

https://github.com/huabei-li/personal-project
-
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 400 | 720 |
| Development | 开发 | 200 | 300 |
| · Analysis | · 需求分析 (包括学习新技术) | 150 | 200 |
| · Design Spec | · 生成设计文档 | 30 | 20 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 10 |
| · Design | · 具体设计 | 50 | 60 |
| · Coding | · 具体编码 | 300 | 400 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 120 |
| Reporting | 报告 | 60 | 90 |
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| | 合计 |1385 |2070
-
功能要求参见作业要求博客
-
解题思路
作业要求实现对文本文件中的单词词频做出统计,拿到题的时候先想到了以前做过的对句子单词统计,对文件单词统计的差异在于文件存在多个行。但是也可以想作对文件中的多个行进行统计。在代码中体现为countWord1()将文件的每一行送入countWord2(),countWord2进行单词的判断和数量的统计,同时将单词信息存入unordered_map里,便于topten()函数的字数统计。topten()函数利用了百度的对value值排序的方法,并输出了出现频率前十的单词。countChar_Line()用于统计字符和行数。这是大致的思路。
-
实现过程
逻辑结构如图所示
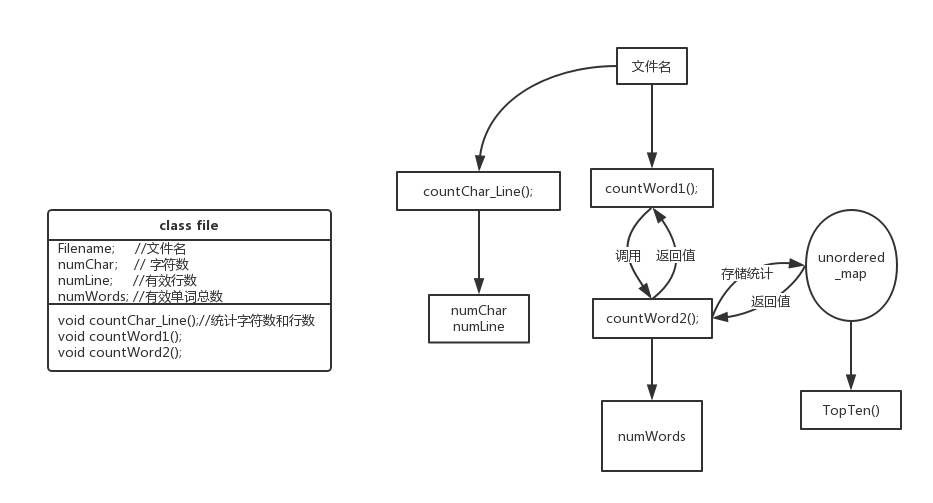
关于接口。如果按照以前的习惯,基本上都是讲所有的功能都写在一起,显得代码很乱。将主要功能都独立成函数,把操作对象相似的函数都放在一个类里,条理和逻辑都比较直观。没有把统计输出的语句集成函数,是受到C++老师的影响(如果函数有输出会带来调试的负担,特别在合作开发时)。
创建了class file,将对文件统计的一些信息,功能都集合在一起,便于理清结构。
-
关键代码
部分主要函数代码
countWord1() 对文件读行操作
void countWord1()
{
string File, temp;
fstream file(fname);
while (getline(file, File))
{
File.append(temp);
temp.clear();
for (int i = 0; i < File.length(); i++)
{
if (File[i] == '\n')
File[i] = ' ';
if (ispunct(File[i]))
File[i] = ' ';
}
stringstream ss(File);
countWord2(ss);
}
}
countWord2() 判断单词,统计数量,存入unordered_map
void countWord2(stringstream &ss)
{
string stemp;
while (ss >> stemp)
{
for (int i = 0; i < stemp.length(); i++)
{
if ('A' < stemp[i] && stemp[i] < 'Z')
stemp[i] += 32;
}
if (stemp.length() < 4)
{
continue;
}
if ((stemp[0]>'z' || stemp[0]<'a' || stemp[1]>'z' || stemp[1]<'a' || stemp[2]>'z' || stemp[2]<'a' || stemp[3]>'z' || stemp[3]<'a'))
{
continue;
}
numWords++;
unordered_map<string, int>::iterator it = My.find(stemp);
if (it == My.end())
{
My.insert(unordered_map<string, int>::value_type(stemp, 1));
}
else
My[stemp]++;
}
}
topTen() 按照value排序输出前十单词(啪啪打脸,函数有输出是觉得功能比较统一)
(更新)最近的更新把输出给挪出去了
void topTen()
{
vector<pair<string, int>> VM;
for (auto it = My.begin(); it != My.end(); it++)
{
VM.push_back(make_pair(it->first, it->second));
}
sort(VM.begin(), VM.end(), [](const pair<string, int> &x, const pair<string, int>&y)->int {return x.second > y.second; });
int c = 0;
for (auto it = VM.begin(); c < 10; it++, c++)
{
cout << it->first << ":" << it->second << endl;
}
}
关于注释,习惯上是对于比较难搞混的变量进行解释,对于比较直观的函数等没有做出太多的说明。个人认为过多的注释会使代码看起来太乱,而且这一次的代码量也不需要太多的注释。因为这一次的代码都是给自己看的,所以看懂就好了,如果是合作完成的话,还是尽量把功能都注释清楚比较好。
-
测试结果
如图

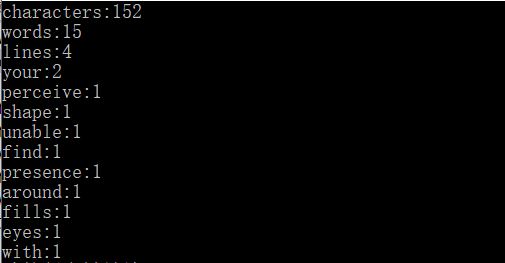
关于测试数据的设计,除了应尽可能地照顾所有的情况,还要考虑对于大文件的测试时间消耗。从网上找了一部原著资源,跑了一下感觉还是比较快的,得益于数据结构方面的选择还是比较合适的,没有走太多弯路。
-
性能分析及改进
利用visual studio 2017 的性能测试工具
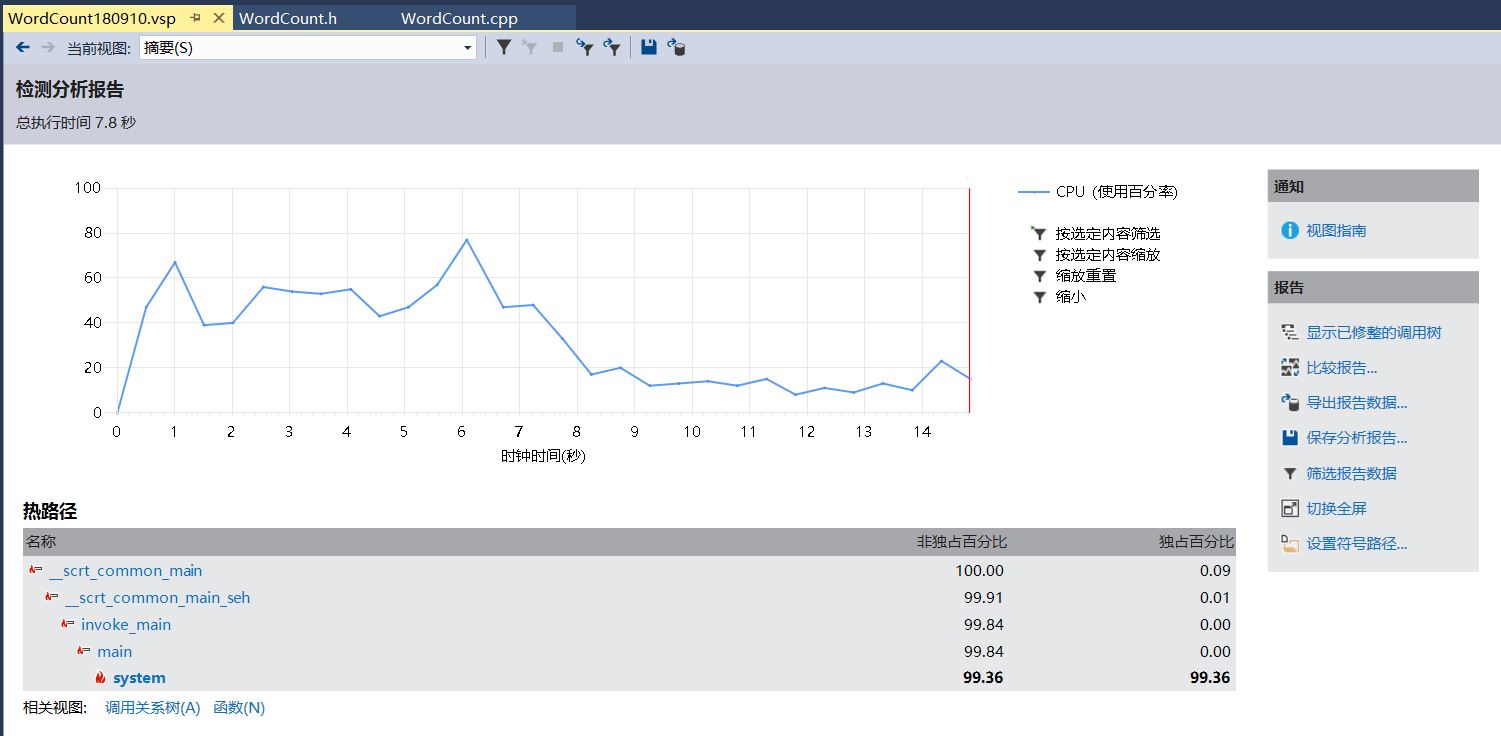

相关信息都在图上了
-
一些问题
关于单元测试:尝试了一下但是没有实现,对这个还是不太清楚还需要进一步的尝试。如果按照我自己的理解,每完成一个特定的功能是要事先测试一下是否能正确完成,每一部件都能正常工作再组合在一起。
关于异常处理:当程序运行时发生了特殊情况,异常处理能够提供转移程序控制权的方式,从网上看了很多资料,尝(xia)试(xie)了一些类似的代码,写了一个最简单的:当文件读取失败时报出异常(我真机智),当文件打开失败时,throw出一个错误提示。
(更新)最大的一个问题!:关于文件的读取真的是犯了一个贼大的错误。按照要求是需要控制台输入文件。当时望文生义是控制台给出路径……也没有百度具体含义,之前也没接触主函数参数,所以就用的是文件路径打开文件,而且全程都用了这个路径……导致现在要想修改正确要大改……真的是无法原谅的错误,导致在最后测试的时候可能写的程序都不能正常运行。尝试是否能在规定时间内修改正确,但是真的来不及,函数的功能结构都要改掉。
-
心得收获

