
当大型集团内部、如总公司和子公司之间需要进行数据交换、采集时,其中总公司是Hive数据源,两个NameNode,30个DataNode的高可用集群,子公司一般是Mysql数据源,总公司与各个子公司之间都是网络隔离的。
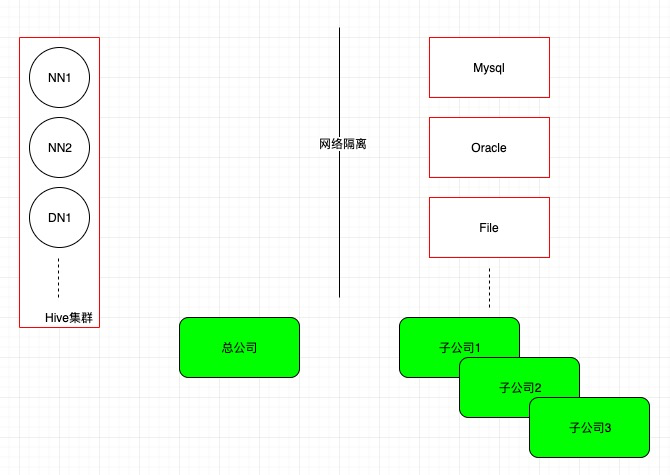
现在我们首先考虑的业务场景是总公司对各个子公司进行数据采集,也就是子公司将mysql上的数据同步到总公司的hive数仓内。
如果在子公司服务器使用阿里的Datax工具插件进行同步,需要将Hive集群的各个节点(32台服务器)的Hive端口都开放给子公司的服务器,这样做有将有两个问题:
1、安全问题,过多端口开放导致的安全隐患增大
2、维护成本,给每家子公司都需要开放这么多的端口,就算子公司只有一台服务器需要连通,那么100家子公司就需要开放100*32个端口
第一种方案,使用Netty进行跨网络数据传输,只需要开放netty-client到netty-server的一个用于tcp连接的端口,然后netty-server将数据写入kafka进行削峰
第二种方案,使用Flume进行数据采集,双层flume架构设计:memory channel + kafka channel
具体实现细节后续补充~
方案设计的最重要的三个问题:
1、维护成本
2、性能
3、高可用
个人倾向第二种方案,因为可以采用开源组件封装下即可,若使用第一种的,需要定制化开发的东西过多,虽然小伙伴很给力,但是人的精力有限,还是做一些更有回报性的事情吧。
一个架构设计的原则:越简单,则越好!
