知物由学 | 未来安全隐患:AI的软肋——故意欺骗神经网络
本文由 网易云 发布。
“知物由学”是网易云易盾打造的一个品牌栏目,词语出自汉·王充《论衡·实知》。人,能力有高下之分,学习才知道事物的道理,而后才有智慧,不去求问就不会知道。“知物由学”希望通过一篇篇技术干货、趋势解读、人物思考和沉淀给你带来收获的同时,也希望打开你的眼界,成就不一样的你。当然,如果你有不错的认知或分享,也欢迎通过邮件(zhangyong02@corp.netease.com)投稿。
以下是正文:
对于很多计算机程序,在黑客眼中,他们不是想享受这些程序提供的服务,而是想如何利用这些程序获得一些非法的收入。带黑帽子的黑客通常会利用程序中最微小的漏洞进入系统,窃取数据并造成严重破坏。

100%真正的黑客
但由深度学习算法驱动的系统应该可以避免人为干扰吧?黑客如何通过神经网络训练TB量级的数据?
但,事实证明,即使是最先进的深层神经网络也很容易被愚弄。用一些小技巧,你可以强迫神经网络显示你想要的任何结果:
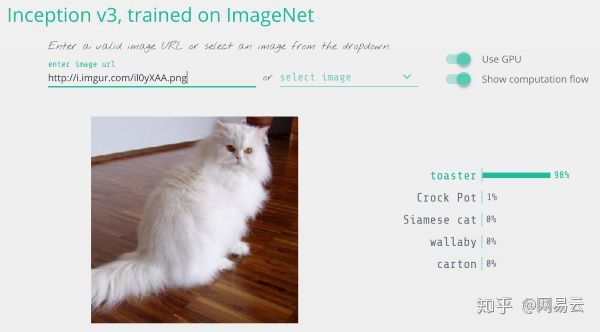
我修改了这张猫的图片,以便它被认为是烤面包机。
因此,在你启动一个由深度神经网络打造的新系统之前,你需要了解如何攻破它们以及如何保护自己免受攻击。
神经网络作为安全警卫
假设我们运行了一个像eBay这样的网站,在我们的网站上,我们希望阻止人们销售违禁物品,例如活动物甚至一些野生的保护动物。
如果你拥有数百万级别用户,那么实行这些规则就很困难。你可以聘请数百人手工审查每一个拍卖物品,但这意味着很高的成本。相反,我们可以使用深度学习来自动检查违禁物品的拍卖照片,并标记违反规定的拍卖照片。
第一步,我们需要从这个场景中带着问题走出来,我们可以发现,这个问题其实就是一个典型的图像分类问题。为了达到目的,我们将训练一个深层卷积神经网络,告诉什么是违禁物品什么是合法的物品,然后我们将它运行我们网站上,来保证网站规则能够有效的实施。
首先,我们需要一个过去拍卖清单的数千个图像的数据集。我们需要合法和违禁物品的图像,以便我们可以训练神经网络来区分它们:

为了训练神经网络,我们使用标准的反向传播(BP)算法。我们通过一个图片,传递该图片的预期的结果,然后遍历神经网络中的每个图层,稍微调整它们的权重以使它们在为该图片生成正确输出方面表现的更好一些:

我们用数千张照片重复数千次,直到模型能够准确地产生正确的结果。最终我们可以打造一个可靠的用于图像分类的神经网络:

注意:阅读下文你需要了解卷积神经网络的原理,如果你想了解卷积神经网络如何识别图像中的对象,请参阅第3部分[1]。
但事情并不像看起来那么简单...
卷积神经网络是用于图像分类的最受欢迎的模型。无论它们出现在图像中的哪个位置,它们都可以识别复杂的形状和图案。在许多图像识别任务中,它们的性能可以超过常人的判断。
有了这样的强大的模型,将图像中的几个像素更改为更暗或更亮应该不会对最终预测产生很大影响吧?当然,它可能会稍微改变最终的预测,但它不应该将图像从“违禁”转换为“合法”。

我们期望的是:对输入照片的小改动只会对最终预测产生微小的变化。
但在2013年的一篇名为神经网络的神奇属性[2]的论文中,人们发现这并非总是如此。如果你确切的知道改变那些像素点可以使图像最大可能的发生改变,你就可以故意迫使神经网络对给定的图片做出错误的预测,而图片的外观改变的并不是很多。
这意味着我们可以有意地制作一张图片,该图片显然是一种被禁止的项目,但却完全愚弄了我们的神经网络:
为什么会这样?机器学习分类器的工作原理是找出它试图分辨的东西的分界线。以下是在图表上显示的一个简单的二维分类器的示例,该分类器将红点(合法)与绿点(违禁)分开:
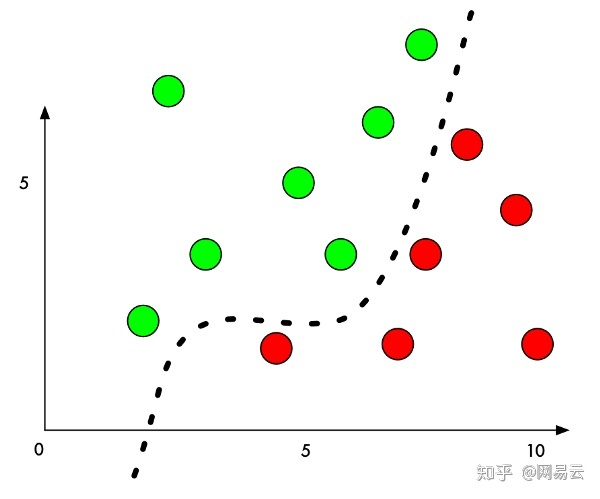
现在,该分类器的可以做到100%的正确率。找出一条线将红点和所有绿点完美的分开。
但是,如果我们想诱使它将一个红点误分类为绿点,该怎么办?
如果我们在边界旁边的红点的Y值上添加一小部分,我们可以将它简单地推到绿色区域:
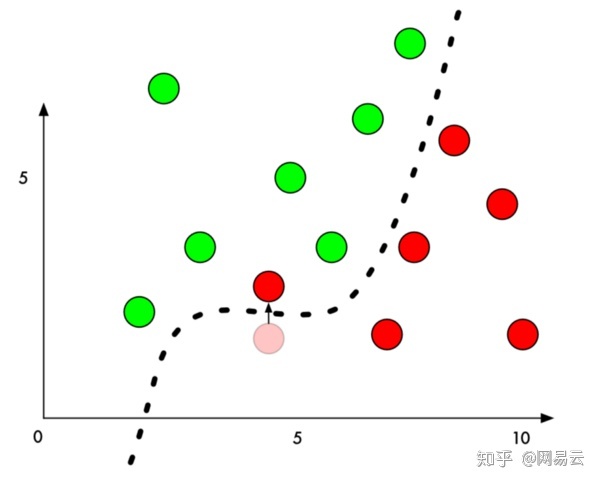
因此,要欺骗一个分类器,我们只需要知道从哪个方向来推动点越过线。如果我们不想过于狡猾,理想情况下我们会尽可能少地提出这一点,但理想总归是理想情况,黑客通常不会再理想情况下进入。
在使用深度神经网络的图像分类中,我们所分类的每个“点”是由数千个像素组成的整个图像。这给了我们数以千计的可能值,我们可以通过调整这些数值来突破决策线。如果我们确保以对人类来说不太明显的方式调整图像中的像素,我们可以欺骗分类器而不会使图像看起来被改动。
换句话说,我们可以对一个物体进行真实拍摄,并且非常轻微地改变像素,以便图像可以完全欺骗神经网络,使其认为图像是其他东西:
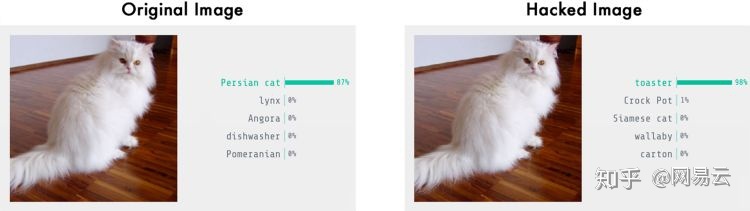
把一只猫变成烤面包机,基于网络的Keras.js演示的图像检测结果
如何欺骗神经网络
我们已经讨论过训练神经网络来分类照片的基本过程:
- 利用照片训练神经网络。
- 检查神经网络的预测,看看其性能。
- 使用反向传播调整神经网络中每层的权重,使最终预测逐渐接近正确答案。
- 用几千张不同的训练照片,重复步骤“1-3”。
但是,如果不是调整神经网络层的权重,而是调整输入图像本身,直到我们得到我们想要的答案为止呢?
那么让我们把已经训练好的神经网络再训练一遍。但让我们使用反向传播来调整输入图像而不是神经网络图层:
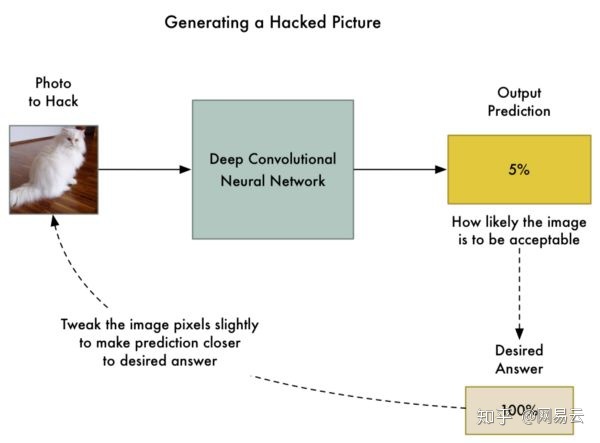
以下是新算法:
- 利用照片训练神经网络。
- 检查神经网络的预测,看看其性能。
- 使用反向传播调整使用的照片,使最终预测逐步接近我们想要得到的答案。
- 用相同的照片重复步骤“1-3”几千次,直到网络给到我们理想的答案。
在这之后,我们将拥有一个图像,可以在不改变神经网络内部的任何东西的情况下愚弄神经网络。
唯一的问题是,通过随意调整单个像素,对图像的更改可以太过明显,以至于你会看出它们。他们会出现变色斑点或波浪区域:
 你可以看到猫周围的绿色变色斑点和白色墙壁上的波浪图案。
你可以看到猫周围的绿色变色斑点和白色墙壁上的波浪图案。
为了防止出现这些情况,我们可以为我们的算法添加一个简单的约束。被黑客入侵的图像中的任何一个像素都不能从原始图像中改变很多,比如0.01%。这迫使我们的算法以一种愚弄神经网络的方式来调整图像,而不会让它看起来与原始图像太不同。
下面是我们添加该约束时生成的图像的样子:

即使这幅图像看起来与我们之前的一样,它仍然愚弄了神经网络!
Let’s Code It!
首先我们需要一个预先训练的神经网络来愚弄。我们不是从头开始训练,而是使用Keras,Keras是深受欢迎的深度学习框架,它带有几个预先训练好的神经网络[3]。我们将使用Google的Inception v3深度神经网络的副本,该网络已经过预先训练,可以检测1000种不同类型的对象。
Keras中的基本代码使用这个神经网络来识别图片中的内容。在运行它之前,确保你已经安装了Python 3和Keras(详细代码获取见文末):
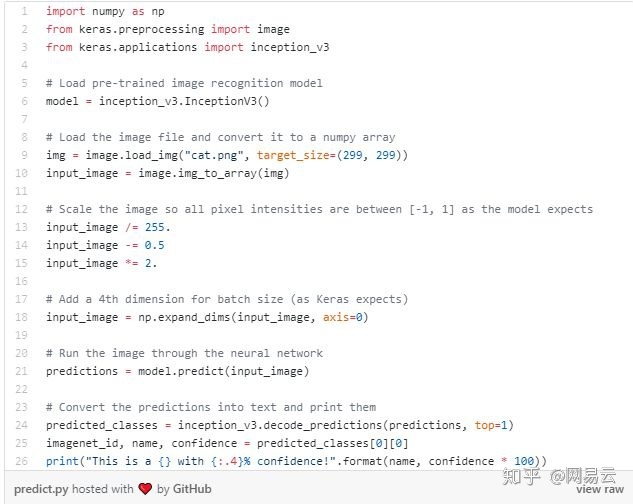
当我们运行它时,它正确地检测到波斯猫的形象:
$ python3 predict.py
This is a Persian_cat with 85.7%confidence!
现在让我们开始调整图像,直到它能够愚弄神经网络,让神经网络认为这只猫是一个烤面包机。
Keras中没有内置的方式来训练输入图像,所以我不得不手动编码训练步骤。
代码如下(详细代码获取见文末):

图为部分代码
如果我们运行它,它最终会生成一个可以欺骗神经网络的图像:
$ python3 generated_hacked_image.py
Model's predicted likelihood that theimage is a toaster: 0.00072%
[ .... a few thousand lines of training....]
Model's predicted likelihood that theimage is a toaster: 99.4212%
注意:如果你没有GPU,则可能需要几个小时才能运行。如果你确实已经使用Keras和CUDA正确配置了GPU,则运行时间不应超过几分钟。
现在让我们再次测试通过原始模型运行鉴别这张经过技术更改的图片:
$ python3 predict.py
This is a toaster with 98.09%confidence!
我们成功的欺骗了神经网络,认为猫是烤面包机!
我们可以用黑客技术生成图像做些什么呢?
我们这样篡改图像被称为“产生敌对的例子”。我们故意制作一段数据,以便机器学习模型将其误分类。这是一个巧妙的技巧,但为什么在现实世界中这很重要?
研究表明,这些被黑客篡改的图像具有一些令人惊讶的特性:
- 即使将它们打印在纸上,被篡改的图像仍然可以欺骗神经网络!因此,你可以使用这些被黑客篡改的图像来欺骗物理相机或扫描仪,而不仅仅是直接上传图像文件的系统。
- 欺骗一个神经网络的图像往往也会欺骗其他神经网络,如果他们接受类似数据的训练,就会完全不同的设计。
所以我们可以用这些被黑客篡改的图片做很多事情!
但是,我们如何创建这些图像仍然存在很大的局限性!因为我们要想攻击就需要直接访问神经网络本身。因为我们实际上生成图片的过程,就需要神经网络的参与,所以我们需要它的一个副本。在现实世界中,没有公司会让你下载他们训练的神经网络的代码,所以这意味着我们不能攻击他们吗?
NO!研究人员最近表明,你可以训练自己的神经网络来反映另一个神经网络[4],通过探测它来了解它的行为。然后你可以使用你的替代神经网络来生成被黑客入侵的图片,这些图片仍然会欺骗原始网络!这被称为黑盒攻击。
黑盒攻击的应用是无限的,这里有一些例子:
- 自动驾驶汽车看到停车标志误认为绿灯,这可能会导致车祸!
- 欺骗内容过滤系统让非法内容通过。
- 欺骗ATM检查扫描仪,例如支票上的笔迹。
而这些攻击方法并不仅限于图像。你可以使用相同类型的方法来处理其他类型数据的分类器。例如,你可以欺骗病毒扫描程序将你的病毒识别为安全代码!
我们如何保护自己免受这些攻击?
所以现在我们知道有可能存在欺骗神经网络(以及其他的机器学习模型)的事情,我们又该如何防御呢?
简短的回答是,没有人知道如何完美防御。防止这些类型的攻击仍然是一个正在进行的研究领域。了解最新该领域发展的最好方法是阅读Ian Goodfellow和Nicolas Papernot的cleverhans博客,他们是该领域最有影响力的两位研究人员。
但是到目前为止,我们知道一些关于这方面的情况:
- 如果你拥有大量被黑客篡改的的图像,并将其纳入未来的训练数据集中,这似乎会使你的神经网络更能抵御这些攻击。这就是所谓的对抗训练,这可能是现在考虑采用的最合理的防御方法。
- 还有另一种有效的方法称为Defensive Distillation[5],你可以训练第二个模型来模拟你的原始模型,但是这种方法是全新的而且相当复杂的。
- 几乎所有研究人员迄今为止尝试过的其他想法都未能有效预防这些攻击。
由于我们还没有最终防御方案,所以我们应该考虑到底如何确定使用神经网络的场景,以便减少这种攻击会对你的业务造成损害的风险。
云安全(易盾)基于网易20年技术积累及安全大数据,为互联网各行业提供反垃圾、验证码、注册保护、登录保护、活动反作弊、应用加固、DDoS 防护等整体安全解决方案,全程提供完善的技术支持,助力产品建立安全防护体系。
原文地址:http://mp.weixin.qq.com/s/RV3jUJiOYCD-SjDRRX5spw
了解 网易云 :
网易云官网:https://www.163yun.com/
新用户大礼包:https://www.163yun.com/gift
网易云社区:https://sq.163yun.com/

