
Java NIO之缓冲区
简介
接着上面那篇JavaWeb有关的故事,讲讲NIO,上篇在这:[JavaWeb有关的故事](http://www.cnblogs.com/1024Community/p/8589403.html) 几个IO事实: 1. 影响应用程序执行效率的限定因素,往往非处理速率,而是IO 2. OS要移动大块数据,往往是在DMA协助下完成,而JVM的IO操作往往是小块数据,有了NIO,可改变这种情况 3. JDK1.4,java.nio提供了一套新的抽象用于IO处理IO概念
缓冲区操作
进程执行IO操作,要么把缓冲区的数据排干(read),要么用数据把缓冲区填满(write)。 进程使用read()系统调用,要求其缓冲区需要被填满,内核随机向磁盘控制硬件发出命令,通过DMA(无需主CPU协助)讲数据写入内核内存缓冲区,一旦磁盘控制器把缓冲区装满,内核即把数据从内核空间的临时缓冲区拷贝到进程read()调用时执行的缓冲区。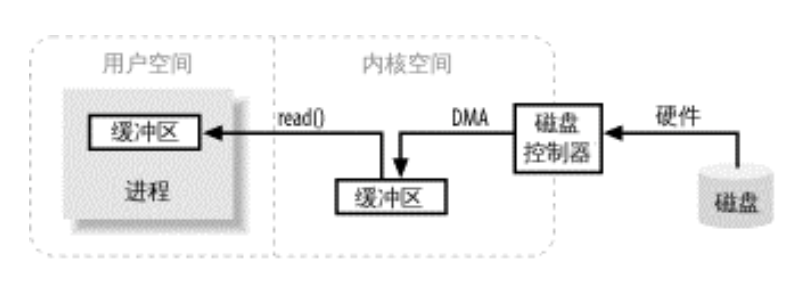
其中用户空间和内核空间:
用户空间是常规进程所在区域,如JVM。内核空间是操作系统所在区域,有特别权力,能与设备控制器通讯,控制用户区域进程的运行状态等。总之,所有IO都直接或间接通过内核空间。
硬件不能直接访问用户空间,硬件设备操作的是固定大小的数据块,而用户进程请求的可能是任意大小的或非对齐的数据块。
虚拟内存
使用虚拟地址取代物理内存地址,有个两大类好处,一是多个虚拟地址可知指向同一物理地址,二是虚拟内存空间可大于硬件内存。
文件IO
文件系统与磁盘不同,文件系统是高层次的抽象,是安排、解释磁盘或其他随机存取块设备数据的一种独特方法。 文件系统数据也会同其他内存页一样得到高速缓存,对于随后发生的IO请求,文件数据的部分或全部可能仍位于物理内存中,无需从磁盘读取。文件锁定:分为共享和独占。多个共享锁可同时对同一文件区域发生作用,独占锁要求相关区域不能有其他锁起作用。
流IO
原理模仿通道,必须顺序存取,如控制台设备、打印机端口。缓冲区
Buffer类是nio构造基础,一个Buffer对象是固定数量的数据容器,在这里的数据可悲存储并在之后用于检索。可以理解为是I/O操作中数据的中转站。缓冲区直接为通道(Channel)服务,写入数据到通道或从通道读取数据,这样的操利用缓冲区数据来传递就可以达到对数据高效处理的目的。Buffer属性
容量capacity:创建时设定,不可改变。 上界limit:不可读写。现存元素的计数。 位置position:下一个要被读或写元素的索引。 标记mark:一个备忘位置。Buffer数据填充、翻转、释放、压缩、标记
java.nio.Buffer类是一个抽象类,不能被实例化。Buffer类的直接子类,如ByteBuffer等也是抽象类,所以也不能被实例化。 但是ByteBuffer类提供了静态工厂方法来获得ByteBuffer的实例,终于到了show代码的时候了=。=,如下: ```java //初始化 ByteBuffer buffer = ByteBuffer.allocate(1024); //数据填充 buffer.put((byte) 'H').put((byte) 'e').put((byte) 'l').put((byte) 'l').put((byte) 'o'); System.out.println(buffer.toString());//java.nio.HeapByteBuffer[pos=5 lim=1024 cap=1024]
System.out.println((char) (buffer.get(0)));//H
//数据修改
buffer.put(0, (byte) 'M').put((byte) 'w');
System.out.println(buffer.toString());//java.nio.HeapByteBuffer[pos=6 lim=1024 cap=1024]
System.out.println((char) (buffer.get(0)));//M
//flip将position归0,将一个待填充状态的缓冲区翻转成准备读出状态
System.out.println(buffer);//java.nio.HeapByteBuffer[pos=6 lim=1024 cap=1024]
buffer.flip();
//buffer.rewind();//类似flip,但是不影响limit属性。java.nio.HeapByteBuffer[pos=0 lim=1024 cap=1024]
System.out.println(buffer);//java.nio.HeapByteBuffer[pos=0 lim=6 cap=1024]
//使用hasRemaining()判断是否达到缓冲区上界
while (buffer.hasRemaining()) {
System.out.print((char) (buffer.get()));
}//Mellow
System.out.println("");
//压缩,compact丢弃已释放数据,保留未释放数据
buffer.compact();
//mark,在某个位置标记,reset( )函数将位置设为当前的标记值。
// 如果标记值未定义,调 用 reset( )将导致 InvalidMarkException 异常。
// 一些缓冲区函数会抛弃已经设定的标记 (rewind( ),clear( ),以及 flip( )总是抛弃标记)。
buffer.position(2).mark();
<h4 id=9><font color=red size=3 face="微软雅黑">Buffer比较</font></h4>
比较两个缓冲区,ByteBuffer已经实现Comparable接口,源码如下:
```java
public int compareTo(ByteBuffer that) {
int n = this.position() + Math.min(this.remaining(), that.remaining());
for (int i = this.position(), j = that.position(); i < n; i++, j++) {
int cmp = compare(this.get(i), that.get(j));
if (cmp != 0)
return cmp;
}
return this.remaining() - that.remaining();
}
private static int compare(byte x, byte y) {
return Byte.compare(x, y);
}
Buffer批量移动
```java //批量取 byte[] myArray = new byte[1000]; buffer.get(myArray); //等价于: buffer.get(myArray, 0, myArray.length); //批量存
byte[] myString = new byte[1000];
buffer.put(myString);
//等价于:
buffer.put(myString,0,myString.length);
<h4 id=11><font color=red size=3 face="微软雅黑"> 复制缓冲区</font></h4>
使用duplicate()函数可以复制缓冲区,会创建一个新的buffer对象,但并不会复制数据,原始缓冲区和副本都会操作同样的数据元素。
<h4 id=12><font color=red size=3 face="微软雅黑"> 字节缓冲区</font></h4>
所有的基本数据类型都有相应的缓冲区类(布尔除外),字节类型比较特殊,字节是操作系统和其IO设备使用的基本类型。
非字节类型的基本类型,也是由字节组合成的,比如char2个字节,int4个字节,double8个字节。组合的字节是有顺序的,Java默认的字节顺序是大端字节顺序,参见类ByteOreder。
<h4 id=13><font color=red size=3 face="微软雅黑"> 直接缓冲区</font></h4>
字节缓冲区可以成为通道所执行IO的源头或目标,非字节缓冲区传递给通道,会隐含执行复制内容到一个临时ByteBuffer,所以直接缓冲区是IO的最佳选择。
通过isDirect()函数,判定缓冲区是否为直接缓冲区。
<h4 id=14><font color=red size=3 face="微软雅黑"> 其他缓冲区</font></h4>
视图缓冲区,这种视图对象维持它自己的属性、容量、位置、上界和标记,但是和原来缓冲区共享数据元素。
`CharBuffer charBuffer = byteBuffer.asCharBuffer( );`
ByteBuffer类为每一种原始数据类型提供了存取和转化的方法,比如getInt()函数被调用,从当前位置开始的4个字节会被包装成一个int类型变量返回。
对于无符号数据,自行实现,注意精度问题。
-------
以上来自天团运营总监:[坤少](http://www.cnblogs.com/lknny/)
许多年前 你有一双清澈的双眼
想看遍这世界 去最遥远的远方
感觉有双翅膀 能飞越高山和海洋
