深入解析 SQL Server 高可用镜像实现原理
作者:郭忆
本文由 网易云 发布。
SQL Server 是 windows 平台 .NET 架构下标配数据库解决方案,与 Oracle、MySQL 共同构成了 DB-Engines Ranking 的第一阵营,在国内外企业市场中有着广泛的应用。
Mirroring 是 SQL Server 最常用的高可用解决方案,具有自动故障转移,高安全模式下具有数据“零”丢失,对客户端透明等优势,目前多家大的云计算厂商均采用该技术实现云端 SQL Server 高可用部署。今天,我们就来聊聊 SQL Server 高可用镜像实现原理。
数据副本
镜像技术实现了位于不同物理服务器上的两个 SQL Server 实例数据同步,在镜像集群中, SQL Server 实例具有三种角色:
○ Principal:具有完整的数据副本,对外提供数据库读写服务;
○ Mirror:具有完整的数据副本,本身不提供读写服务,通过接收来自 Principal 的更新日志实现数据同步,允许创建快照实现报表;
○ Witness:本身不存储数据,只负责在高安全运行模式下提供自动故障切换的能力,确保两个 SQL Server 实例只有一个对外提供服务,避免脑裂情况出现;
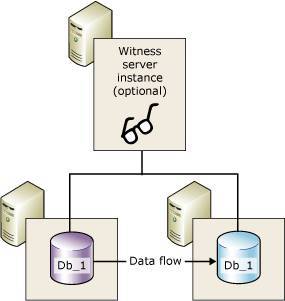
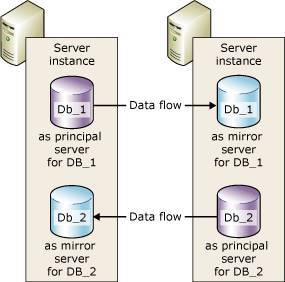
在镜像集群中,principal 和 mirror 的数据同步是依靠事务日志来实现的,与 Oracle 和 MySQL 不同,SQL Server 的事务日志是 Database 级别的,不是实例级别的,每个 Database 都单独的事务日志,这也就使得 SQL Server 的镜像是可以基于 Database 层面实现。
一个 SQL Server 实例中的两个 Database,一个可以作为 principal,一个可以作为 mirror,分别与其他 SQL Server 实例组建镜像关系;另外,SQL Server 一个 Database 只能有一个 mirror 节点,一个 mirror 的 database 不可以再有 mirror 节点,这点与 MySQL 级联复制不同;
SQL Server 的事务日志是物理记录级别的,记录了对数据库某个页的某行记录(slot)的操作,principal 创建镜像后,会启动一个单独的事务日志发送线程,维护一个虚拟的发送队列,然后读取事务日志,将其进行压缩,根据官方公布的测试数据,压缩比不低于12.5%,然后发送给 mirror 节点,mirror 节点接收到以后,会将其写入本地在磁盘上的一个重做队列文件中,然后再通过另外的一个线程异步的方式,从重做队列中获取事务日志,然后分发给应用线程(process unit)进行回放。
不同于 MySQL Binlog,由于 SQL Server 的事务日志在 principal 上事务执行过程中就已经源源不断的写入(MySQL Binlog 仅在事务提交阶段生成),在 principal 事务执行的同时事务日志就已经传递给了 mirror,所以基于事务日志的 SQL Server 的复制性能会更理想。同时,在 mirror 回放的过程中,可以基于页(page)级别进行并发更新(redo parallel),在 SQL Server 的标准版中,仅提供一个线程进行事务日志回放(roll forward),在企业版中,如果当前服务器 CPU 大于5核,则每4个核,增加一个并行线程,如果低于5个核,则仍然使用单线程回放。同时,基于页的事务日志的并发执行,还有一个好处就是对于同一个页面的更新可以合并刷新,减少脏页刷新数量。
运行模式
镜像集群提供了三种运行模式:
○ 高性能模式:principal 与 mirror 之间数据异步传输,principal 上的事务提交无需等待 mirror 的响应,principal 宕机后,存在数据更新丢失的可能,不支持自动故障转移,可以通过强制服务的方式使得 mirror 提供服务。适合对数据可靠性要求不高,性能要求较高的业务场景,与 MySQL 的异步复制模式,Oracle DataGuard 最大性能模式相近;
○ 不带故障转移的高安全模式:principal 上所有的事务提交,都必须要确认该事务涉及的事务日志均已经传送到的 mirror 上,并写入 mirror 的重做队列中,持久化(是否持久化到外存设备还与 windows 操作系统写入缓存策略相关),mirror 返回确认后,才可提交,可以实现 principal 宕机下数据“零”丢失,不支持自动故障转移,可以通过手动转移或者强制服务方式使得 mirror 提供服务。与 MySQL 5.7 Loss-less replication、Oracle DataGuard 最大可用模式相近;
○ 带故障转移的高安全模式:与不带故障转移的高安全模式相比,增加了 witness (见证服务器),可以实现自动的故障转移,通过 witness,可以确保只有一个节点成为 principal,对外提供服务,实际上 witness 最重要的一个作用就是选主;
故障转移
镜像集群故障转移最复杂场景就是带见证服务器的支持自动故障转移的高安全模式,所以我们重点讨论该模式下的故障处理流程。
初始状态下,witness、principal 和 mirror 三个节点两两之间均保持长连接会话,现在讨论其中一方连接中断的情况:
Principal 与 witness 连接中断:
此时 witness 与 mirror 连接正常,触发自动故障恢复流程,principal 丢失 witness 连接会话,如果 principal 仍在运行状态,则将状态标记为 disconnected,表示失去与 mirror 连接,切断所有客户端连接,停止读写服务,等待故障切换。为了防止网络抖动引起不必要的切换,会话超时默认时间为 10秒;witness 和 mirror 将 principal 标记为不可用,等待 mirror 上的重做队列中的事务日志回放(roll forward)完成后,mirror 成为新的 principal,开始对外提供读写服务。
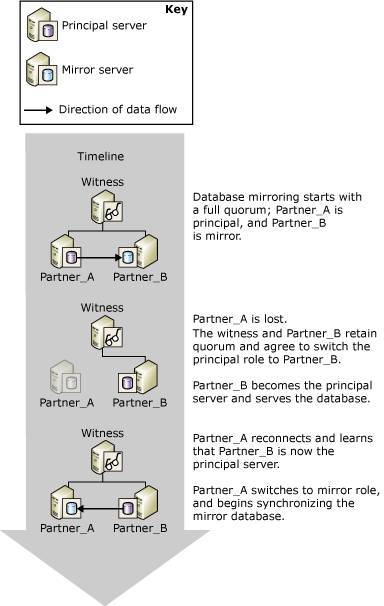
最后 mirror 会通过后台线程,将未提交的事务回滚(基于 binlog 的 MySQL 复制,由于 binlog 是在事务提交阶段生成的,所以不存在事务回滚的阶段)。
从整个故障切换的流程来看,故障切换时间主要包括三个部分:检测到 principal 宕机的时间、mirror 上重做队列中事务日志的回放时间以及回滚未提交事务的时间,其中前面两段时间服务不可用,尤其是重做队列的回放时间,直接决定了服务不可用时间。

mirror 与 witness 连接中断:
此时,principal 与 witness 连接正常,principal 状态变为 Disconected,表示终止与 mirror 连接,mirror 状态变为 suspend,principal 不再向mirror 发送事务日志,等待 mirror 重新建立到 witness 连接后,principal 才会恢复与 mirror 进行数据同步。
Principal 与 mirror 连接中断:
principal 与 mirror 同时保持 witness 的连接会话,但是 principal 与 mirror 之间会话中断,witness 会通知 mirror,principal 依然保持连接状态,不会触发故障切换;此时 principal 由于保持有 witness 的连接会话,服务正常。
下面来考虑三方会话两个会话同时中断情况:
principal 与所有节点会话中断:
只要 mirror 与 witness 会话正常,即可完成正常的故障转移;如果 mirror 与 witness 连接也中断,则无法完成,即便是后来 mirror 与 witness 的会话优先恢复,则也无法故障切换,因为已然不确定 mirror 是否拥有全部 principal 的数据,此时即便 principal 处于运行状态,也无法提供服务,等待 principal 与任意节点会话恢复正常,即可恢复读写服务;
mirror 与 所有节点会话中断:
不会触发故障切换,principal 切入公开运行模式(异步),即不会再向 mirror 发送事务日志,也不再需要等待 mirror 的响应,直到 mirror 重新恢复会话。
witness 与所话中断:
不会触发故障切换,principal 继续提供读写服务,与 mirror 数据继续同步,镜像集群丧失自动故障转移能力,退化为不带故障转移的高安全模式;
如果三方会话同时连接中断,则 principal 无法提供服务,直到 principal 与任意节点通信恢复正常。
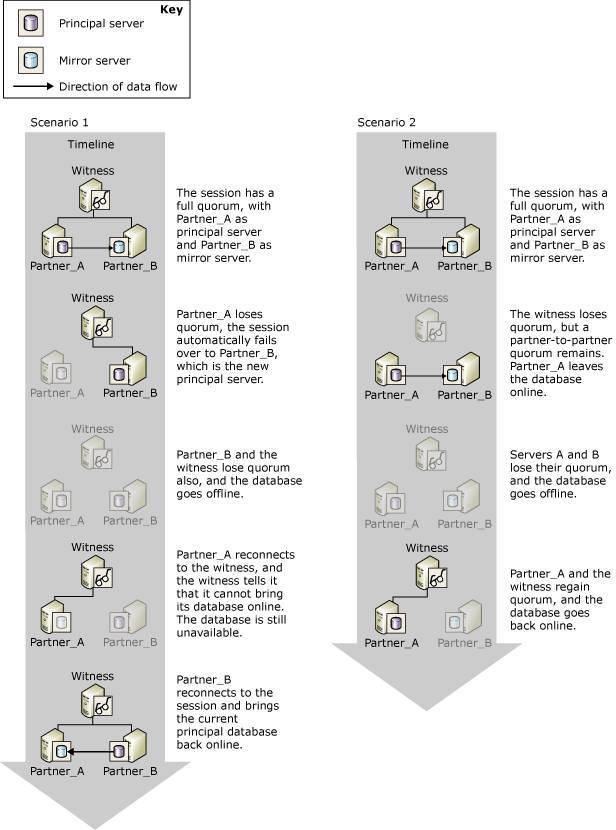
场景1中,初始状态实例 A、B 和 witness 保持会话连接,其后,A 实例宕机,失去与其他成员的会话,实例 B 与 witness 保持会话,触发故障切换,实例 B 升级为 principal。其后实例 B 也宕机,服务停止。然后实例 A 恢复,但是由于此时实例 A 已经是 mirror,不能确定实例 A 拥有实例 B 的所有更新数据,所以无法故障切换,最后实例 B 恢复,服务恢复正常。
场景2 中,实例 A 和 B 同时失去了与 witness 的会话,但是服务已然正常,A 与 B 之间数据继续同步,其后 A 与 B 同时宕机,服务停止。最后 A 恢复服务,与 witness 恢复会话,A 继续提供服务。
透明切换
一个完整的高可用机制除了后端节点的切换,还包括发生故障转移后,客户端如何能够快速地连接到冗余节点,继续业务读写。常用的实现,包括 Driver 层解决方案,例如 mongoDB replication set,也有通过二层内的广播方式实现 vip,例如 keepalived,当然还包括 proxy,以及三层 DNS 的实现。
SQL Server 的实现采用了 Driver 层处理的方式,开发者要实现自动的故障转移,在连接数据库时,除了必须要指定初始节点的 IP 和端口,还要指定故障转移的节点的 IP 和端口。客户端首先尝试使用初始节点创建连接,如果初始节点指向的实例当前为 principal,则连接会建立成功,可以正常的读写。当发生故障切换时,principal 会切断所有已有客户端连接,然后客户端建立到初始节点连接也会失败,通过一定的重试策略失败后,会尝试连接之前指定的故障转移节点,从而实现服务入口的切换。
SQL Server 常用的访问接口:OLE DB、ODBC、ADO 均支持指定故障转移节点,格式如下:
Server=250.65.43.21,4734; Failover_Partner=250.65.43.22,4734;
集群监控
镜像集群的监控可以通过 SQL Server Management stdio 启动镜像监视器,或者系统内置的存储过程来实现,监控的主要指标包括:
○ 未发送日志:principal 上未发送的日志超过指定的阈值,会在 principal 上生成一个警告,在高性能模式下,强制服务时可以作为评估 principal 上事务丢失数量的依据,同样也适用于在高安全模式切换成异步模式状态下(mirror 失去连接)。
○ 未还原日志:重做队列中的未被应用的事务日志数量(KB),超过阈值,会在 mirror 上生成一个警告,该值可以作为评估故障转移时间的主要因素。
○ 最早未被发送的事务:principal 发送队列中,最早未被发送的事务距离现在的时间,单位时分钟,超过阈值,会在 principal 上生成警告,与未发送日志量一起,从时间维度,衡量高性能模式下和高安全异步模式下,数据丢失数量。
○ 镜像提交开销:高安全模式下,principal 上事务从提交到等到 mirror 响应的时间开销的平均值,如果超过阈值,则在 principal 上生成一个警告,在同步模式下,该值可以衡量同步开销。
参考文档:请点击这里
了解网易云:
网易云官网:https://www.163yun.com/
新用户大礼包:https://www.163yun.com/gift
网易云社区:https://sq.163yun.com/
