「2019纪中集训Day5」解题报告
T1、矩阵游戏
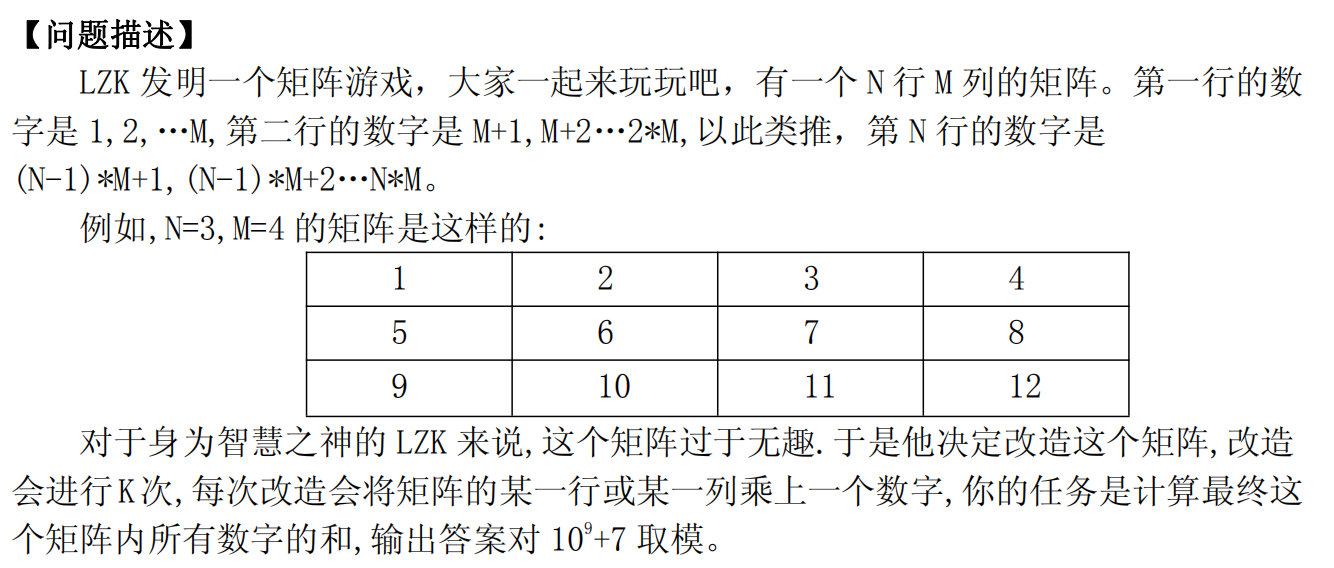


\(Sol\):
可以单独考虑一个点进行两种不同的操作后对答案的贡献,随便推一推就能算了。
或者可以把行列的操作分开算,不难发现行的和是个等差数列(列也一样),只需要先进行(xing)行(hang)操作,维护每一列的和的首项和公差即可;
时间复杂度 \(O(m)\)。
代码如下:
//#pragma GCC optimize(2)
//#pragma GCC optimize(3,"Ofast","inline")
#include <cstdio>
#include <cstring>
#include <algorithm>
int in() {
int x = 0; char c = getchar(); bool f = 0;
while (c < '0' || c > '9')
f |= c == '-', c = getchar();
while (c >= '0' && c <= '9')
x = (x << 1) + (x << 3) + (c ^ 48), c = getchar();
return f ? -x : x;
}
template<typename T>inline void chk1(T &_, T __) { _ = _ < __ ? _ : __; }
template<typename T>inline void chk2(T &_, T __) { _ = _ > __ ? _ : __; }
const int N = 1e6 + 5, Q = 1e5 + 5, mod = 1e9 + 7;
int n, m, q;
struct info {
int typ;
int x, k;
} a[Q];
int x[N], y[N];
inline void add(int &_, int __) {
_ += __;
if (_ >= mod) _ -= mod;
if (_ < 0) _ += mod;
}
int main() {
//freopen("in", "r", stdin);
freopen("game.in", "r", stdin);
freopen("game.out", "w", stdout);
n = in(), m = in(), q = in();
for (int i = 1; i <= q; ++i) {
char c = getchar();
while (c != 'R' && c != 'S')
c = getchar();
a[i] = (info){c == 'R', in(), in()};
}
int d = n;
for (int i = 1; i <= n; ++i)
x[i] = 1;
if (n & 1)
y[1] = 1ll * (1ll * (n - 1) / 2 * m + 1) % mod * n % mod;
else
y[1] = 1ll * (1ll * (n - 1) * m + 2) % mod * (n / 2) % mod;
for (int i = 1; i <= q; ++i)
if (a[i].typ) {
add(y[1], 1ll * (1 + 1ll * (a[i].x - 1) * m % mod) * x[a[i].x] % mod * (a[i].k - 1) % mod);
add(d, 1ll * (a[i].k - 1) * x[a[i].x] % mod);
x[a[i].x] = 1ll * x[a[i].x] * a[i].k % mod;
}
for (int i = 2; i <= m; ++i)
y[i] = y[i - 1], add(y[i], d);
for (int i = 1; i <= q; ++i)
if (!a[i].typ)
y[a[i].x] = 1ll * y[a[i].x] * a[i].k % mod;
for (int i = 1; i <= m; ++i)
add(y[0], y[i]);
printf("%d\n", y[0]);
return 0;
}
T2、跳房子


\(Sol\):
考虑优化暴力找循环节,记录每个点会走到第 \(m\) 列的哪一个位置,修改时找到第一列中会改变的区间即可;
时间复杂度 \(O((m + n)\ Q)\)。
代码(咕)
T3、优美序列

数据保证随机。
\(Sol_1\):
对于一个询问 \(l, r\),找出 \(l, r\) 之间的最小、大值记为 \(x, y\),判断是否 \(l - r == x - y\),然则 \(l, r\) 为答案,否则用大小在 \(x, y\) 之间最左边和最右边的位置更新 \(l, r\);
最大最小值用 \(st\) 表维护。
显然地,这样做最坏复杂度是 \(O(n ^ 2)\),但是数据保证随机,卡一卡就过了。
没有代码(我没有卡过)。
\(Sol_2\):
这个是题解里的做法;
将询问离线处理,分治求解;
先找出所有在 \(l, r\) 之间的询问,分成三类,包含于 \([l,mid]\)、包含于 \([mid + 1, r]\)、包含 \([mid, mid + 1]\);
前两种递归处理,第三种可以找出所有包含 \([mid, mid + 1]\) ,不超出 \(l, r\) 的优美序列,然后更新答案。
由于数据随机,它也可以过,时间复杂度 \(O(n \ log_2^2 n)\) (反正我觉得它是个期望复杂度)。
代码(?),反正看着都像假算法为什么不写 \(Sol1\)。
\(Sol_3\):
讲题人说是可以用析合树做,有兴趣可以去学一下。
\(Sol_4\):
一个区间 \(l, r\) 它是完美序列,当且仅当:\(l + num == r\) 成立,其中 \(num\) 为区间里差为 \(1\) 的数对个数;
先把询问排序按右端点,从左到右枚举序列的每一个位置,设现在枚举到 \(i\);
那么对于询问 \(ql, qr\) $(qr \le i) $,只需查询 \([1,ql]\) 中是否有满足条件,就可知以 \(i\) 为右端点,该询问是否可以被解决,
即:该询问被右端点为 \(i\) 的完美序列包含,若可以,找一个最大的左端点即可,若不能解决,放进堆里以后处理(堆是关于左端点的大根堆);
设 \([l_1, r_1], [l_2, r_2]\) 都是完美序列且 \(l_2 \le r_1,r_1 \le r_2\),则 \([l_2, r_1]\) 也是完美序列,所以这样做一定是对的,所有询问一定会在第一次能够解决时得到最优解,这一点是显然的,不再赘述;
对于 \(l + num\) 的维护:
因为右端点是枚举的,只需维护对于当前的右端点,所有左端点 \(p \in [1, i]\),\(p + num_p\) 的值即可;
这个可以用线段树维护:\(a_i\) 只会对 \(i\) 左边的 \(a_i - 1\),\(a_i + 1\) 有贡献,左端点取在它们左边的 \(l + num\) 就会加 \(1\);
时间复杂度 \(O(n \ log_2 n)\)。
代码如下:
//#pragma GCC optimize(2)
//#pragma GCC optimize(3,"Ofast","inline")
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <vector>
#include <queue>
int in() {
int x = 0; char c = getchar(); bool f = 0;
while (c < '0' || c > '9')
f |= c == '-', c = getchar();
while (c >= '0' && c <= '9')
x = (x << 1) + (x << 3) + (c ^ 48), c = getchar();
return f ? -x : x;
}
template<typename T>inline void chk_min(T& _, T __) { _ = _ < __ ? _ : __; }
template<typename T>inline void chk_max(T& _, T __) { _ = _ > __ ? _ : __; }
const int N = 1e5 + 5;
int n, m, a[N], pos[N];
std::pair<int, int> res[N];
std::vector<std::pair<int, int> > b[N];
std::priority_queue<std::pair<int, int> > q;
struct segment_tree {
std::pair <int, int> t[N << 2];
int add[N << 2];
inline void push_up(const int p) {
t[p] = std::max(t[p << 1], t[p << 1 | 1]);
}
void build(const int tl, const int tr, const int p) {
if (tl == tr)
return (void)(t[p].first = tl, t[p].second = tl);
int mid = (tl + tr) >> 1;
build(tl, mid, p << 1);
build(mid + 1, tr, p << 1 | 1);
push_up(p);
}
inline void spread(const int p) {
add[p << 1] += add[p], add[p << 1 | 1] += add[p];
t[p << 1].first += add[p], t[p << 1 | 1].first += add[p];
add[p] = 0;
}
void modify(const int l, const int r, const int tl, const int tr, const int p) {
if (l <= tl && tr <= r)
return (void)(++t[p].first, ++add[p]);
if (add[p])
spread(p);
int mid = (tl + tr) >> 1;
if (mid >= l)
modify(l, r, tl, mid, p << 1);
if (mid < r)
modify(l, r, mid + 1, tr, p << 1 | 1);
push_up(p);
}
std::pair<int, int> query(int l, int r, int tl, int tr, int p) {
if (l <= tl && tr <= r)
return t[p];
if (add[p])
spread(p);
int mid = (tl + tr) >> 1;
if (mid < l)
return query(l, r, mid + 1, tr, p << 1 | 1);
if (mid >= r)
return query(l, r, tl, mid, p << 1);
return std::max(query(l, r, tl, mid, p << 1),
query(l, r, mid + 1, tr, p << 1 | 1));
}
} T;
int main() {
// freopen("in", "r", stdin);
freopen("sequence.in", "r", stdin);
freopen("sequence.out", "w", stdout);
n = in(), T.build(1, n, 1);
for (int i = 1; i <= n; ++i)
a[i] = in(), pos[a[i]] = i;
m = in();
for (int i = 1, l, r; i <= m; ++i) {
l = in(), r = in();
b[r].push_back(std::make_pair(l, i));
}
for (int i = 1; i <= n; ++i) {
if (a[i] > 1 && pos[a[i] - 1] < i)
T.modify(1, pos[a[i] - 1], 1, n, 1);
if (a[i] < n && pos[a[i] + 1] < i)
T.modify(1, pos[a[i] + 1], 1, n, 1);
unsigned siz = b[i].size();
for (unsigned j = 0; j < siz; ++j)
q.push(b[i][j]);
while (!q.empty()) {
std::pair<int, int> u = q.top(), tmp;
tmp = T.query(1, u.first, 1, n, 1);
if (tmp.first == i)
res[u.second] = std::make_pair(tmp.second, i), q.pop();
else
break;
}
}
for (int i = 1; i <= m; ++i)
printf("%d %d\n", res[i].first, res[i].second);
return 0;
}

