将重复的数据进行清洗,
当数据爬取完成后,我们会发现有很多重复的数据,这可以通过SQL语句来进行清洗的操作。
SQL中可以使用group by关键字来完成分组函数的处理。
我们可以先通过该函数来测试一下。
测试后会发现真正有效数据量应该是4634条。
这就需要我们通过建立一张新表,把所有不重复的数据加入到新表中。
mysql支持create table时通过select语句来查询出一些结果作为新表的结构和数据。
CREATE TABLE new_news SELECT id,title,description,url FROM news WHERE id IN (SELECT min(id) FROM news GROUP BY title)
5、MR(MapReduce)对HDFS数据进行索引处理
下面就可以开始编写MR程序。
Map格式,要求key为关键字,value为id。
由于一个关键字可能会对应多个id,所以id之间我们想使用,来分隔。所以key和value的类型都应该是String(Text)
1 package org.liky.sina.index; 2 /** 3 * 编写MR程序。 4 Map格式,要求key为关键字,value为id。 5 由于一个关键字可能会对应多个id,所以id之间我们想使用,来分隔。所以key和value的类型都应该是String(Text) 6 */ 7 import java.io.IOException; 8 import java.util.*; 9 import java.util.regex.*; 10 import jeasy.analysis.MMAnalyzer; 11 import org.apache.hadoop.conf.*; 12 import org.apache.hadoop.fs.Path; 13 import org.apache.hadoop.io.*; 14 import org.apache.hadoop.mapred.*; 15 import org.apache.hadoop.util.*; 16 17 18 public class IndexCreater extends Configured implements Tool { 19 20 public static void main(String[] args) throws Exception { 21 int res = ToolRunner.run(new Configuration(), new IndexCreater(), 22 new String[] { "hdfs://localhost:9000/sina_news_input/", 23 "hdfs://localhost:9000/output_news_map/" }); 24 System.exit(res); 25 } 26 27 28 29 //Mapper接口中的后两个泛型参数,第一个表示返回后Map的key的类型,第二个表示返回后的value类型 30 public static class MapClass extends MapReduceBase implements Mapper<LongWritable,Text,Text,Text>{ 31 32 private static Pattern p; 33 34 static{ 35 System.out.println("开始Map操作....."); 36 p=Pattern.compile("\\d+"); 37 } 38 39 private int id; 40 private int line=1; 41 42 private static MMAnalyzer mm=new MMAnalyzer(); 43 44 //输出的词 45 private Text word=new Text(); 46 47 //map过程的核心方法 48 @Override 49 public void map(LongWritable key, Text value, 50 OutputCollector<Text, Text> output, Reporter reporter) 51 throws IOException { 52 if (line == 1) { 53 // 读取的是第一行,我们就需要将第一行的id保留下来 54 line++; 55 Matcher m = p.matcher(value.toString()); 56 if (m.find()) { 57 id = Integer.parseInt(m.group()); 58 } 59 } else { 60 String tempStr = value.toString(); 61 // 按空格将单词拆分出来 62 // StringTokenizer itr = new StringTokenizer(line); 63 // 使用分词器来进行词组的拆分 64 String[] results = mm.segment(tempStr, "|").split("\\|"); 65 // 每个单词记录出现了1次 66 for (String temp : results) { 67 word.set(temp.toLowerCase()); 68 output.collect(word, new Text(id + "")); 69 } 70 } 71 72 } 73 74 75 76 77 } 78 79 80 //对所有的结果进行规约,合并 81 //Reducer中也有泛型,前两个表示Map过程输出的结果类型,后两个表示Reduce处理后输出的类型 82 public static class Reduce extends MapReduceBase implements Reducer<Text,Text,Text,Text>{ 83 84 static{ 85 System.out.println("开始reduce操作....."); 86 } 87 @Override 88 public void reduce(Text key, Iterator<Text> values, 89 OutputCollector<Text, Text> output, Reporter repoter) 90 throws IOException { 91 //将所有key值相同的结果,求和 92 StringBuilder result=new StringBuilder(); 93 while(values.hasNext()){ 94 //存在一个key相同的,加入result 95 String temp=values.next().toString(); 96 if(!result.toString().contains(temp+",")){ 97 result.append(temp+","); 98 } 99 100 } 101 //将其规约 102 output.collect(key, new Text(result.substring(0, result.length()-1))); 103 //输出key相同的id值 104 System.out.println(key+"---->"+result); 105 } 106 107 108 109 } 110 111 static int printUsage() { 112 System.out 113 .println("wordcount [-m <maps>] [-r <reduces>] <input> <output>"); 114 ToolRunner.printGenericCommandUsage(System.out); 115 return -1; 116 } 117 118 119 @Override 120 public int run(String[] args) throws Exception { 121 // TODO Auto-generated method stub 122 JobConf conf = new JobConf(getConf(), IndexCreater.class); 123 conf.setJobName("wordcount"); 124 125 // 输出结果的Map的key值类型 126 conf.setOutputKeyClass(Text.class); 127 // 输出结果的Map的value值类型 128 conf.setOutputValueClass(Text.class); 129 130 conf.setMapperClass(MapClass.class); 131 conf.setCombinerClass(Reduce.class); 132 conf.setReducerClass(Reduce.class); 133 134 List<String> other_args = new ArrayList<String>(); 135 for (int i = 0; i < args.length; ++i) { 136 try { 137 if ("-m".equals(args[i])) { 138 conf.setNumMapTasks(Integer.parseInt(args[++i])); 139 } else if ("-r".equals(args[i])) { 140 conf.setNumReduceTasks(Integer.parseInt(args[++i])); 141 } else { 142 other_args.add(args[i]); 143 } 144 } catch (NumberFormatException except) { 145 System.out.println("ERROR: Integer expected instead of " 146 + args[i]); 147 return printUsage(); 148 } catch (ArrayIndexOutOfBoundsException except) { 149 System.out.println("ERROR: Required parameter missing from " 150 + args[i - 1]); 151 return printUsage(); 152 } 153 } 154 // Make sure there are exactly 2 parameters left. 155 if (other_args.size() != 2) { 156 System.out.println("ERROR: Wrong number of parameters: " 157 + other_args.size() + " instead of 2."); 158 return printUsage(); 159 } 160 // 设置输出结果按照什么格式保存,以便后续使用。 161 conf.setOutputFormat(MapFileOutputFormat.class); 162 // 输入文件的HDFS路径 163 FileInputFormat.setInputPaths(conf, other_args.get(0)); 164 // 输出结果的HDFS路径 165 FileOutputFormat.setOutputPath(conf, new Path(other_args.get(1))); 166 167 JobClient.runJob(conf); 168 169 return 0; 170 } 171 172 }
6、实现搜索引擎
【Ⅰ】创建web项目,编写测试用例,测试是否可以读取HDFS的数据内容
在安装好的MyEclipse开发工具中,开始编写搜索引擎展示部分的内容。
这里先使用普通的JSP + Servlet的模式来完成程序的编写。
首先建立一个普通的Web项目。
之后,在里面编写一个测试用例,测试是否可以读取HDFS中的数据内容,注意需要先将hadoop/lib目录下的所有jar包,以及hadoop根目录下的支持jar包拷贝到项目WEB-INF目录下的lib目录中。
注意!!!完成上面数据的收集和分析之后,现在读取的内容需要从经过MR处理之后存储在HDFS的sina_new_ouputwenjianjia内读取。
1 package org.liky.sina.test; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.fs.FileSystem; 5 import org.apache.hadoop.fs.Path; 6 import org.apache.hadoop.io.MapFile.Reader; 7 import org.apache.hadoop.io.Text; 8 import org.apache.hadoop.mapred.MapFileOutputFormat; 9 import org.junit.Test; 10 11 public class TestCaseSina { 12 13 @Test 14 public void test() throws Exception { 15 Configuration conf = new Configuration(); 16 Path path = new Path("hdfs://localhost:9000/output_news_map/"); 17 FileSystem fs = path.getFileSystem(conf); 18 Reader reader = MapFileOutputFormat.getReaders(fs, path, conf)[0]; 19 Text value = (Text) reader.get(new Text("印度"), new Text()); 20 21 System.out.println(value); 22 23 } 24 }
【Ⅱ】 编写index首页
将之前写好的DAO代码也拷贝到项目中,以便以后查询数据库使用。
之后编写一个jsp页面,用来接收用户输入的查询关键字。
此处我就从简了 O(∩_∩)O
1 <body> 2 <center> 3 <form action="SearchServlet" method="post"> 4 请输入查询关键字: 5 <input type="text" name="keyword"> 6 <input type="submit" value="查询"> 7 </form> 8 </center> 9 </body>
【Ⅲ】处理HDFS查询的操作
根据设置好的路径,建立一个SearchServlet,并完成doGet和 doPost方法。
在这个Servlet中会用到处理HDFS查询的操作方法,因此我们需要单独声明一个HDFSUtils工具类,来帮助我们实现查询的功能。
1 package org.liky.sina.utils; 2 3 import java.io.IOException; 4 import java.util.Set; 5 import java.util.TreeSet; 6 7 import org.apache.hadoop.conf.Configuration; 8 import org.apache.hadoop.fs.FileSystem; 9 import org.apache.hadoop.fs.Path; 10 import org.apache.hadoop.io.MapFile.Reader; 11 import org.apache.hadoop.io.Text; 12 import org.apache.hadoop.mapred.MapFileOutputFormat; 13 14 public class HDFSUtils { 15 //连接hadoop的配置 16 private static Configuration conf = new Configuration(); 17 //创建需要读取数据的hdfs路径 18 private static Path path = new Path( 19 "hdfs://localhost:9000/output_news_map/"); 20 21 private static FileSystem fs = null; 22 23 static { 24 try { 25 fs = path.getFileSystem(conf); 26 } catch (IOException e) { 27 e.printStackTrace(); 28 } 29 } 30 31 public static Integer[] getIdsByKeyword(String keyword) throws Exception { 32 33 Reader reader = MapFileOutputFormat.getReaders(fs, path, conf)[0]; 34 Text value = (Text) reader.get(new Text(keyword), new Text()); 35 //set存放关键词搜索的一组id 36 Set<Integer> set = new TreeSet<Integer>(); 37 String[] strs = value.toString().split(","); 38 39 for (String str : strs) { 40 set.add(Integer.parseInt(str)); 41 } 42 43 return set.toArray(new Integer[0]); 44 } 45 46 }
【Ⅳ】servlet类搜索结果向页面传递
在Servlet中通过调用HDFSUtils和之前写过的DAO方法,即可查询到结果并设置向页面传递。
此处将关键词搜索的结果呈现到result.jsp界面,所以下面就是编写该界面呈现最终结果。
1 package org.liky.sina.servlet; 2 3 import java.io.IOException; 4 import java.util.List; 5 6 import javax.servlet.ServletException; 7 import javax.servlet.http.HttpServlet; 8 import javax.servlet.http.HttpServletRequest; 9 import javax.servlet.http.HttpServletResponse; 10 11 import org.liky.sina.dbc.DataBaseConnection; 12 import org.liky.sina.factory.DAOFactory; 13 import org.liky.sina.utils.HDFSUtils; 14 import org.liky.sina.vo.News; 15 16 public class SearchServlet extends HttpServlet { 17 18 public void doGet(HttpServletRequest request, HttpServletResponse response) 19 throws ServletException, IOException { 20 this.doPost(request, response); 21 } 22 23 public void doPost(HttpServletRequest request, HttpServletResponse response) 24 throws ServletException, IOException { 25 // 接收提交的查询关键字参数 26 // 先处理乱码 27 request.setCharacterEncoding("UTF-8"); 28 // 接收参数 29 String keyword = request.getParameter("keyword"); 30 // 根据关键字进行查询。 31 try { 32 Integer[] ids = HDFSUtils.getIdsByKeyword(keyword); 33 // 根据这些id来查询出相应的结果 34 List<News> allNews = DAOFactory.getINewsDAOInstance( 35 new DataBaseConnection()).findByIds(ids); 36 37 // 将结果传递回页面显示 38 request.setAttribute("allNews", allNews); 39 40 // 切换到页面上 41 request.getRequestDispatcher("/result.jsp").forward(request, 42 response); 43 } catch (Exception e) { 44 e.printStackTrace(); 45 } 46 47 } 48 }
【Ⅴ】结果呈现,实现分页
最后,我们需要在页面上将结果呈现出来,在web根目录下编写result.jsp文件。
可以通过JSTL + EL来完成内容的输出。
1 <%@page import="org.liky.sina.vo.News"%> 2 <%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%> 3 <% 4 String path = request.getContextPath(); 5 String basePath = request.getScheme() + "://" 6 + request.getServerName() + ":" + request.getServerPort() 7 + path + "/"; 8 %> 9 10 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> 11 <html> 12 <head> 13 <base href="<%=basePath%>"> 14 15 <title>新浪新闻搜索</title> 16 </head> 17 18 <body> 19 <center> 20 <% 21 List<News> allNews = (List<News>)request.getAttribute("allNews"); 22 %> 23 <table width="80%"> 24 <% 25 for (News n : allNews) { 26 27 %> 28 <tr> 29 <td> 30 <a href="<%=n.getUrl() %>" target="_blank"><%=n.getTitle() %></a> <br> 31 <%=n.getDescription() %> 32 <hr/> 33 </td> 34 </tr> 35 <% 36 } 37 38 %> 39 </table> 40 41 <% 42 int cp = (Integer)request.getAttribute("currentPage"); 43 int allPages = (Integer)request.getAttribute("allPages"); 44 %> 45 <form id="split_page_form" action="SearchServlet" method="post"> 46 <input type="hidden" name="currentPage" id="cp" value="<%=cp %>" /> 47 <input type="button" <%=cp == 1?"disabled":"" %> value="首页" onclick="changeCp(1);"> 48 <input type="button" <%=cp == 1?"disabled":"" %> value="上一页" onclick="changeCp(<%=cp - 1 %>);"> 49 <input type="button" <%=cp == allPages?"disabled":"" %> value="下一页" onclick="changeCp(<%=cp + 1 %>);"> 50 <input type="button" <%=cp == allPages?"disabled":"" %> value="尾页" onclick="changeCp(<%=allPages %>);"> 51 第 <%=cp %> 页 / 共 <%=allPages %> 页 52 <br> 53 请输入查询关键字:<input type="text" name="keyword" value="<%=request.getParameter("keyword")%>"> 54 <input type="submit" value="查询"> 55 </form> 56 <script type="text/javascript"> 57 function changeCp(newcp) { 58 // 改变当前页数 59 document.getElementById("cp").value = newcp; 60 // 提交表单 61 document.getElementById("split_page_form").submit(); 62 } 63 </script> 64 65 </center> 66 </body> 67 </html>
总结:
这个项目看起来很简单,但是囊括了很多知识,包括
1’ java的多线程处理,接口及方法实现;
2‘ 数据库的基础操作及代码连接与表操作;
3’ 网络爬虫进行数据的收集,包含两种方法(仅我会的,这个是难点):
(1)java代码实现(正则表达式或者Jsoup)
(2)Heritrix工具实现(抑或其他工具)
4‘ Hadoop的基本配置和HDFS于eclipse的配置(后续阐述);
5’ HDFS的文件存取、MapReduce方法的编写(这个是难点);
6‘ DAO设计模式的代码实现;
7’ Jsp/Servlet的基础知识,以及JSTL和EL的了解
该项目实现的功能包含:
1‘ 数据收集(网络爬虫);
2’ 数据保存(DAO,数据库及HDFS);
3‘ 数据分析/规约(MapReduce);
4’ 搜索引擎(jsp/servlet,jstl/el);
5‘ web呈现(web项目)
这是一个简单的大数据搜索引擎的实现,综合性较强,需要多多阅读学习。
此外,还有一些缺陷未能实现,会有些麻烦,一个在编码格式上,一个在搜索的关键字交叉搜索上。

