MySQL系列(三)---索引
MySQL系列(三)---索引
前言:如果有疏忽或理解不当的地方,请指正。有关于数据结构的内容本文没有详细介绍,后续会在数据结构系列进行介绍。
目录
什么是索引
- 如果没有索引,扫描的记录数大于有索引的记录数
- 索引存放索引列的值(比如id为索引列,那么存放索引列的值),和该索引值对应的行在内存中的地址(或者直接存储该行的数据)
- SELECT * FROM user WHERE username= 'jiajun' ,username建立索引,如果索引采用的数据结构是hash表,那么这个时候,通过计算jiajun的hash值,O(1)复杂度就可以找到该记录的位置
hash索引
- 在等值查找下,此时无hash冲突,这种情况下,效率是很高的
- 但是在范围查找下,由于hash不是有序的,那么范围查找下,hash表的优势并不能发挥出来。
- 在hash冲突下,查找效率会降下来
磁盘读取
- 磁盘读取步骤:定柱面,定磁道,定磁块
- 磁盘时间主要消耗在定位柱面,那么如果要提高速度,在数据量一样的情况下,将尽量多的数据放在磁盘块上,那么这样可以减少磁头定位柱面移动的次数,减少IO的次数。
二叉查找树
- 左子树所有的节点的值小于他的根节点的值
- 右子树所有的节点的值大于他的根节点的值
- 任意节点的左子树和右子树都是二叉查找树
- 没有键值相等的节点
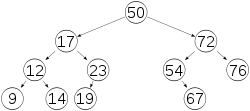
分析
- 二叉查找树的查找的复杂度到了lgn
- 但是有没有办法减少IO的次数,也就是能不能降低树的高度
B-树
(m阶树 m/2<=k<=m)
- 根节点至少两个子节点
- 所有叶子节点都在同一层
- 中间节点包含k-1个元素和k个孩子
- 节点中的元素从小到大排列
- 每个节点即包含索引列的值,和该数据记录(或该数据记录的值)

分析
- 相对于二叉查找树,B树变得矮胖,因为每个节点存放的元素更多,所以相同元素情况下,降低了树的高度,那么就可以减少IO的次数
- 每个节点存放了数据(该行记录的值或者该行记录在内存的地址),所以不同的查询性能是不一样的。
B+树
- 在B-树的基础上
- 除了叶子结点,其他节点不包含记录(数据库中的行)的位置
- 叶子节点包含了所有的索引值,并且从小到大排列,以及记录(数据库中行)的位置
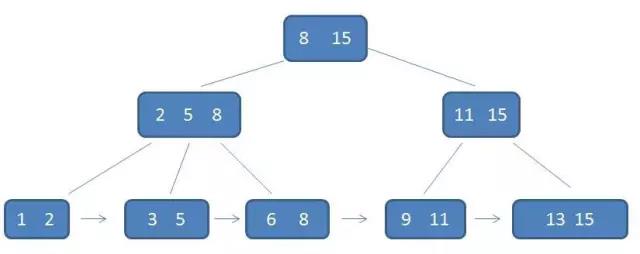
分析
- 如果节点的大小一样,那么如果我们除了叶节点之外,其他节点不包含数据,那么就可以放更多的元素(索引值),这样的话这棵树就变的更加矮胖,那么IO的次数可以进一步减少
- 因为叶节点的元素是顺序排列,而且叶节点间形成链表,那么有序查找时提高范围查询的效率
- 相对于B树,由于所有的数据是存放在叶节点,那么意味着每次查找都必须到从根查找到叶节点,那么这就意味着查询性能平均。
总结
- 索引是一种数据,可以避免了全表查询,可以类比目录和书。
- 索引需要一种数据结构来存储
- 利用散列表(hash)的方式查询复杂度可以到O(1),但是再范围查询时,hash起不了提高性能的作用
- IO操作是耗时,为了提高查询性能,可以减少IO的次数
- 对于树的存储结构来说,为了提高性能,减少IO的次数,可以低树的高度
- 读取一个节点一次IO,在数据量一样的情况下,如果每个节点的能存放更多元素,那么就可以降低树的高度。
- B树降低了树的高度,而在节点大小一样的情况下,因为B树的节点存放了元素有又存放了数据,而B+树将数据全部存放在叶节点,那么这样的话,每个节点可以存放更多的元素,那么就可以再一次降低树的高度
- B+树的查询性能更加稳定,并且更有利于范围查找
- 如果是聚集索引(InnoDB引擎),那么节点存放的该记录的数据,数据文件本身就是索引文件
- 如果是非聚集索引(MyISAM引擎),那么节点存放的是该行记录的地址。索引文件和数据文件是分离
索引的种类
- 普通索引,允许出现相同的内容
- 唯一索引,索引值唯一,允许空值
- 主键索引,创建主键的时候自动创建主键索引,唯一并且不能为空
- 组合索引,多列组合索引
聚集索引和非聚集索引
- 聚集索引指的是索引和数据文件在一起,在InnoDB引擎中,数据文件本身就是索引文件,这个索引的key是主键。InnoDB必须要主键,如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
- 非聚集索引指的是索引文件和数据文件分开。在MyISAM中,B+树中叶节点存放的记录的地址。而在InnoDB中,非主键索引的B+树中存放的是该记录主键值。
索引的使用
- ALTER TABLE table_name ADD INDEX index_name (column_list) 增加普通索引
- ALTER TABLE table_name ADD UNIQUE (column_list) 增加唯一索引
- ALTER TABLE table_name ADD PRIMARY KEY (column_list) 增加主键索引
注意点
- 如果此时为 username,age,sex建联合索引
- 最左匹配指优先匹配最左索引,(username)(username,age)(username,age,sex),只要查询条件用到最左边的列,一般就会使用索引。顺序可以不同,比如(age,username),这是查询优化器的功劳。
- 模糊查询只有%号不在第一个字符,索引才可能被使用,比如username like '%jiajun'所以不被采用
- 如果or中有一个条件没有索引,sql语句不会用到索引,比如usernmae ='jiajun' or pwd='666',此时索引不被采用
- 组合索引中,如果查询条件不是索引的第一列,索引可能不会被采用,比如此时where age =1
- 如果列是字符型,比如username是字符型而且是索引列,如果此是查询username=1 ,没有加引号,那么这个时候也不会用索引
- 可以用 show status like 'Handler_read%' 来查看索引使用情况。
- 建议实践为主
索引原则
- 索引应该设计在where后的列,而不是select后的列
- 索引应该建在区分度大的列,比如状态只有1 和2就没必要建索引了
- 对字符串进行索引的时候,应该制定一个前缀长度,比如一个列为char(200),如果前面几个字符就要较大区分度,那么对前几个字符建立索引就行了,这样减少了占用空间,也提高了速度
- 不要创建太多索引,索引会占空间,而且更新的时候会降低速度,并且如果有过多的索引,Mysql执行计划的时候,会考虑各个索引,这也会浪费时间
哪些列适合索引
- 经常作为查询条件的列
- 经常作为排序条件的列
- 经常作为join条件的列
哪些列不适合索引
- 频繁修改的列,因为数据被修改,索引要相应修改
- 区分度不高的列,比如性别只有两种
- 不是经常作为查询条件,排序条件,连接的列
索引优缺点
- 毫无疑问,在使用正确的情况下,索引能提高查询速度
- 索引也能提高分组和排序的速度
- 由于修改删除添加时,要调维护索引文件,对树进行调整,所以性能降低了
- 索引文件也是需要占用空间的
我觉得分享是一种精神,分享是我的乐趣所在,不是说我觉得我讲得一定是对的,我讲得可能很多是不对的,但是我希望我讲的东西是我人生的体验和思考,是给很多人反思,也许给你一秒钟、半秒钟,哪怕说一句话有点道理,引发自己内心的感触,这就是我最大的价值。(这是我喜欢的一句话,也是我写博客的初衷)
作者:jiajun 出处: http://www.cnblogs.com/-new/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。如果觉得还有帮助的话,可以点一下右下角的【推荐】,希望能够持续的为大家带来好的技术文章!想跟我一起进步么?那就【关注】我吧。
标签:
MySQL系列






【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?